标签:get analysis bubuko title 形式 处理过程 好的 分词 文件
本文从官网下载Lucene开始,一步一步进行Lucene的应用学习研究。
1、下载
(1)首先,去Lucne的Apache官网主页 http://lucene.apache.org/
(2)找到下载链接
下载最新的Lunce ,当前最新版本为:7.4.0

(3)下载之后,解压开
2、初探下载的文件
(1)解压后,打开"lucene-7.2.1\analysis\common/"

(2)点开这里面的"README.txt"阅读,从中发现一些,陌生的关键词,进行研究学习
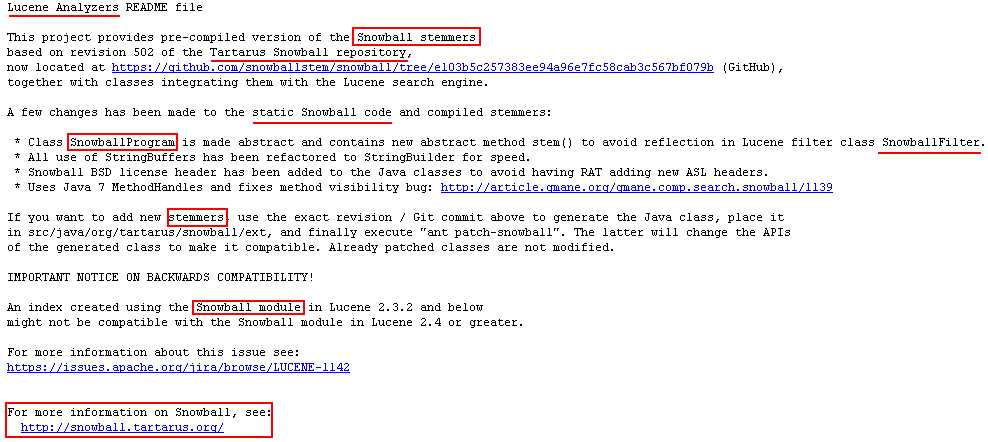
(3)可以从中发现一些关键词汇:
Snowball stemmers, Tartarus Snowball repository, 这个 readme.txt 是 "Lucene Analyzers"的。
3、Snowball
For more information on Snowball, see: http://snowball.tartarus.org/

4、stemmer
在网络上,找到一个 Python自然语言处理:词干、词形与MaxMatch算法 文中有关于Snowball Stemmer的应用。

在信息检索领域,Stemming是指将英文单词转换为词干的处理过程。Stemming与Lemmatization的不同是,前者只是词干的简单提取,后者则利用上下文语义环境(context)进行词元(lemma)转换。
自然语言处理中一个很重要的操作就是所谓的stemming 和 lemmatization,二者非常类似。它们是词形规范化的两类重要方式,都能够达到有效归并词形的目的,二者既有联系也有区别。
(1)词干提取(stemming)
定义:Stemming is the process for reducing inflected (or sometimes derived) words to their stem, base or root form—generally a written word form.
解释一下,Stemming 是抽取词的词干或词根形式(不一定能够表达完整语义)。
NLTK中提供了三种最常用的词干提取器接口,即 Porter stemmer, Lancaster Stemmer 和 Snowball Stemmer。
(2)词形还原(lemmatization)
定义:Lemmatisation (or lemmatization) in linguistics, is the process of grouping together the different inflected forms of a word so they can be analysed as a single item.
可见,Lemmatisation是把一个任何形式的语言词汇还原为一般形式(能表达完整语义)。相对而言,词干提取是简单的轻量级的词形归并方式,最后获得的结果为词干,并不一定具有实际意义。词形还原处理相对复杂,获得结果为词的原形,能够承载一定意义,与词干提取相比,更具有研究和应用价值。
网上有参考文章: Lucene学习总结之十:Lucene的分词器Analyzer

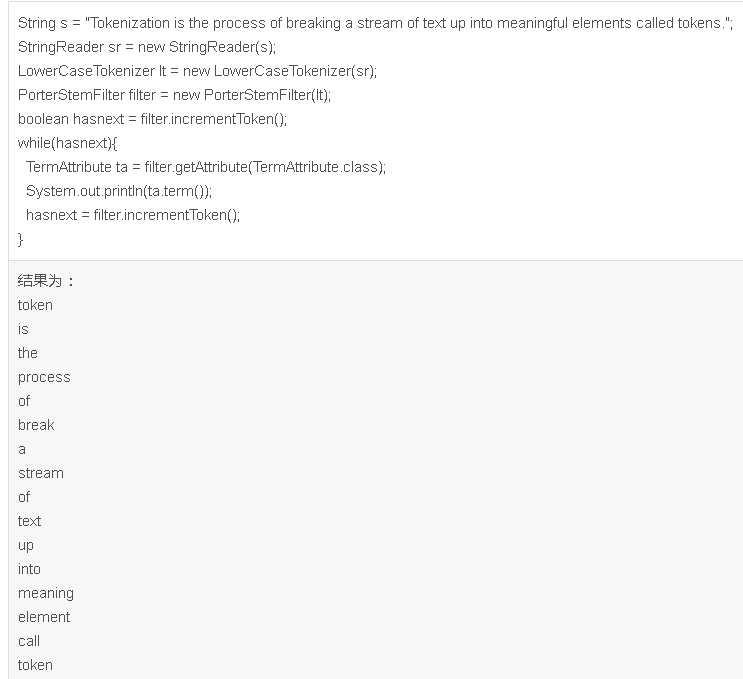
5、总结
本次,初步的下载了Lucene,简单的了解了下框架内的文件组织,以一个Analyzer的readme.txt文件阅读,找出了其中关于全文检索的专业术语,进行查找资料学习。后面,会进一步的深入研究。
如果我的文章帮助了你,可以赞赏我 1 元给我支持,让我继续写出更好的内容)


(微信) (支付宝)
微信/支付宝 扫一扫
Lucene学习入门——下载初识Snowball Stemmer
标签:get analysis bubuko title 形式 处理过程 好的 分词 文件
原文地址:https://www.cnblogs.com/moonsoft/p/9272863.html