标签:replace tps 解析 def creat pass mail The ret
【datetime】
No1:
获取当前时间
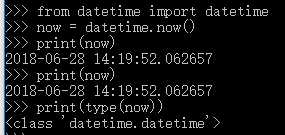
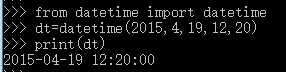
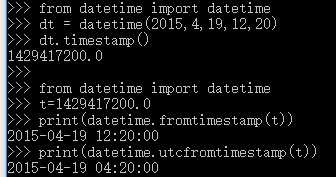
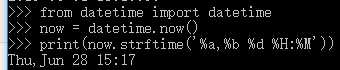
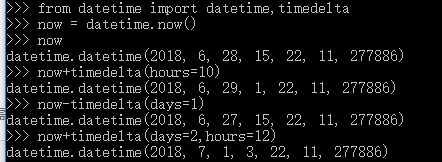
No2:
时区转换
>>> from datetime import datetime, timedelta, timezone >>> tz_utc_8 = timezone(timedelta(hours=8)) # 创建时区UTC+8:00 >>> now = datetime.now() >>> now datetime.datetime(2015, 5, 18, 17, 2, 10, 871012) >>> dt = now.replace(tzinfo=tz_utc_8) # 强制设置为UTC+8:00 >>> dt datetime.datetime(2015, 5, 18, 17, 2, 10, 871012, tzinfo=datetime.timezone(datetime.timedelta(0, 28800)))
# 拿到UTC时间,并强制设置时区为UTC+0:00: >>> utc_dt = datetime.utcnow().replace(tzinfo=timezone.utc) >>> print(utc_dt) 2015-05-18 09:05:12.377316+00:00 # astimezone()将转换时区为北京时间: >>> bj_dt = utc_dt.astimezone(timezone(timedelta(hours=8))) >>> print(bj_dt) 2015-05-18 17:05:12.377316+08:00 # astimezone()将转换时区为东京时间: >>> tokyo_dt = utc_dt.astimezone(timezone(timedelta(hours=9))) >>> print(tokyo_dt) 2015-05-18 18:05:12.377316+09:00 # astimezone()将bj_dt转换时区为东京时间: >>> tokyo_dt2 = bj_dt.astimezone(timezone(timedelta(hours=9))) >>> print(tokyo_dt2) 2015-05-18 18:05:12.377316+09:00
【collections】
No3:
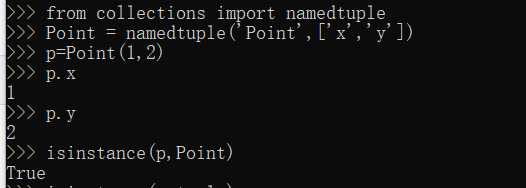

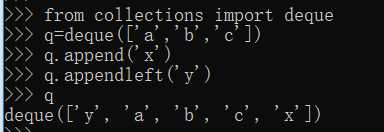
No4:
deque方便插入和删除
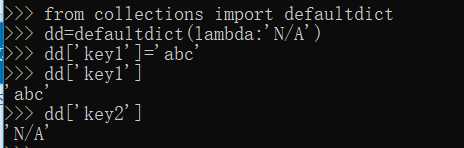
OrderedDict有序
>>> from collections import OrderedDict >>> d = dict([(‘a‘, 1), (‘b‘, 2), (‘c‘, 3)]) >>> d # dict的Key是无序的 {‘a‘: 1, ‘c‘: 3, ‘b‘: 2} >>> od = OrderedDict([(‘a‘, 1), (‘b‘, 2), (‘c‘, 3)]) >>> od # OrderedDict的Key是有序的 OrderedDict([(‘a‘, 1), (‘b‘, 2), (‘c‘, 3)])
>>> od = OrderedDict() >>> od[‘z‘] = 1 >>> od[‘y‘] = 2 >>> od[‘x‘] = 3 >>> list(od.keys()) # 按照插入的Key的顺序返回 [‘z‘, ‘y‘, ‘x‘]
FIFO(先进先出)的dict
from collections import OrderedDict class LastUpdatedOrderedDict(OrderedDict): def __init__(self, capacity): super(LastUpdatedOrderedDict, self).__init__() self._capacity = capacity def __setitem__(self, key, value): containsKey = 1 if key in self else 0 if len(self) - containsKey >= self._capacity: last = self.popitem(last=False) print(‘remove:‘, last) if containsKey: del self[key] print(‘set:‘, (key, value)) else: print(‘add:‘, (key, value)) OrderedDict.__setitem__(self, key, value)
Counter计数器
>>> from collections import Counter >>> c = Counter() >>> for ch in ‘programming‘: ... c[ch] = c[ch] + 1 ... >>> c Counter({‘g‘: 2, ‘m‘: 2, ‘r‘: 2, ‘a‘: 1, ‘i‘: 1, ‘o‘: 1, ‘n‘: 1, ‘p‘: 1})
【base64】
No5:
Base64是一种用64个字符来表示任意二进制数据的方法。
>>> import base64 >>> base64.b64encode(b‘binary\x00string‘) b‘YmluYXJ5AHN0cmluZw==‘ >>> base64.b64decode(b‘YmluYXJ5AHN0cmluZw==‘) b‘binary\x00string‘
>>> base64.b64encode(b‘i\xb7\x1d\xfb\xef\xff‘) b‘abcd++//‘ >>> base64.urlsafe_b64encode(b‘i\xb7\x1d\xfb\xef\xff‘) b‘abcd--__‘ >>> base64.urlsafe_b64decode(‘abcd--__‘) b‘i\xb7\x1d\xfb\xef\xff‘
No6:
【struct】
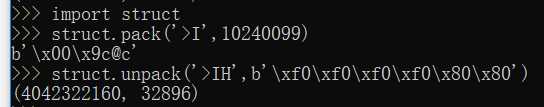
pack的第一个参数是处理指令,‘>I‘的意思是:
>表示字节顺序是big-endian,也就是网络序,I表示4字节无符号整数。
【摘要算法】
No7:
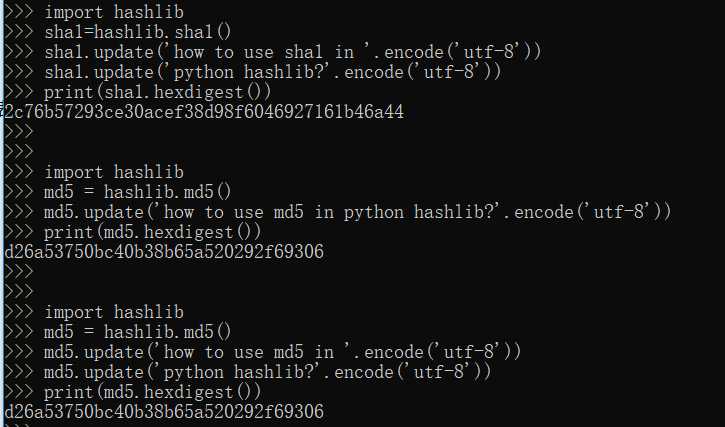
摘要算法又称哈希算法、散列算法。它通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用16进制的字符串表示)
No8:
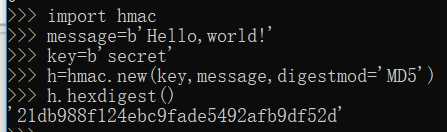
【hmac】
No9:
【itertools】迭代
count()
>>> import itertools >>> natuals = itertools.count(1) >>> for n in natuals: ... print(n) ...
数字无限增长,差点没爆掉
cycle()
>>> import itertools >>> cs = itertools.cycle(‘ABC‘) # 注意字符串也是序列的一种 >>> for c in cs: ... print(c) ...
ABC无限重复,又差点没爆掉
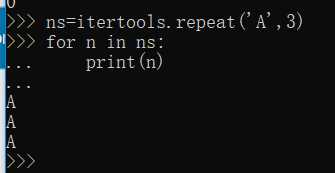
repeat()--限定重复次数

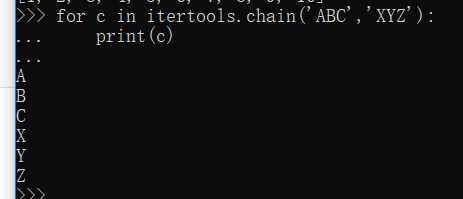
chain()--可以把一组迭代对象串联起来,形成一个更大的迭代器:
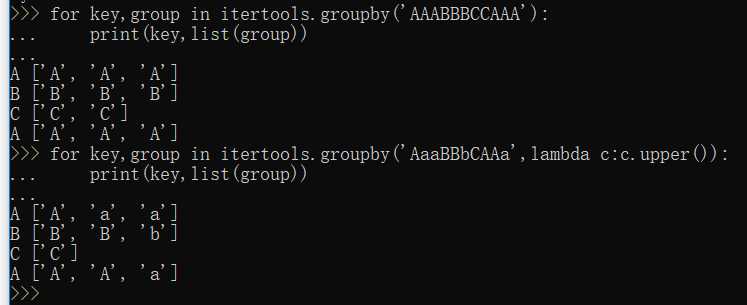
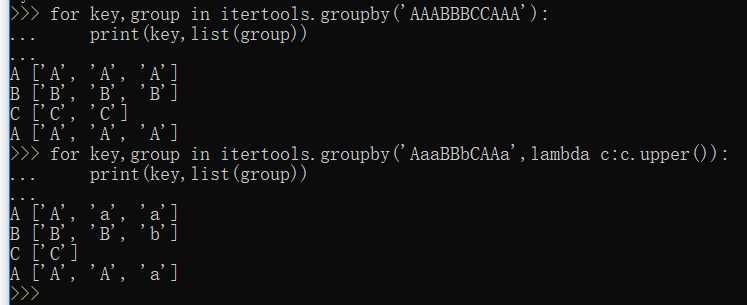
groupby()--把迭代器中相邻的重复元素挑出来放在一起:
No10:
try: f = open(‘/path/to/file‘, ‘r‘) f.read() finally: if f: f.close()
可简化为
with open(‘/path/to/file‘, ‘r‘) as f: f.read()
No11:
class Query(object): def __init__(self, name): self.name = name def __enter__(self): print(‘Begin‘) return self def __exit__(self, exc_type, exc_value, traceback): if exc_type: print(‘Error‘) else: print(‘End‘) def query(self): print(‘Query info about %s...‘ % self.name)
使用
with Query(‘Bob‘) as q: q.query()
》》》》类可简化为
from contextlib import contextmanager class Query(object): def __init__(self, name): self.name = name def query(self): print(‘Query info about %s...‘ % self.name) @contextmanager def create_query(name): print(‘Begin‘) q = Query(name) yield q print(‘End‘)
使用
with create_query(‘Bob‘) as q: q.query()
No12:
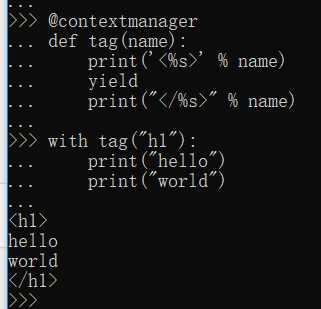
No13:
from contextlib import closing from urllib.request import urlopen with closing(urlopen(‘https://www.python.org‘)) as page: for line in page: print(line)
结果居然打印出整个html界面的代码
【GET】
No14:
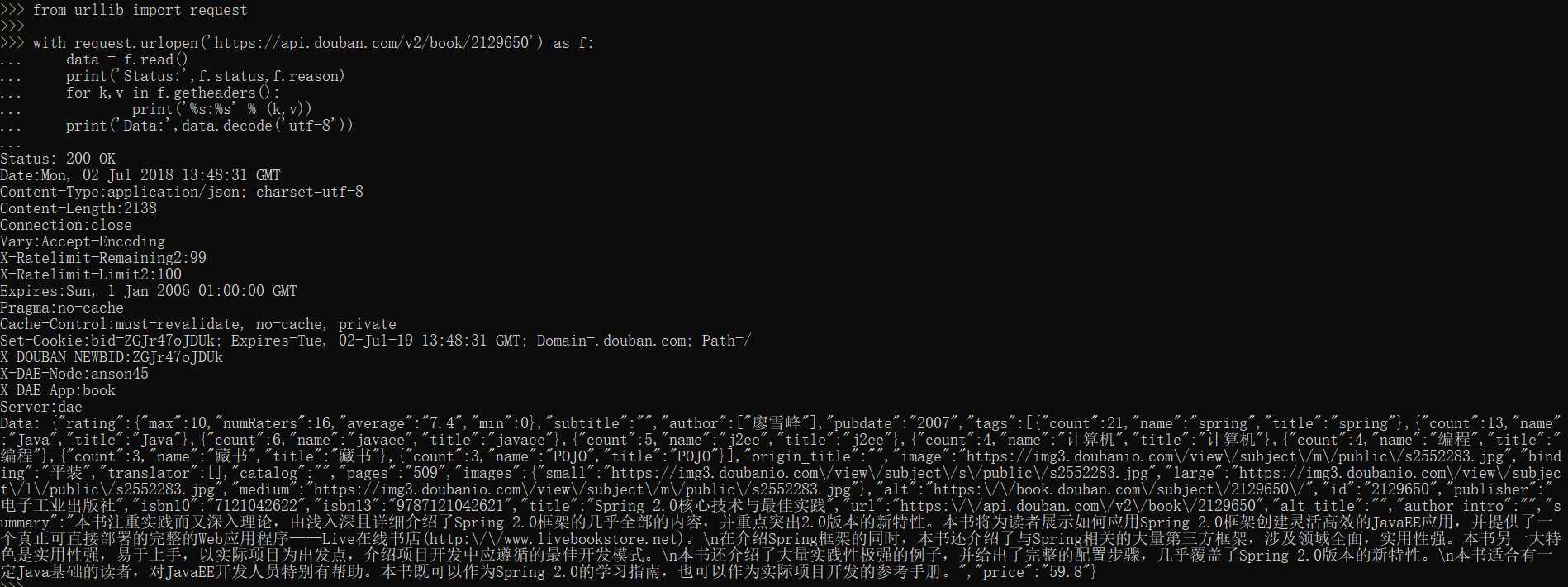
from urllib import request req = request.Request(‘http://www.douban.com/‘) req.add_header(‘User-Agent‘, ‘Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25‘) with request.urlopen(req) as f: print(‘Status:‘, f.status, f.reason) for k, v in f.getheaders(): print(‘%s: %s‘ % (k, v)) print(‘Data:‘, f.read().decode(‘utf-8‘))
结果会返回豆瓣网的移动端页面
No15:
【POST】
模拟微博登陆
from urllib import request, parse print(‘Login to weibo.cn...‘) email = input(‘Email: ‘) passwd = input(‘Password: ‘) login_data = parse.urlencode([ (‘username‘, email), (‘password‘, passwd), (‘entry‘, ‘mweibo‘), (‘client_id‘, ‘‘), (‘savestate‘, ‘1‘), (‘ec‘, ‘‘), (‘pagerefer‘, ‘https://passport.weibo.cn/signin/welcome?entry=mweibo&r=http%3A%2F%2Fm.weibo.cn%2F‘) ]) req = request.Request(‘https://passport.weibo.cn/sso/login‘) req.add_header(‘Origin‘, ‘https://passport.weibo.cn‘) req.add_header(‘User-Agent‘, ‘Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25‘) req.add_header(‘Referer‘, ‘https://passport.weibo.cn/signin/login?entry=mweibo&res=wel&wm=3349&r=http%3A%2F%2Fm.weibo.cn%2F‘) with request.urlopen(req, data=login_data.encode(‘utf-8‘)) as f: print(‘Status:‘, f.status, f.reason) for k, v in f.getheaders(): print(‘%s: %s‘ % (k, v)) print(‘Data:‘, f.read().decode(‘utf-8‘))
No16:
【Handler】
proxy_handler = urllib.request.ProxyHandler({‘http‘: ‘http://www.example.com:3128/‘})
proxy_auth_handler = urllib.request.ProxyBasicAuthHandler()
proxy_auth_handler.add_password(‘realm‘, ‘host‘, ‘username‘, ‘password‘)
opener = urllib.request.build_opener(proxy_handler, proxy_auth_handler)
with opener.open(‘http://www.example.com/login.html‘) as f:
pass
No17:
【XML】
操作XML有两种方法:DOM和SAX。DOM会把整个XML读入内存,解析为树,因此占用内存大,解析慢,优点是可以任意遍历树的节点。SAX是流模式,边读边解析,占用内存小,解析快,缺点是我们需要自己处理事件。
正常情况下,优先考虑SAX,因为DOM实在太占内存。
from xml.parsers.expat import ParserCreate class DefaultSaxHandler(object): def start_element(self, name, attrs): print(‘sax:start_element: %s, attrs: %s‘ % (name, str(attrs))) def end_element(self, name): print(‘sax:end_element: %s‘ % name) def char_data(self, text): print(‘sax:char_data: %s‘ % text) xml = r‘‘‘<?xml version="1.0"?> <ol> <li><a href="/python">Python</a></li> <li><a href="/ruby">Ruby</a></li> </ol> ‘‘‘ handler = DefaultSaxHandler() parser = ParserCreate() parser.StartElementHandler = handler.start_element parser.EndElementHandler = handler.end_element parser.CharacterDataHandler = handler.char_data parser.Parse(xml)
L = [] L.append(r‘<?xml version="1.0"?>‘) L.append(r‘<root>‘) L.append(encode(‘some & data‘)) L.append(r‘</root>‘) return ‘‘.join(L)
No18:
【HTMLParser】
from html.parser import HTMLParser from html.entities import name2codepoint class MyHTMLParser(HTMLParser): def handle_starttag(self, tag, attrs): print(‘<%s>‘ % tag) def handle_endtag(self, tag): print(‘</%s>‘ % tag) def handle_startendtag(self, tag, attrs): print(‘<%s/>‘ % tag) def handle_data(self, data): print(data) def handle_comment(self, data): print(‘<!--‘, data, ‘-->‘) def handle_entityref(self, name): print(‘&%s;‘ % name) def handle_charref(self, name): print(‘&#%s;‘ % name) parser = MyHTMLParser() parser.feed(‘‘‘<html> <head></head> <body> <!-- test html parser --> <p>Some <a href=\"#\">html</a> HTML tutorial...<br>END</p> </body></html>‘‘‘)
标签:replace tps 解析 def creat pass mail The ret
原文地址:https://www.cnblogs.com/anni-qianqian/p/9239668.html