标签:roo 一个 连接 脚本语言 完成 mmu 系统 提示 不可
一 数据库的选用
我们要实现一个智能问答的系统,所以问到的关键词是不确定的,所以查询的时候更注重的是数据的连接性。而普通的表格数据库它们不能提供用于遍历大量数据的适当性能,无论是遍历还是检索都比较困难。做为图数据库的Neo4j 可以提供存储更多的连接数据。 它将每个配置文件数据作为节点存储在内部,它与相邻节点连接的节点,它们通过关系相互连接,这样检索或遍历是非常容易和更快的。
所以我们选用Neo4j数据库,相比而言他有着以下的有点:
二 构建Neo4j数据库
1.mysql数据库结构
因为我们要做的是一个电影的智能问答系统,所以足够的数据是确保问答成功的基础,我们不可能将数据一条一条的导入,所以我们在网上找到一个关于电影的mysql数据库。该数据库的结构包括以下内容:
(1).genre表(电影类型表)
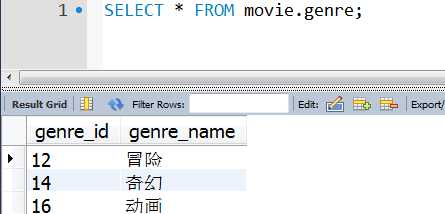
(2). movie表(电影信息表)
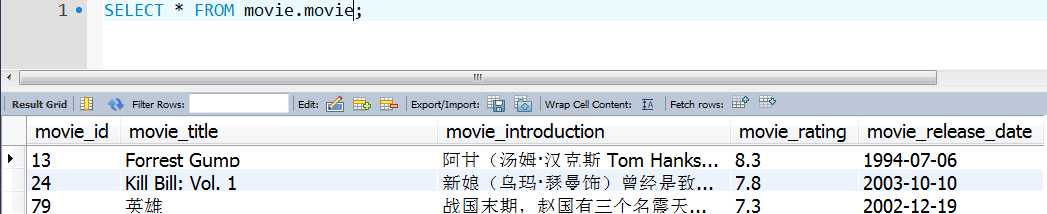
(3). person表(演员信息表)

(4). movie_to_genre表(电影与类别对应关系)
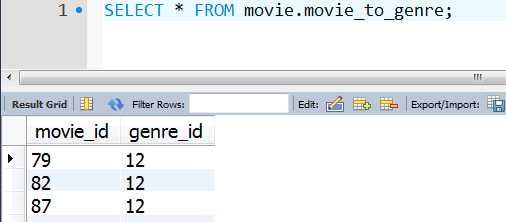
(5):person_to_movie表(电影与演员的对呀关系)
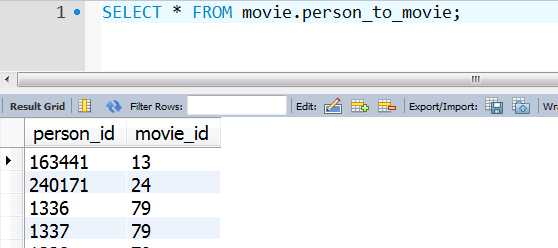
以上为mysql的数据类型以及部分数据,我们要将mysql数据已csv格式导出,才可以用在Neo4j的数据库上。
2. 导出csv文件
由于mysql导出数据的默认目录是:安装路径\Uploads\,因此,我们导出csv的时候,一定要在这个目录下指定导出文件名,否则会提示权限不足。
脚本语言如下:
1 use movie; 2 3 #CMD命令 查看MySql的导入与导出的目录【其他目录无权限】 4 # 使用mysql -u root -p 连接mysql 5 # show variables like ‘%secure%‘ 6 #+--------------------------+------------------------------------------------+ 7 #| Variable_name | Value | 8 #+--------------------------+------------------------------------------------+ 9 #| require_secure_transport | OFF | 10 #| secure_auth | ON | 11 #| secure_file_priv | C:\ProgramData\MySQL\MySQL Server 5.7\Uploads\ |genregenre 12 #+--------------------------+------------------------------------------------+ 13 #3 rows in set, 1 warning (0.00 sec) 14 15 #MySql导出csv数据,带表头 16 17 18 #导出电影的类型 19 SELECT * INTO OUTFILE ‘C:/ProgramData/MySQL/MySQL Server 5.7/Uploads/genre.csv‘ 20 FIELDS TERMINATED BY ‘,‘ 21 FROM (select ‘gid‘,‘gname‘ union select*from genre) genre_; 22 23 24 25 #导出电影的信息 == 如果太多可以只导出前500个,加限制 26 SELECT * INTO OUTFILE ‘C:/ProgramData/MySQL/MySQL Server 5.7/Uploads/movie.csv‘ 27 FIELDS TERMINATED BY ‘,‘ 28 OPTIONALLY ENCLOSED BY ‘"‘ 29 LINES TERMINATED BY ‘\r‘ #电影描述中出现\r换行字符, 30 FROM (select ‘mid‘,‘title‘,‘introduction‘,‘rating‘,‘releasedate‘ union select*from movie) movie_; 31 32 33 34 #导出演员person的信息 == 如果有中文名要中文名,如果没有取英文名 35 SELECT * INTO OUTFILE ‘C:/ProgramData/MySQL/MySQL Server 5.7/Uploads/person.csv‘ 36 FIELDS TERMINATED BY ‘,‘ 37 OPTIONALLY ENCLOSED BY ‘"‘ 38 FROM (select ‘pid‘,‘birth‘,‘death‘,‘name‘,‘biography‘,‘birthplace‘ union 39 select person_id,person_birth_day,person_death_day,case when person_name is null then person_english_name else person_name end 40 as name,person_biography,person_birth_place from person) person_; 41 42 #导出电影ID和电影类别之间的对应 【1对1】 43 SELECT * INTO OUTFILE ‘C:/ProgramData/MySQL/MySQL Server 5.7/Uploads/movie_to_genre.csv‘ 44 FIELDS TERMINATED BY ‘,‘ 45 OPTIONALLY ENCLOSED BY ‘"‘ 46 FROM (select ‘mid‘,‘gid‘ union select*from movie_to_genre) movie_to_genre_; 47 48 49 #导出演员ID和电影ID之间的对应 【1对多】 50 SELECT * INTO OUTFILE ‘C:/ProgramData/MySQL/MySQL Server 5.7/Uploads/person_to_movie.csv‘ 51 FIELDS TERMINATED BY ‘,‘ 52 OPTIONALLY ENCLOSED BY ‘"‘ 53 FROM (select ‘pid‘,‘mid‘ union select*from person_to_movie) person_to_movie_; 54 55 56 #解决导出csv中文乱码问题:将csv用txt打开,另存为,选择utf8编码保存覆盖即可
导出后在Upload目录下有着如下的导出文件:

注意:如果csv文件中出现乱码,将其以记事本方式打开,保存时将编码方式改为“UTF-8”,覆盖源文件即可。
三 导入Neo4j数据库
1. neo4j导入路径
在neo4j安装目录下有一个import文件夹(没有的话自己新建一个这样的文件夹),将刚才导出的csv文件存放到这个文件夹中。
2. Neo4j导入数据
开启Neo4j服务之后,进入服务页面 http://localhost:7474/browser/
在输入命令行中依次输入以下命令进行导入数据库。
1 找到neo4j的安装路径,并在D:\neo4j-community-3.4.0\目录下创建import目录 2 完整路径如下D:\neo4j-community-3.4.0\import 3 因为neo4j支持导入csv文件,其默认目录入口是 ...\import 4 5 6 //导入节点 电影类型 == 注意类型转换 7 LOAD CSV WITH HEADERS FROM "file:///genre.csv" AS line 8 MERGE (p:Genre{gid:toInteger(line.gid),name:line.gname}) 9 10 11 //导入节点 演员信息 12 LOAD CSV WITH HEADERS FROM ‘file:///person.csv‘ AS line 13 MERGE (p:Person { pid:toInteger(line.pid),birth:line.birth, 14 death:line.death,name:line.name, 15 biography:line.biography, 16 birthplace:line.birthplace}) 17 18 19 // 导入节点 电影信息 20 LOAD CSV WITH HEADERS FROM "file:///movie.csv" AS line 21 MERGE (p:Movie{mid:toInteger(line.mid),title:line.title,introduction:line.introduction, 22 rating:toFloat(line.rating),releasedate:line.releasedate}) 23 24 25 // 导入关系 actedin 电影是谁参演的 1对多 26 LOAD CSV WITH HEADERS FROM "file:///person_to_movie.csv" AS line 27 match (from:Person{pid:toInteger(line.pid)}),(to:Movie{mid:toInteger(line.mid)}) 28 merge (from)-[r:actedin{pid:toInteger(line.pid),mid:toInteger(line.mid)}]->(to) 29 30 //导入关系 电影是什么类型 == 1对多 31 LOAD CSV WITH HEADERS FROM "file:///movie_to_genre.csv" AS line 32 match (from:Movie{mid:toInteger(line.mid)}),(to:Genre{gid:toInteger(line.gid)}) 33 merge (from)-[r:is{mid:toInteger(line.mid),gid:toInteger(line.gid)}]->(to)
检测查询:
1 //问:章子怡都演了哪些电影? 2 match(n:Person)-[:actedin]->(m:Movie) where n.name=‘章子怡‘ return m.title 3 //删除所有的节点及关系 4 MATCH (n)-[r]-(b) 5 DELETE n,r,b
由于csv导入neo4j的数据都是字符串的数据类型,因此,对于一些有特殊要求的字段,我们需要在导入的时候进行类型转换。如下等等:

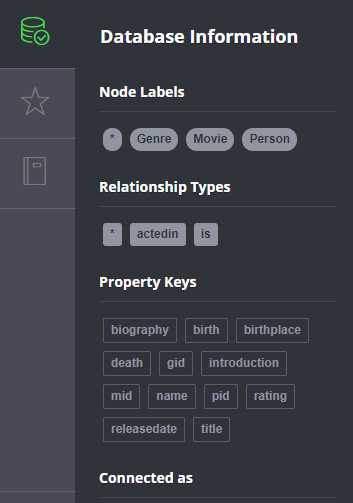
导入之后,Neo4j结构如下:
可以查询关联记录如下:
1 $ match (n)-[r:is]-(b) return n,r,b limit 10
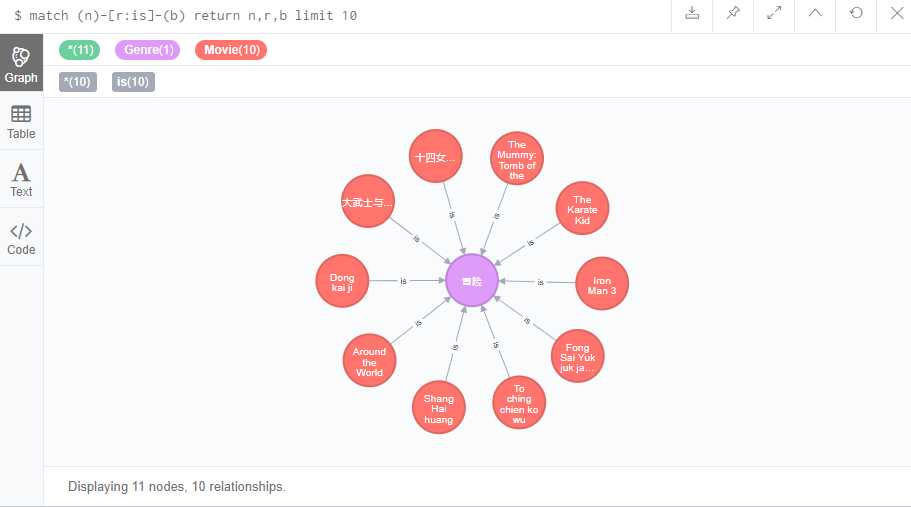
以上,就完成了电影问答系统中Neo4j数据库的创建。
!文中部分引用“https://blog.csdn.net/Appleyk/article/details/80332911”
标签:roo 一个 连接 脚本语言 完成 mmu 系统 提示 不可
原文地址:https://www.cnblogs.com/Mask-D/p/9267446.html