标签:ase RoCE 卷积 好的 数据集 http target cas region
YOLO的全拼是You Only Look Once,顾名思义就是只看一次,把目标区域预测和目标类别预测合二为一,作者将目标检测任务看作目标区域预测和类别预测的回归问题。该方法采用单个神经网络直接预测物品边界和类别概率,实现端到端的物品检测。因此识别性能有了很大提升,达到每秒45帧,而在快速版YOLO(Fast YOLO,卷积层更少)中,可以达到每秒155帧。
当前最好系统相比,YOLO目标区域定位误差更大,但是背景预测的假阳性优于当前最好的方法。
人类瞥了一眼图像,立即知道图像中的物体,它们在哪里以及它们如何相互作用。 人类视觉系统快速而准确,使我们能够执行复杂的任务,比如汽车驾驶。
传统的目标检测系统利用分类器来执行检测。 为了检测对象,这些系统在测试图片的不同位置不同尺寸大小采用分类器对其进行评估。 如目标检测系统采用deformable parts models (DPM)方法,通过滑动框方法提出目标区域,然后采用分类器来实现识别。近期的R-CNN类方法采用region proposal methods,首先生成潜在的bounding boxes,然后采用分类器识别这些bounding boxes区域。最后通过post-processing来去除重复bounding boxes来进行优化。这类方法流程复杂,存在速度慢和训练困难的问题。
我们将目标检测问题转换为直接从图像中提取bounding boxes和类别概率的单个回归问题,只需一眼(you only look once,YOLO)即可检测目标类别和位置。
YOLO简洁明了:见下图。 YOLO算法采用单个卷积神经网络来预测多个bounding boxes和类别概率。 与传统的物体检测方法相比,这种统一模型具有以下优点:
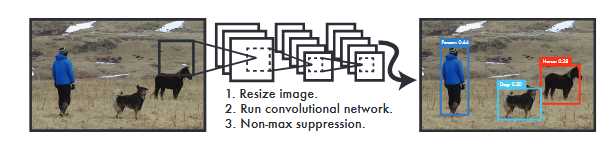
在准确性上,YOLO算法仍然落后于最先进的检测系统。 虽然它可以快速识别图像中的对象,但它很难精确定位某些对象,特别是小对象。
作者将目标检测的流程统一为单个神经网络。该神经网络采用整个图像信息来预测目标的bounding boxes的同时识别目标的类别,实现端到端实时目标检测任务。
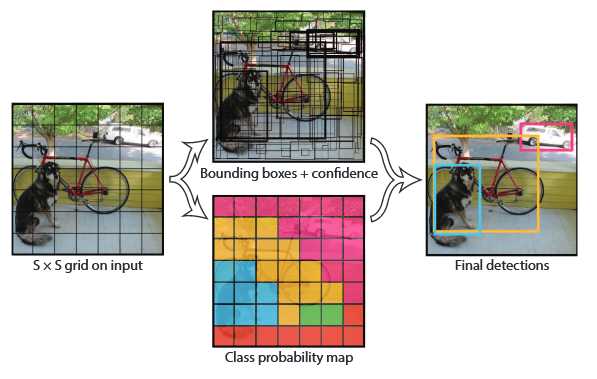
如图2-1所示,YOLO首先将图像分为S×S的格子(grid cell)。如果一个目标的中心落入格子,该格子就负责检测该目标。每一个格子(grid cell)预测bounding boxes(B)和该boxes的置信值(confidence score)。置信值代表box包含一个目标的置信度。然后,我们定义置信值为。如果没有目标,置信值为零。另外,我们希望预测的置信值和ground truth的intersection over union (IOU)相同。
每一个bounding box包含5个值:x,y,w,h和confidence。(x,y)代表与格子相关的box的中心。(w,h)为与全图信息相关的box的宽和高。confidence代表预测boxes的IOU和gound truth。
每个格子(grid cell)预测条件概率值C()。概率值C代表了格子包含一个目标的概率,每一格子只预测一类概率。在测试时,每个box通过类别概率和box置信度相乘来得到特定类别置信分数:
这个分数代表该类别出现在box中的概率和box和目标的合适度。在PASCAL VOC数据集上评价时,我们采用S=7,B=2,C=20(该数据集包含20个类别),最终预测结果为7×7×30的tensor。
标签:ase RoCE 卷积 好的 数据集 http target cas region
原文地址:https://www.cnblogs.com/zyly/p/9274472.html