标签:har include print inf 先来 src 说明 str 对齐
结构体之间的对齐是有很多种方法的,也是根据你所用的系统位数有关。下面都是以32位系统来讲的,32位系统一般以字对齐,字就是系统位数,32位系统则是32位对齐,也就是4字节(int型)对齐。
讲程序前我还是先来说下为什么要对齐(面试时也问了下这个问题)?说到底还是为了效率,为了cpu的工作效率。举个例子:一个unsigned short (2字节)类型的变量以下面两种方式存储。
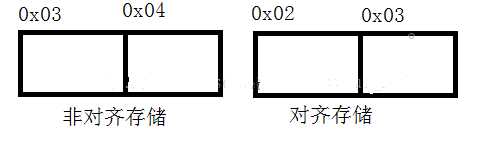
非对齐存储:CPU在读取(说明下32位系统有32根地址线,所以CPU每次都读取32位也就是4个字节的数据)数据时,首先读取0x00地址到0x03地址上的4个字节数据,然后分析只有0x03地址上的数据才是CPU想要的,所以保留这个字节的数据。接着读取0x04地址到0x07地址内的4个字节数据,分析可的只有0x04地址上的数据才是CPU想要的,所以保留下。最后把在0x03地址上读取到的数据和在0x04地址上读取到的数据合起来才能得到CPU想要读取的那个unsigned short型数据。
对齐存储:CPU直接读取0x00地址到0x03地址上的4个字节数据,然后分析,保留0x02地址和0x03地址上的2个字节数据,就可以得到CPU想要读取的那个unsigned short型数据。
这样一比较我想大家都能看出来对齐存储对CPU工作效率来说是非常关键的。所以系统默认都设置字对齐,以方便CPU工作。如果是非字对齐(人为的用强转为地址赋值)有的编译器没问题,但有的编译器会直接报错。
下面来看程序,如果当结构体成员中有char型,int型,short型等数据类型时,系统是怎么分配存储地址的。
#include<stdio.h>
typedef struct test
{
char C1;
int I1;
short ST1;
char C2;
int I2;
char C3;
short ST2;
}T;
int main()
{
T t;
printf("C1: %p\n", &t.C1);
printf("I1: %p\n", &t.I1);
printf("ST1: %p\n", &t.ST1);
printf("C2: %p\n", &t.C2);
printf("I2: %p\n", &t.I2);
printf("C3: %p\n", &t.C3);
printf("ST2: %p\n", &t.ST2);
printf("sizeof(T):%d\n", sizeof(T));
return 0;
}
标签:har include print inf 先来 src 说明 str 对齐
原文地址:https://www.cnblogs.com/sunbines/p/9257981.html