标签:bsp 求导 ges amp 没有 估计 sam 表示 The
https://www.bilibili.com/video/av9770302/?p=15
前面说了auto-encoder,VAE可以用于生成
VAE的问题,
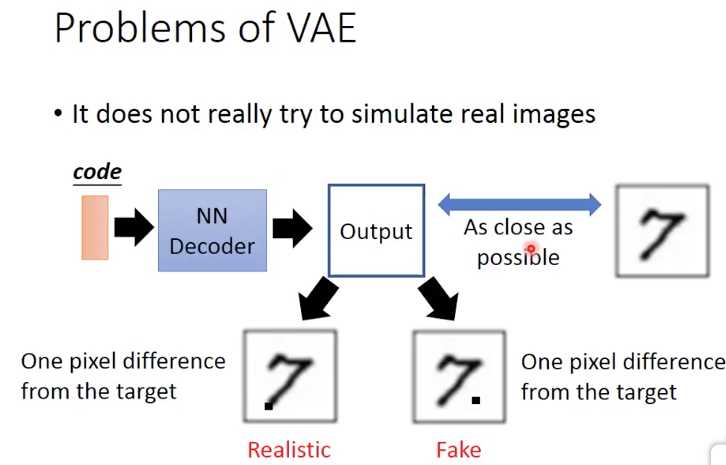
AE的训练是让输入输出尽可能的接近,所以生成出来图片只是在模仿训练集,而无法生成他完全没有见过的,或新的图片
由于VAE并没有真正的理解和学习如何生成新的图片,所以对于下面的例子,他无法区分两个case的好坏,因为从lost上看都是比7多了一个pixel
所以产生GAN,
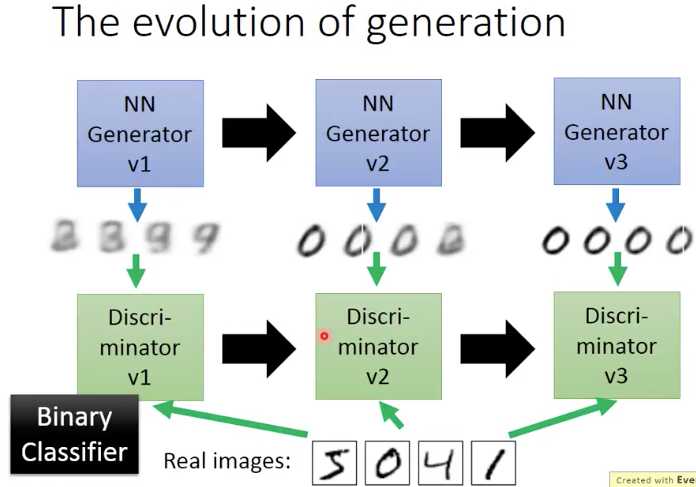
大家都知道GAN是对抗网络,是generator和discriminator的对抗,对抗是有一个逐渐进化的过程
过程是,
我们通过V1的generator的输出和real images来训练V1的discriminator,让V1的discriminator可以判别出两者的差别
然后,将V1的generator和V1的discriminator作为整体network训练(这里需要固定discriminator的参数),目标就是让generator产生的图片可以骗过V1的discriminator
这样就产生出V2的generator,重复上面的过程,让generator和discriminator分别逐渐进化
训练Discriminator的详细过程,

训练generator的详细过程,
可以看到 generator会调整参数,产生image让discriminator判别为1,即骗过discriminator
并且在网络训练的时候,虽然是把generator和discriminator合一起训练,但是要fix住discriminator的参数,不然discriminator只需要简单的迎合generator就可以达到目标,起不到对抗的效果

下面从理论上来看下GAN,
GAN的目的是生成和目标分布(训练集所代表的分布)所接近的分布

Pdata就是训练数据所代表的分布
PG是我们要生成的分布
所以我们的目标就是让PG和Pdata尽可能的close
从Pdata中sample任意m个点,然后用这些点去计算PG,用最大似然估计,算likelihood
让这些点在PG中的概率和尽可能的大,就会让PG分布接近Pdata

这里的推导出,上面给出的最大似然估计,等价于求Pdata和PG的KL散度,这个是make sense的,KL散度本身就用来衡量两个分布的相似度
这里PG可以是任意函数,比如,你可以用高斯混合模型来生成PG,那么theta就是高斯混合中每个高斯的参数和weight
那么这里给定参数和一组sample x,我们就可以用混合高斯的公式算出PG,根据上面的推导,也就得到了两个分布的KL散度
当然高斯混合模型不够强大,很难很好的去拟合Pdata
所以这里是用GAN的第一个优势,我们可以用nn去拟合PG
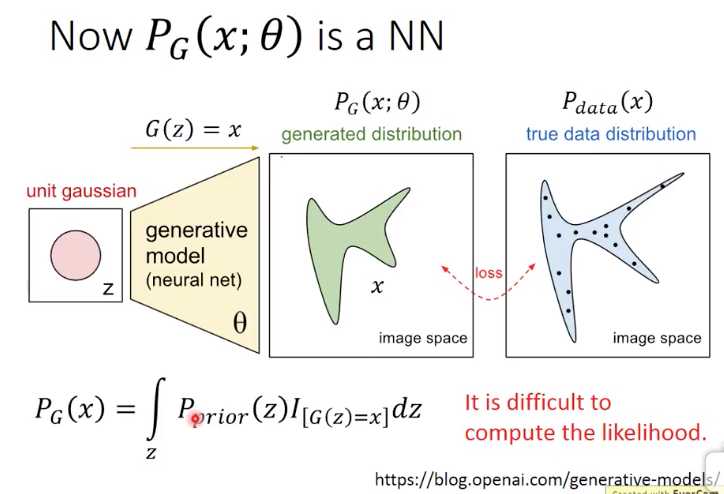
这个图就是GAN的generator,z符合高斯分布,z是什么分布不关键也可以是其他分布
通过Gz函数,得到x,z可以从高斯分布中sample出很多点,所以计算得到很多x,x的分布就是PG;只要nn足够复杂,虽然z的分布式高斯,但x可以是任意分布
这里和传统方法,比如高斯混合的不同是,这个likelihood,即PG不好算,因为这里G是个nn,所以我们没有办法直接计算得到两个分布的KL散度
所以GAN需要discriminator,它也是一个nn,用discriminator来间接的计算PG和Pdata的相似性,从而替代KL散度的计算

GAN可以分成Generator G和Discriminator D,其中D是用来衡量PG和Pdata的相似性
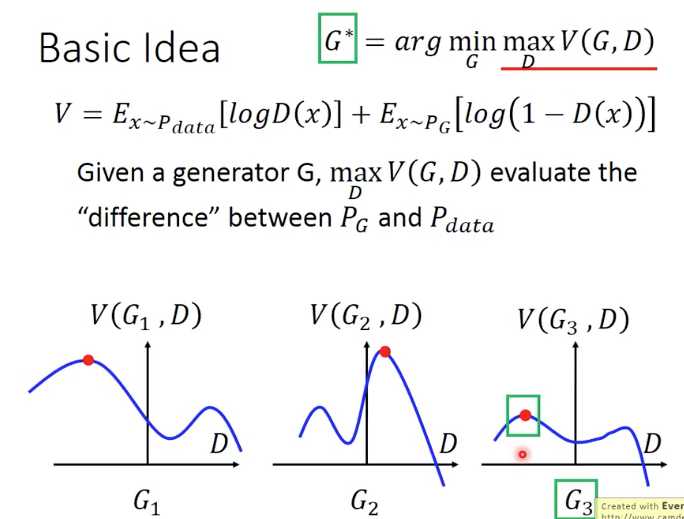
最终优化目标的公式,看着很唬人,又是min,又是max
其实分成两个步骤,
给定G,优化D,使得maxV(红线部分),就是训练discriminator,计算出两个分布之间的差异值;在上图中就是在每个小图里找到那个红点
给定D,优化G,使得min(maxV),就是在训练generator,最小化两个分布之间的差异;就是在上图中挑选出G3
这里有个问题没有讲清楚的是,
为何给定G,优化D,使得maxV,得到的V可以代表两个分布的差异?
如果这个问题明白了,下一步优化G,去最小化这个分布间的差异是很好理解的
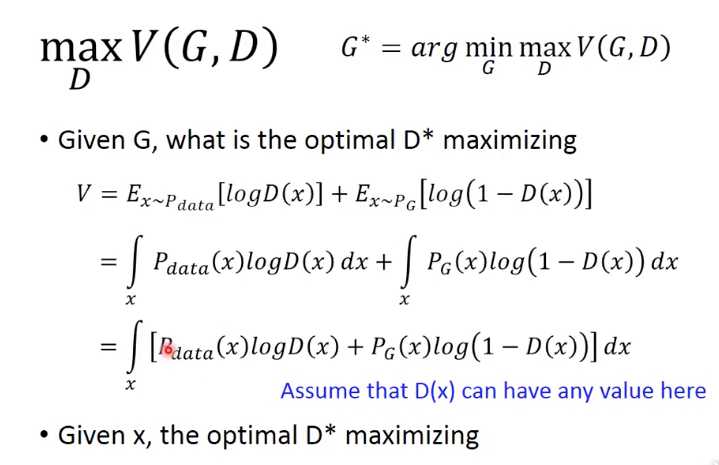
做些简单的转换,如果我们要最后一步这个积分最大,那么等价于对于每个x,积分的内容都最大

这里是给定G,x,Pdata(x),PG(x)都是常量,所以转换成D的一个简单函数
求最大值,就极值,就是求导找到极点
这里推导出当V max的时候, D的定义,并且D的值域应该在0到1之间

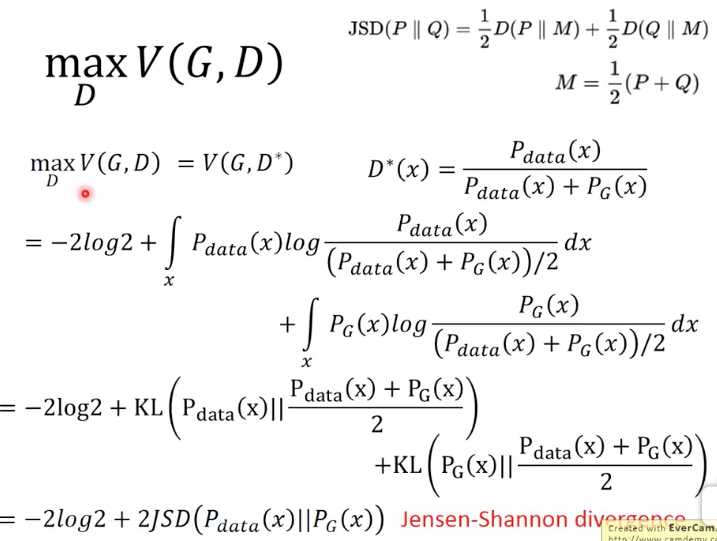
上面推导出如果要Vmax,D要满足
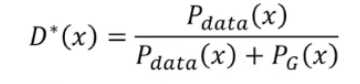
所以进一步将D带入V的公式,这里经过一系列推导得到,V就等价于jensen-shannon divergence
jensen-shannon divergence的定义,如下,
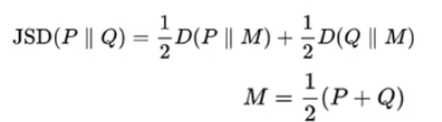
比KL divergence好的是,KL是非对称的,而jensen-shannon divergence是对称的,可以更好的反应两个分布间的差异
那么这里的推导就证明,给定G,优化D让V最大的时候,V就表示Pdata和PG的jensen-shannon divergence,所以这个Vmax就可以表示这个两个分布的差异,也就回答了前面的问题
GAN (Generative Adversarial Network)
标签:bsp 求导 ges amp 没有 估计 sam 表示 The
原文地址:https://www.cnblogs.com/fxjwind/p/9275744.html