标签:mil cut cgi epo nal with uid als src
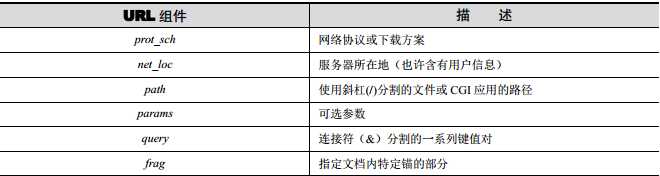
1、urllib.parse.urlparse(urlstring, scheme=‘‘, allow_fragments=True),将urlstring拆分成6个部分,含义如下图。返回的是一个子类的元组。
>>> from urllib.parse import urlparse
>>> o = urlparse(‘http://www.cwi.nl:80/%7Eguido/Python.html‘)
>>> o
ParseResult(scheme=‘http‘, netloc=‘www.cwi.nl:80‘, path=‘/%7Eguido/Python.html‘,
params=‘‘, query=‘‘, fragment=‘‘)
>>> o.scheme
‘http‘
>>> o.port
80
>>> o.geturl()
‘http://www.cwi.nl:80/%7Eguido/Python.html‘
2、urllib.parse.urlunparse(parts),与urlparse功能相反。
>>>parse.urlunparse(parse.urlparse(‘http://www.cwi.nl:80/%7Eguido/Python.html‘)) ‘http://www.cwi.nl:80/%7Eguido/Python.html‘
3、urllib.parse.urljoin(base, url, allow_fragments=True),取得根域名,并将其根路径(net_loc 及其前面的完整路径,但是不包括末端的文件)与 url 连接起来。
>>> from urllib.parse import urljoin >>> urljoin(‘http://www.cwi.nl/%7Eguido/Python.html‘, ‘FAQ.html‘) ‘http://www.cwi.nl/%7Eguido/FAQ.html‘
Note:If url is an absolute URL (that is, starting with // or scheme://), the url’s host name and/or scheme will be present in the result
>>> urljoin(‘http://www.cwi.nl/%7Eguido/Python.html‘, ... ‘//www.python.org/%7Eguido‘) ‘http://www.python.org/%7Eguido
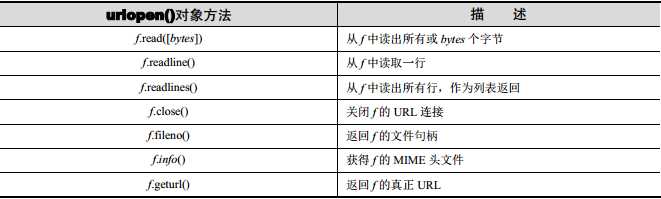
4、urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None),打开一个给定 URL 字符串表示的 Web 连接,并返回文件类型的对象 。返回的对象有如下方法
5、urllib.request.urlretrieve(url, filename=None, reporthook=None, data=None),用于下载完整的 HTML ,返回一个元组
>>> import urllib.request >>> local_filename, headers = urllib.request.urlretrieve(‘http://python.org/‘) >>> html = open(local_filename) >>> html.close()
>>> local_filename
‘C:\\Users\\ZAZA\\AppData\\Local\\Temp\\tmpd7mtgtjf‘
>>> headers
<http.client.HTTPMessage object at 0x0000024C230BEC88>
6、urllib.parse.quote(string, safe=‘/‘, encoding=None, errors=None),函数用来获取 URL 数据,并将其编码,使其可以用于 URL 字符串中。具体来说,必须对某些不能打印的或者不被 Web 服务器作为有效 URL 接收的特殊字符串进行转换 。除了字母、数字、“_”、“.”、“-”、“~”外,其他字符都需要转换为相应的ASCII码的16进制的值。
>>> from urllib import parse >>> parse.quote(‘http://www/~foo/cgi-bin/s.py?name=joe mama&num=6‘) ‘http%3A//www/%7Efoo/cgi-bin/s.py%3Fname%3Djoe%20mama%26num%3D6‘
7、urllib.parse.quote_plus(string, safe=‘‘, encoding=None, errors=None),与上面类似,只是它还可以将空格编码成“+”号 。safe默认为空
>>> from urllib import parse >>> parse.quote_plus(‘http://www/~foo/cgi-bin/s.py?name=joe mama&num=6‘) ‘http%3A%2F%2Fwww%2F%7Efoo%2Fcgi-bin%2Fs.py%3Fname%3Djoe+mama%26num%3D6‘
8、urllib.parse.unquote(string, encoding=‘utf-8‘, errors=‘replace‘) 和urllib.parse.unquote_plus(string, encoding=‘utf-8‘, errors=‘replace‘),与上面两个功能相反
9、urllib.parse.urlencode(query, doseq=False, safe=‘‘, encoding=None, errors=None, quote_via=quote_plus),urlopen()函数接收字典的键值对,并将其编译成字符串,作为CGI 请求的 URL 字符串的一部分。键值对的格式是“键=值”,以连接符(&)划分。另外,键及其对应的值会传到quote_plus()函数中进行适当的编码。
>>> from urllib import parse
>>> d={‘name‘: ‘Georgina Garcia‘, ‘hmdir‘: ‘~ggarcia‘}
>>> parse.urlencode(d)
‘name=Georgina+Garcia&hmdir=%7Eggarcia‘
标签:mil cut cgi epo nal with uid als src
原文地址:https://www.cnblogs.com/sch16/p/9269162.html