标签:区别 each title contains type article 代码 array string
基础知识:
什么是集合?
集合是一个容器。把多个对象放入容器中。有一个水杯,你可以选择把水不断往里装,也可以选择装牛奶。但是不能两种不同的东西混合装一个杯子。集合这个容器里装的一定是同一类型的东西。(引用类型,不能是基本类型)
看到这个介绍,我们可能想到数组,数组要求的也是里面必须存放的是一种数据类型的结构。
但数组和集合的区别呢?
数组大小是固定的,集合的大小理论上是不限定。
数组里的元素可以是基本类型,也可以是引用类型。集合只能放引用类型。
下图是集合家族的主要成员们(图来自百度)
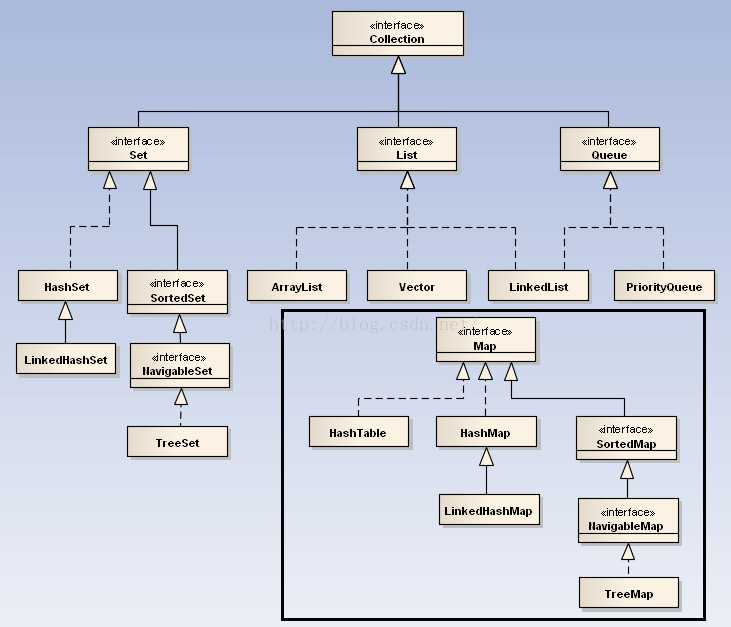
由图可见,Collection接口和Map接口是两个老大。Collection接口下面又生出来了Set接口(无序),List接口(有序),queue接口。Map接口保存的是有映射关系的数据。Map里的子类都有一个共同的特征就是里面数据都是key-value.举例,语文-80,数学-78,科目是不能重复的,分数是可以重复的,所以,Map里的key不能重复,value可重复。需要查分数(value),就通过科目(Key)来取。
具体实现类,常用的有ArrayList、LinkedList、HashSet、LinkedHashSet、HashMap、LinkedHashMap等等,主要分为以下三类
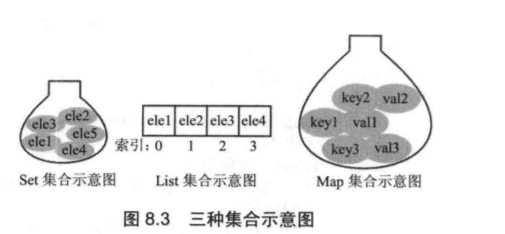
从上图可知,Set集合是无序的,只能根据集合里的元素本身访问。
List集合是有序的,可以通过索引访问。
Map集合可通过每个元素的Key访问value.
下面列出了Collection接口下方法
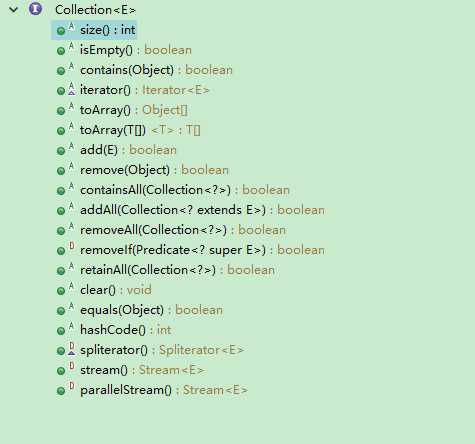
大概看一眼,这些方法无非就是添加对象,移除对象,判断集合是不是空,清空容器,所以无需记忆。
有方法值的一提的是 当你需要把集合元素转成数组元素时候用Object[] toArray() ,有个陷阱:注意注释部分,数组不能直接(String[])这样强制将数组变量转换,只有在使用使将元素转换为String,
首先看下List的这两个方法的说明:
Object[ ] toArray() :返回按适当顺序包含列表中的所有元素的数组(从第一个元素到最后一个元素)。
<T> T[ ] toArray(T[] a) :返回按适当顺序(从第一个元素到最后一个元素)包含列表中所有元素的数组;返回数组的运行时类型是指定数组的运行时类型
Collection<String> arr = new ArrayList<String>(); arr.add("a"); arr.add("b"); arr.add("b");//可以添加重复的对象 // String[] str = (String[])arr.toArray();//error
Object[] obj = arr.toArray();//第一种方法
String[] obj1 = arr.toArray(new String[3]);//第二种方法
Db.query()第二个是多个不确定的参数,多个参数可以被作为数组传进来。List集合转数组举例
/** * 封装预处理参数解析并执行查询 * @param sqlId * @param param * @return */ public <T> List<T> query(String sqlId, Map<String, Object> param){ LinkedList<Object> paramValue = new LinkedList<Object>(); String sql = getSqlByBeetl(sqlId, param, paramValue); return Db.query(sql, paramValue.toArray()); }
补充下getSqlByBeetl如果要sql里需要Map的话,如下参考:
/** * 验证编码是否存在 * @param operatorid * @param type * @return boolean * 描述:新增角色组时operatorid为空,修改角色组时operatorid传值 */ public boolean valiQbgjxwcqkxxno(String qbgjxwcqkxxno, String type){ Map<String, Object> param = new HashMap<String, Object>(); param.put("column", Jxwc.column_qbggyzfqkxxno); param.put("table", Jxwc.table_name); String sql = getSqlByBeetl(Jxwc.sqlId_select, param); List<Jxwc> list = Jxwc.dao.find(sql,qbgjxwcqkxxno); int size = list.size(); if("add".equals(type)){ if(size == 0){ return true; } }else{ if(size <= 1){ return true; } } return false; }
看集合主要成员图可知Itertor接口不在图上,但是他也是集合框架的成员,但是它与Map集合系列,C
ollection集合系列不同,它主要装的是遍历Collection集合里的元素。Itertor对象也叫迭代器,依托Collection对象存在。提供遍历Collection的统一编程接口。
主要的方法:
boolean hasNext() 要是被遍历的集合还没遍历完,就返回true
Object next() 返回集合里的下一个元素
void remove() 删除上一次next()返回的元素
package Test01; import java.util.Collection; import java.util.HashSet; import java.util.Iterator; public class Test { public static void main(String[] args) { Collection arr = new HashSet<>(); arr.add("a"); arr.add("b"); arr.add("C");//可以添加重复的对象 Iterator iterator =arr.iterator(); while(iterator.hasNext()) { String next = (String) iterator.next(); System.out.println(next); if(next.equals("C")) { iterator.remove(); } next ="修改迭代变量的值看看有没影响"; //注意下 } System.out.println(arr.toString()); } }
运行完发现“注意下”的地方本想改变集合里的元素却没变。所以可得到:Iterator并不是得到集合本身的元素,而是得到元素的值而已,所以修改迭代变量的值并不会影响集合本身。
Iterator不像其他集合,没有承装对象的能力。如果他不依托集合存在,根本没存在的价值。
想删除集合元素,必须通过Iterator的remove() 删除上一次next()返回的元素,不能集合自己remove(Object)
举例,会发现异常
package Test01; import java.util.Collection; import java.util.HashSet; import java.util.Iterator; public class Test { public static void main(String[] args) { Collection arr = new HashSet<>(); arr.add("a"); arr.add("b"); arr.add("C");//可以添加重复的对象 Iterator iterator =arr.iterator(); while(iterator.hasNext()) { String next = (String) iterator.next(); System.out.println(next); if(next.equals("b")) { arr.remove(next); } next ="修改迭代变量的值看看有没影响"; } System.out.println(arr.toString()); } }
异常原因是 迭代器采用快速-失败原则(fast-fail),一旦迭代过程中发现Collection集合中元素被修改,就引发异常。偶尔发现,如果刚刚代码改成
if(next.equals("C")) { arr.remove(next); }
也不会异常,----只有删除特定元素才会这样,但是不该冒险去做。
foreach也能迭代访问集合,但是注意,他得到的也不是集合元素本身,系统只是把集合元素的值赋给迭代变量而已,也同样同上会引发Java ConcurrentModificationException异常。
如下代码(错误示范)
package Test01; import java.util.Collection; import java.util.HashSet; import java.util.Iterator; public class Test { public static void main(String[] args) { Collection arr = new HashSet<>(); arr.add("a"); arr.add("b"); arr.add("C");//可以添加重复的对象 for(Object a:arr) { if(a.equals("b")) { arr.remove(a); } } } }
就像把对象随意扔进罐子里,无法记住元素的添加顺序。Set某种程度就是Collection,方法没有不同,只是行为稍微不同,(不允许重复元素),如果一定要往里加两个相同元素,添加失败add()返回false;
上面的Set的一些共同点,Hashset,TreeSet,EunmSet三个实现类还各有特色。
依次介绍下
判断Hashset 集合里的两个对象相等,过两关,equal()比较相等,对象的hashcode()也相等
为什么还得比较对象的hashcode()?
Hashset 集合收进一个对象时,会调用对象的hashcode()得到其Hashcode值来决定他的存储位置。所以,即使是equal()比较相等的两个对象,hashcode不同,存放在hashset里的位置不同,依然能把这两个对象添加成功。
注意:把对象装进hashset时,如果要重写equals方法,也得重写hashcode 方法,因为equals()相等的两对象hashcode 也是相同的。
提问:hashcode()对hashset是很重要的吗?
答:hash算法是快速查找被检索的对象。通过对象的hashcode定位集合里的对象的存储位置。定位该元素。对比下,数组是存储一组元素最快的数组结构,数组通过索引找到它的组员,通过索引能计算元素在内存里的存储位置。
但是为嘛有了数组,还用hashset呢?数组也有局限性,索引是连续的,而且长度不可变。
hashset有了hashcode,所以能快速定位对象位置,而且任意增加对象。
重写hashcode() 注意java.lang.Object中对hashCode的约定:
两个对象通过equals()比较相等时,他们的hashcode 也应该是一样的。
程序运行过程中,同一个对象多次调用hashcode方法返回应该是一样的。
如果根据 equals(java.lang.Object) 方法,两个对象不相等,那么在两个对象中的任一对象上调用 hashCode 方法不一定会生成不同的整数结果。但是,为不相等的对象生成不同整数结果可以提高哈希表的性能。 实际上,由 Object 类定义的 hashCode 方法确实会针对不同的对象返回不同的整数。
向hashset里添加了一个可变对象后时,要注意:如果后面的程序修改了这个可变对象的实例变量时,可能会导致他与集合里的其他元素相同,即两个对象equals返回true,hashcode也相同。导致hashSet不能正确操作那些元素。
补充了解下,可变对象:创建后,对象的属性值可能会变,也就是说,创建后对象的hash值可能会改变。
举例:对象MutableKey的键在创建时变量 i=10 j=20,哈希值是1291。然后我们改变实例的变量值,该对象的键 i 和 j 从10和20分别改变成30和40。现在Key的哈希值已经变成1931。显然,这个对象的键在创建后发生了改变。所以类MutableKey是可变的。
下面代码是hashset里添加了一个可变对象例子,
可看出,hashset已经添加了几个成员后,修改一个成员的实例变量,会得到里面有相同的成员,因此是不对的。
但是,对最后一行,不能准确访问成员这个。有点疑问,待解决。
package Test01; import java.util.HashSet; import java.util.Iterator; class mutClass{ public int count; public mutClass(int count) { this.count =count; } public boolean equals(Object obj) { if(this == obj) { return true; } if(obj != null && obj.getClass() == mutClass.class) { mutClass m =(mutClass) obj; return this.count == m.count; } return false; } public int hashcode() { return this.count; } public String toString() { return "试试mutClass[count=" + count + "]"; } } public class TestHashSet { @SuppressWarnings("unchecked") public static void main(String[] args){ HashSet testHashSet =new HashSet(); mutClass a = new mutClass(3); mutClass b = new mutClass(1); mutClass c = new mutClass(-9); mutClass d = new mutClass(9); testHashSet.add(a); testHashSet.add(b); testHashSet.add(c); testHashSet.add(d); System.out.println("第一次"+testHashSet); Iterator iterator =testHashSet.iterator(); mutClass first = (mutClass) iterator.next(); first.count=9; /* testHashSet.remove(new mutClass(3)); testHashSet.remove(b); //与上一行的区别 */ System.out.println("第二次"+testHashSet); System.out.println(new mutClass(-9) == new mutClass(-9)); System.out.println("第四次"+testHashSet.contains(new mutClass(-9))); } }
hashset不能保证添加成员的顺序,和自己的顺序是一样的,但是引入了一个LinkedHashSet子类,使得它能和hashset一样,靠hashcode 找到他的存储位置,又能维护添加成员的顺序,内部靠一个链表实现,迭代访问集合时有很好的性能。
标签:区别 each title contains type article 代码 array string
原文地址:https://www.cnblogs.com/yizhizhangBlog/p/9251219.html