标签:pycha 现在 系统 管理 三方 搭建 功能 记不清 下载地址
最近在研究python爬虫的相关内容。一点一点来吧,由浅入深,稍微后面一点会搞搞分布式爬虫框架scrapy + MongoDB,现在先做一些requests + bs4的简单爬虫,稍后一点会将数据存放到数据库,这里先预定使用 myssql,而且爬取的基本是一些没有任何反扒机制的网站。
关于静态网页和动态网页的区别,以后也会介绍的,现在已经11点多了,起个头,洗洗睡了。
首先介绍下环境搭建。
我这里用的是win10系统,最最简单快捷的方法,真的是一个软件就解决的事,不需要下载python,不需要配置环境变量,不需要下载pycharm!
那就是anaconda。它不仅包含了python开发所需要的环境,而且是一个方便快捷的python第三方包安装管理工具,比pip要方便的多,虽然pip和pycharm都可以安装第三方模块。
这里是官网下载地址:https://www.anaconda.com/download/
根据自己的电脑和想要使用的python版本,下载相应的版本,一步步安装即可,只有一点需要注意的,安装过程中,记不清具体是什么,大概是 just for me/ for everyone, 这里要选择 for everyone,然后一步步next。
这里放一张软件截图给大家,让大家先感受下 anaconda 的方便之处。
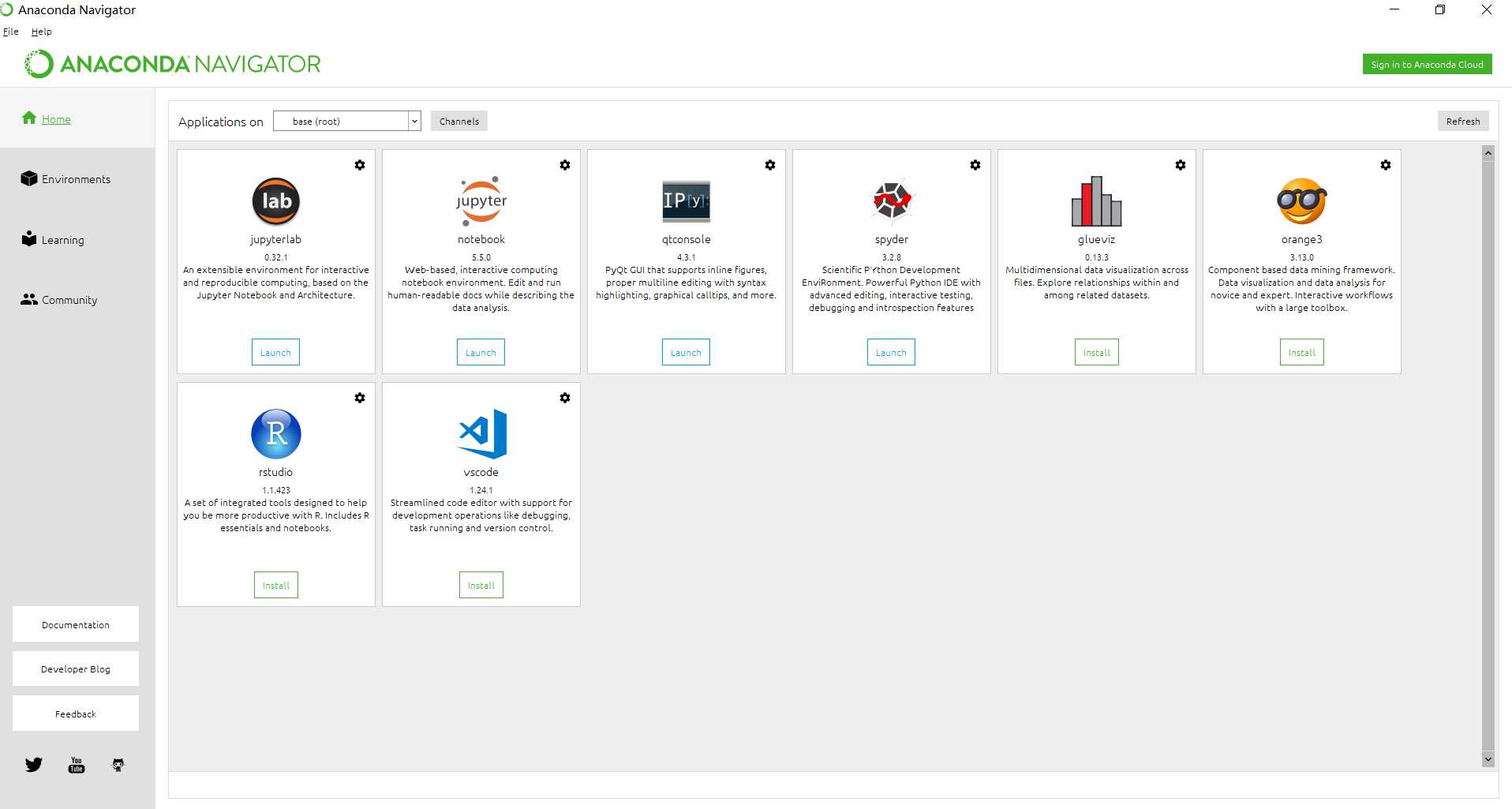
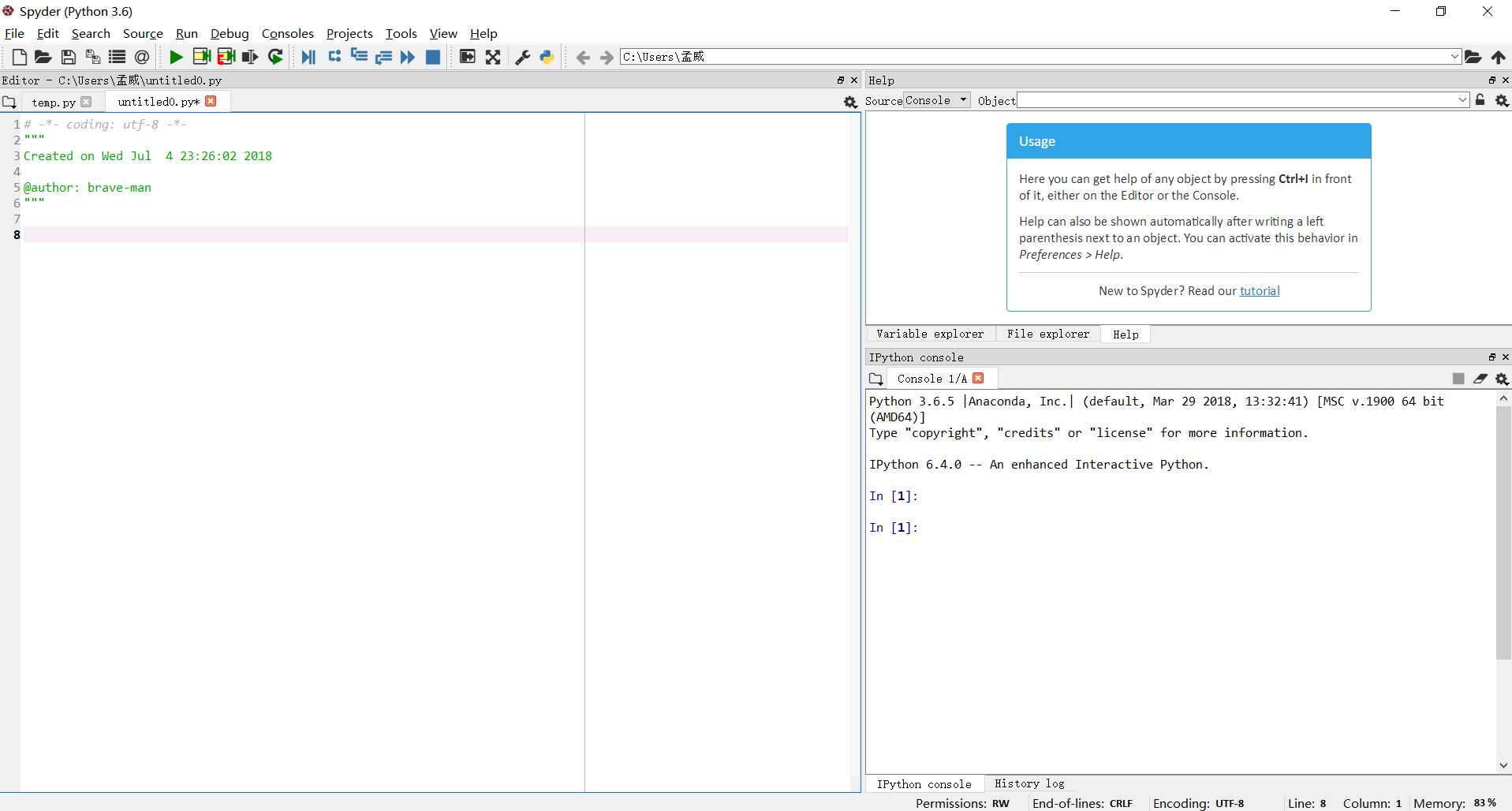
单击 spyder ,一个仅仅比pycharm逊色一点的开发工具就打开了。如果想要代码自动补全的功能,大家可以百度下哈,这里就不介绍了。
标签:pycha 现在 系统 管理 三方 搭建 功能 记不清 下载地址
原文地址:https://www.cnblogs.com/zrmw/p/9266008.html