标签:线程调度 selected 全局 patch ++ 网络抓包 意思 long date
近1年,偶尔发生应用系统启动时某些操作超时的问题,特别在使用4核心Surface以后。笔记本和台式机比较少遇到,服务器则基本上没有遇到过。
这些年,我写的应用都有一个习惯,就是启动时异步做很多准备工作。基本上确定这个问题跟它们有关。
最近两个月花了些时间分析线程池调度机制,有点绕,这里记录下来,防止以后忘了。
这里以一个典型WinForm应用来分析。开发环境Surface Pro4,CPU=4
在vs中调试应用,可以明显感觉到启动时会卡3~5秒,卡住时点下暂停。
通过调用栈发现程序死锁了,调用逻辑伪代码:Click=>6 * Task.Run(GetBill)=>Init=>GetConfig
业务逻辑,点击按钮Click,异步调用6次GetBill,每次都要Init判断初始化,这里有lock,拿到锁的第一个线程GetConfig从配置中心拿配置数据。
线程窗口,5个线程卡在 Init 的lock那里,1个线程通过Init进入GetConfig。
GetConfig内部通过HttpClient异步请求数据,用了 task.Wait(5000),这里也卡住了。
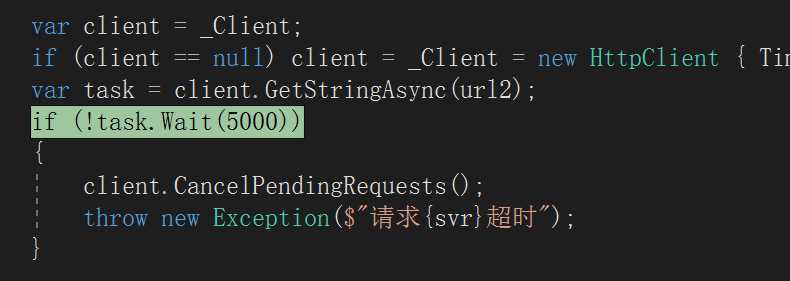
就这样,6个线程死在这,一动不动的。
通过网络抓包发现,Http的请求早就返回来了,根本不需要等5000ms。
查看任务窗口,大量“已阻止”和“已计划”,两个“等待”,然后大家都不动,这就是死锁了。
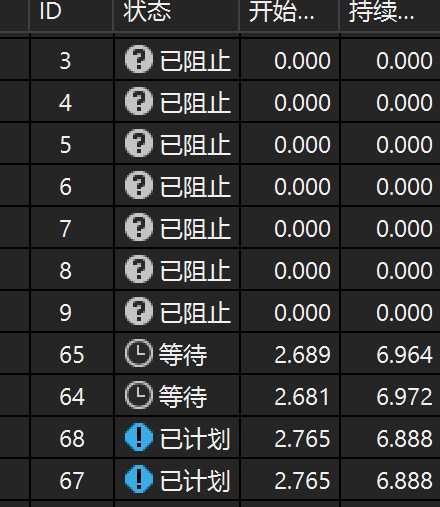
从任务调度层面来猜测,应该是Task调度队列拥挤,导致HttpClient异步请求完成以后,没有办法安排线程去同时task.Wait(5000)退出。
Task调度一直觉得很复杂,不好深入分析。
刚开始以为是大量使用Task.Run所致,大部分改为ThreadPool.QueueUserWorkItem以后,堵塞有所减少,但还是存在。
ILSpy打开ThreadPool发现,它也变得复杂了,不再是.Net2.0时代那个单纯的小伙子。
时间优先,上个月写了个线程池ThreadPoolX,并行队列管理线程,每次排队任务委托,就拿一个出来用,用完后还回去。
源码如下:https://github.com/NewLifeX/X/blob/master/NewLife.Core/Threading/ThreadPoolX.cs
更新到上面这个WinForm应用,死锁问题立马解决。
ThreadPoolX非常简单,所有异步任务都有平等获取线程的机会,不存在说前面的线程卡住了,后面线程就没有机会执行。
尽管利用率低一些,但是可以轻易避免这种死锁的发生。
因此,可以确定是因为Task调度和ThreadPoll调度里面的某种智能化机制,加上程序里可能不合理的使用,导致了死锁的发生!
上个月虽然解决了问题,但没有搞清楚内部机制,总是睡不好。最近晚上有时间查了各种资料,以及分析了源码。
Task/TPL默认都是调用ThreadPool来执行任务,我们就以最常用的Task.Run作为切入点来分析。
/// <summary> /// Queues the specified work to run on the ThreadPool and returns a Task handle for that work. /// </summary> /// <param name="action">The work to execute asynchronously</param> /// <returns>A Task that represents the work queued to execute in the ThreadPool.</returns> /// <exception cref="T:System.ArgumentNullException"> /// The <paramref name="action"/> parameter was null. /// </exception> public static Task Run(Action action) { return Task.InternalStartNew(null, action, null, default(CancellationToken), TaskScheduler.Default, TaskCreationOptions.DenyChildAttach, InternalTaskOptions.None); }
Task.Run内部使用了默认调度器,另一个关注点就是 DenyChildAttach了,阻止其它任务作为当前任务的子任务。
// Implicitly converts action to object and handles the meat of the StartNew() logic. internal static Task InternalStartNew( Task creatingTask, Delegate action, object state, CancellationToken cancellationToken, TaskScheduler scheduler, TaskCreationOptions options, InternalTaskOptions internalOptions) { // Validate arguments. if (scheduler == null) { ThrowHelper.ThrowArgumentNullException(ExceptionArgument.scheduler); } Contract.EndContractBlock(); // Create and schedule the task. This throws an InvalidOperationException if already shut down. // Here we add the InternalTaskOptions.QueuedByRuntime to the internalOptions, so that TaskConstructorCore can skip the cancellation token registration Task t = new Task(action, state, creatingTask, cancellationToken, options, internalOptions | InternalTaskOptions.QueuedByRuntime, scheduler); t.ScheduleAndStart(false); return t; }
InternalStartNew内部实例化一个Task对象,然后调用ScheduleAndStart,加入调度器并且启动
/// <summary> /// Schedules the task for execution. /// </summary> /// <param name="needsProtection">If true, TASK_STATE_STARTED bit is turned on in /// an atomic fashion, making sure that TASK_STATE_CANCELED does not get set /// underneath us. If false, TASK_STATE_STARTED bit is OR-ed right in. This /// allows us to streamline things a bit for StartNew(), where competing cancellations /// are not a problem.</param> internal void ScheduleAndStart(bool needsProtection) { Debug.Assert(m_taskScheduler != null, "expected a task scheduler to have been selected"); Debug.Assert((m_stateFlags & TASK_STATE_STARTED) == 0, "task has already started"); // Set the TASK_STATE_STARTED bit if (needsProtection) { if (!MarkStarted()) { // A cancel has snuck in before we could get started. Quietly exit. return; } } else { m_stateFlags |= TASK_STATE_STARTED; } if (s_asyncDebuggingEnabled) { AddToActiveTasks(this); } if (AsyncCausalityTracer.LoggingOn && (Options & (TaskCreationOptions)InternalTaskOptions.ContinuationTask) == 0) { //For all other task than TaskContinuations we want to log. TaskContinuations log in their constructor AsyncCausalityTracer.TraceOperationCreation(CausalityTraceLevel.Required, this.Id, "Task: " + m_action.Method.Name, 0); } try { // Queue to the indicated scheduler. m_taskScheduler.InternalQueueTask(this); } catch (ThreadAbortException tae) { AddException(tae); FinishThreadAbortedTask(delegateRan: false); } catch (Exception e) { // The scheduler had a problem queueing this task. Record the exception, leaving this task in // a Faulted state. TaskSchedulerException tse = new TaskSchedulerException(e); AddException(tse); Finish(false); // Now we need to mark ourselves as "handled" to avoid crashing the finalizer thread if we are called from StartNew(), // because the exception is either propagated outside directly, or added to an enclosing parent. However we won‘t do this for // continuation tasks, because in that case we internally eat the exception and therefore we need to make sure the user does // later observe it explicitly or see it on the finalizer. if ((Options & (TaskCreationOptions)InternalTaskOptions.ContinuationTask) == 0) { // m_contingentProperties.m_exceptionsHolder *should* already exist after AddException() Debug.Assert( (m_contingentProperties != null) && (m_contingentProperties.m_exceptionsHolder != null) && (m_contingentProperties.m_exceptionsHolder.ContainsFaultList), "Task.ScheduleAndStart(): Expected m_contingentProperties.m_exceptionsHolder to exist " + "and to have faults recorded."); m_contingentProperties.m_exceptionsHolder.MarkAsHandled(false); } // re-throw the exception wrapped as a TaskSchedulerException. throw tse; } }
准备了很多工作,最终还是为了加入调度器m_taskScheduler.InternalQueueTask(this)
protected internal override void QueueTask(Task task) { if ((task.Options & TaskCreationOptions.LongRunning) != 0) { Thread thread = new Thread(s_longRunningThreadWork); thread.IsBackground = true; thread.Start(task); } else { bool forceGlobal = (task.Options & TaskCreationOptions.PreferFairness) != TaskCreationOptions.None; ThreadPool.UnsafeQueueCustomWorkItem(task, forceGlobal); } }
线程池任务调度器ThreadPoolTaskScheduler的QueueTask是重点。
首先是LongRunning标识,直接开了个新线程,很粗暴很直接。
其次是PreferFairness标识,公平,forceGlobal,这个应该就是导致死锁的根本。
public void Enqueue(IThreadPoolWorkItem callback, bool forceGlobal) { if (loggingEnabled) System.Diagnostics.Tracing.FrameworkEventSource.Log.ThreadPoolEnqueueWorkObject(callback); ThreadPoolWorkQueueThreadLocals tl = null; if (!forceGlobal) tl = ThreadPoolWorkQueueThreadLocals.threadLocals; if (null != tl) { tl.workStealingQueue.LocalPush(callback); } else { workItems.Enqueue(callback); } EnsureThreadRequested(); }
未打开全局且有本地队列时,放入本地队列threadLocals,否则加入全局队列workItems。
正式化这个本地队列的优化机制,导致了我们的死锁。
如果应用层直接调用 ThreadPool.QueueUserWorkItem ,都是 forceGlobal=true,也就都是全局队列。
这也说明了为什么我们把部分Task.Run改为ThreadPool.QueueUserItem后,情况有所改观。
internal void EnsureThreadRequested() { // // If we have not yet requested #procs threads from the VM, then request a new thread. // Note that there is a separate count in the VM which will also be incremented in this case, // which is handled by RequestWorkerThread. // int count = numOutstandingThreadRequests; while (count < ThreadPoolGlobals.processorCount) { int prev = Interlocked.CompareExchange(ref numOutstandingThreadRequests, count + 1, count); if (prev == count) { ThreadPool.RequestWorkerThread(); break; } count = prev; } }
上面把任务放入队列后,通过QCall调用了EnsureThreadRequested,此时豁然开朗!
原来,这里才是真正的申请线程池来处理队列里面的任务,并且最大线程数就是处理器个数!
我们可以写个简单程序来验证一下:
Console.WriteLine("CPU={0}", Environment.ProcessorCount); for (var i = 0; i < 10; i++) { ThreadPool.QueueUserWorkItem(s => { var n = (Int32)s; Console.WriteLine("{0:HH:mm:ss.fff} th {1} start", DateTime.Now, n); Thread.Sleep(2000); Console.WriteLine("{0:HH:mm:ss.fff} th {1} end", DateTime.Now, n); }, i); }
CPU=4
18:05:27.936 th 2 start
18:05:27.936 th 3 start
18:05:27.936 th 1 start
18:05:27.936 th 0 start
18:05:29.373 th 4 start
18:05:29.939 th 2 end
18:05:29.940 th 5 start
18:05:29.940 th 0 end
18:05:29.941 th 6 start
18:05:29.940 th 1 end
18:05:29.940 th 3 end
18:05:29.942 th 7 start
18:05:29.942 th 8 start
18:05:30.871 th 9 start
18:05:31.374 th 4 end
18:05:31.942 th 5 end
18:05:31.942 th 6 end
18:05:31.943 th 7 end
18:05:31.943 th 8 end
18:05:32.872 th 9 end
在我的4核心CPU上执行,27.936先调度了4个任务,然后1秒多之后再调度第5个任务,其它任务则是等前面4个任务完成以后才有机会。
第5个任务能够在前4个完成之前得到调度,可能跟Sleep有关,这是内部机制了。
目前可以肯定的是,ThreadPool空有1000个最大线程数,但实际上只能用略大于CPU个数的线程!(CPU+1 ?)
当然,它内部应该有其它机制来增加线程调度,比如Sleep。
最后是调度Dispatch
internal static bool Dispatch() { var workQueue = ThreadPoolGlobals.workQueue; // // The clock is ticking! We have ThreadPoolGlobals.TP_QUANTUM milliseconds to get some work done, and then // we need to return to the VM. // int quantumStartTime = Environment.TickCount; // // Update our records to indicate that an outstanding request for a thread has now been fulfilled. // From this point on, we are responsible for requesting another thread if we stop working for any // reason, and we believe there might still be work in the queue. // // Note that if this thread is aborted before we get a chance to request another one, the VM will // record a thread request on our behalf. So we don‘t need to worry about getting aborted right here. // workQueue.MarkThreadRequestSatisfied(); // Has the desire for logging changed since the last time we entered? workQueue.loggingEnabled = FrameworkEventSource.Log.IsEnabled(EventLevel.Verbose, FrameworkEventSource.Keywords.ThreadPool | FrameworkEventSource.Keywords.ThreadTransfer); // // Assume that we‘re going to need another thread if this one returns to the VM. We‘ll set this to // false later, but only if we‘re absolutely certain that the queue is empty. // bool needAnotherThread = true; IThreadPoolWorkItem workItem = null; try { // // Set up our thread-local data // ThreadPoolWorkQueueThreadLocals tl = workQueue.EnsureCurrentThreadHasQueue(); // // Loop until our quantum expires. // while ((Environment.TickCount - quantumStartTime) < ThreadPoolGlobals.TP_QUANTUM) { bool missedSteal = false; workItem = workQueue.Dequeue(tl, ref missedSteal); if (workItem == null) { // // No work. We‘re going to return to the VM once we leave this protected region. // If we missed a steal, though, there may be more work in the queue. // Instead of looping around and trying again, we‘ll just request another thread. This way // we won‘t starve other AppDomains while we spin trying to get locks, and hopefully the thread // that owns the contended work-stealing queue will pick up its own workitems in the meantime, // which will be more efficient than this thread doing it anyway. // needAnotherThread = missedSteal; // Tell the VM we‘re returning normally, not because Hill Climbing asked us to return. return true; } if (workQueue.loggingEnabled) System.Diagnostics.Tracing.FrameworkEventSource.Log.ThreadPoolDequeueWorkObject(workItem); // // If we found work, there may be more work. Ask for another thread so that the other work can be processed // in parallel. Note that this will only ask for a max of #procs threads, so it‘s safe to call it for every dequeue. // workQueue.EnsureThreadRequested(); // // Execute the workitem outside of any finally blocks, so that it can be aborted if needed. // if (ThreadPoolGlobals.enableWorkerTracking) { bool reportedStatus = false; try { ThreadPool.ReportThreadStatus(isWorking: true); reportedStatus = true; workItem.ExecuteWorkItem(); } finally { if (reportedStatus) ThreadPool.ReportThreadStatus(isWorking: false); } } else { workItem.ExecuteWorkItem(); } workItem = null; // // Notify the VM that we executed this workitem. This is also our opportunity to ask whether Hill Climbing wants // us to return the thread to the pool or not. // if (!ThreadPool.NotifyWorkItemComplete()) return false; } // If we get here, it‘s because our quantum expired. Tell the VM we‘re returning normally. return true; } catch (ThreadAbortException tae) { // // This is here to catch the case where this thread is aborted between the time we exit the finally block in the dispatch // loop, and the time we execute the work item. QueueUserWorkItemCallback uses this to update its accounting of whether // it was executed or not (in debug builds only). Task uses this to communicate the ThreadAbortException to anyone // who waits for the task to complete. // workItem?.MarkAborted(tae); // // In this case, the VM is going to request another thread on our behalf. No need to do it twice. // needAnotherThread = false; // throw; //no need to explicitly rethrow a ThreadAbortException, and doing so causes allocations on amd64. } finally { // // If we are exiting for any reason other than that the queue is definitely empty, ask for another // thread to pick up where we left off. // if (needAnotherThread) workQueue.EnsureThreadRequested(); } // we can never reach this point, but the C# compiler doesn‘t know that, because it doesn‘t know the ThreadAbortException will be reraised above. Debug.Fail("Should never reach this point"); return true; }
public IThreadPoolWorkItem Dequeue(ThreadPoolWorkQueueThreadLocals tl, ref bool missedSteal) { WorkStealingQueue localWsq = tl.workStealingQueue; IThreadPoolWorkItem callback; if ((callback = localWsq.LocalPop()) == null && // first try the local queue !workItems.TryDequeue(out callback)) // then try the global queue { // finally try to steal from another thread‘s local queue WorkStealingQueue[] queues = WorkStealingQueueList.Queues; int c = queues.Length; Debug.Assert(c > 0, "There must at least be a queue for this thread."); int maxIndex = c - 1; int i = tl.random.Next(c); while (c > 0) { i = (i < maxIndex) ? i + 1 : 0; WorkStealingQueue otherQueue = queues[i]; if (otherQueue != localWsq && otherQueue.CanSteal) { callback = otherQueue.TrySteal(ref missedSteal); if (callback != null) { break; } } c--; } } return callback; }
这个Dispatch应该是由内部借出来的线程池线程调用,有点意思:
这里最复杂的就是本地队列FILO结构,这也是专门为Task而设计。
End.
标签:线程调度 selected 全局 patch ++ 网络抓包 意思 long date
原文地址:https://www.cnblogs.com/nnhy/p/ThreadPool.html