标签:file pre 服务 分享图片 参数 下载图片 鼠标 request请求 family
访问今日头条页面(https://www.toutiao.com/)在输入框中输入要搜索的关键字,搜索出的页面点击图集。要爬取的就是这里的所有图集。
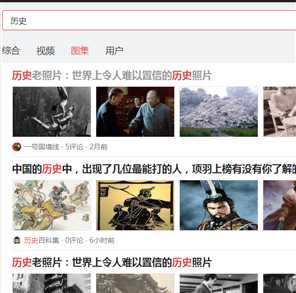
查看页面的URL可以发现这是一个POST请求,然后我们就检查页面找到POST请求包,进行分析。
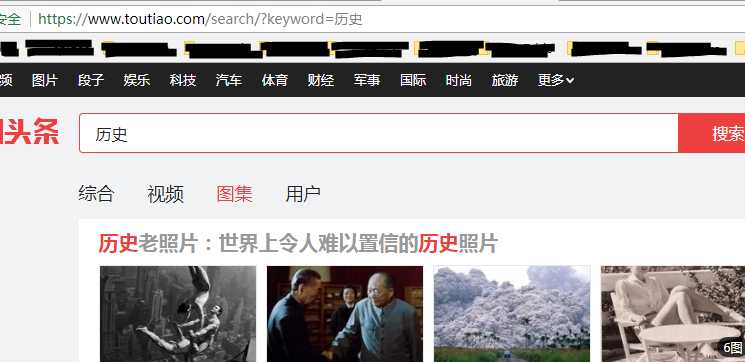
这个就是POST请求服务器返回的response

这是一个JSON格式的数据,复制下来放在解析器中查看。(使用jsonView)
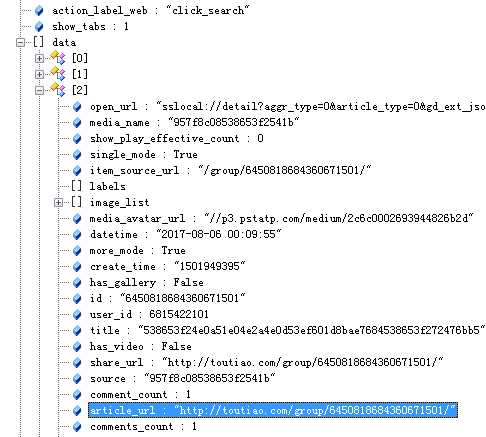
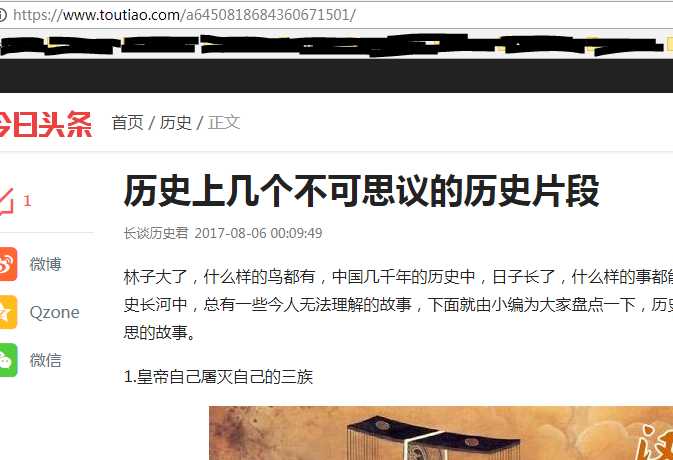
可以看到data字段中的aritical_url与要请求的页面url相同,那么只要抓取到这个json数据通过处理就可以获取当前搜索页面的所有要访问的url。
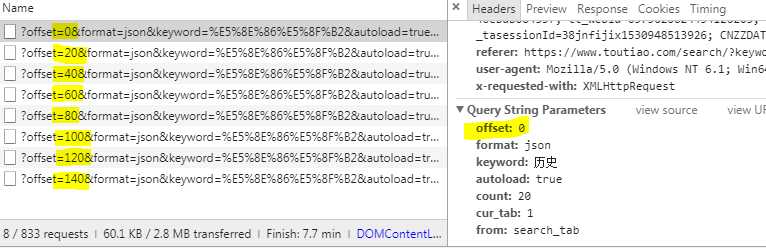
在搜索页面滑动鼠标时,浏览器向服务器发送了多个request请求,用来加载之后的图集。所通过修改offset值就可以获取之后的图集信息。
首先要有一个初始的url作为入口,通过这个url来获取更多的url。这个url就是第一页搜索页的url,可以使用requests库模拟post请求,将参数添加到请求体,并且通过修改请求体中的offset值来获取下一个要爬取的页面。
def get_response(url,offset): header = {‘User-Agent‘: ‘Mozilla/5.0 (X11;Ubuntu;Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0‘} data = { ‘offset‘:offset, ‘format‘:‘json‘, ‘keyword‘:‘历史‘, ‘autoload‘:‘true‘, ‘count‘:‘20‘, ‘cur_tab‘:‘3‘, ‘from‘:‘gallery‘, } response = requests.get(url,headers=header,params=data) response.encoding = ‘utf-8‘ try: if response.status_code == 200: html = response.text return html return None except RequestException: print(‘请求页面出错!‘) return None url = ‘https://www.toutiao.com/search_content/‘ for offset in range(0,121,20): html = get_response(url,str(offset))
然后通过response返回的json数据找出之后要爬取的每个图集的url。
def get_data(dic): if ‘data‘ in dic.keys(): for item in dic[‘data‘]: yield item[‘article_url‘]
通过分析每个图集页面发现,每个图集页面的图片是一个轮播图,但是在一个Ajax请求中有所有图面的url。

选择使用正则将所有的url提取出来。并以字典形式返回。
def handle_detail_html(html,url): from bs4 import BeautifulSoup import re from urllib.parse import urljoin soup = BeautifulSoup(html,‘lxml‘) title_text = soup.find(‘title‘).get_text() pattern = re.compile(‘gallery: JSON.parse\((.*?)\),‘) result = re.findall(pattern, html) pattern = re.compile("(\w{19,23})", re.S) result_end = re.findall(pattern, result[0]) img_url = [] url_header_1 = ‘http://p3.pstatp.com/origin/pgc-image/‘ url_header_2 = ‘http://p3.pstatp.com/origin/‘ for each_url in set(result_end): url_1 = Accessable_download(urljoin(url_header_1,each_url)) url_2 = Accessable_download(urljoin(url_header_2,each_url)) if url_1: img_url.append(urljoin(url_header_1,each_url)) elif url_2: img_url.append(urljoin(url_header_2,each_url)) data_dic = { ‘url‘:url, ‘title‘:title_text, ‘img_list‘:img_url } return data_dic
最后就是连接数据库将信息保存到数据库中,并且将图片下载到本地。
下面是所有代码。
# coding=utf-8 ‘‘‘ 解析Ajax请求抓取今日头条图集并将信息存储到mongoDB并且下载图片到本地 ‘‘‘ import requests from requests.exceptions import RequestException # 返回搜索页的json数据 def get_response(url,offset): header = {‘User-Agent‘: ‘Mozilla/5.0 (X11;Ubuntu;Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0‘} data = { ‘offset‘:offset, ‘format‘:‘json‘, ‘keyword‘:‘历史‘, ‘autoload‘:‘true‘, ‘count‘:‘20‘, ‘cur_tab‘:‘3‘, ‘from‘:‘gallery‘, } response = requests.get(url,headers=header,params=data) response.encoding = ‘utf-8‘ try: if response.status_code == 200: html = response.text return html return None except RequestException: print(‘请求页面出错!‘) return None # 将json数据转为python数据。 def loads_python(data): import os,json dic_data = json.loads(data) return dic_data # 将json中的每个图集的url找出来,将函数作为迭代器每次输出一个url。 def get_data(dic): if ‘data‘ in dic.keys(): for item in dic[‘data‘]: yield item[‘article_url‘] # 获取每个图集页面的html信息 def get_each_html(url): header = {‘User-Agent‘: ‘Mozilla/5.0 (X11;Ubuntu;Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0‘} try: html = requests.get(url,headers=header) html.encoding = ‘utf-8‘ if html.status_code == 200: return html.text return None except RequestException: print(‘图集页面请求错误!‘) return None # 测试图片的url是否可以访问,如果可以就下在图片并保存在本地,然后返回可以访问的图片url。 def Accessable_download(url): import os from hashlib import md5 from urllib.request import urlretrieve print(‘正在尝试:‘,url) filepath = ‘{0}/{1}/{2}.{3}‘.format(os.getcwd(),‘今日头条可爱图集‘,md5(url.encode(‘utf-8‘)).hexdigest(),‘.jpg‘) if not os.path.exists(os.path.join(os.getcwd(),‘今日头条可爱图集‘)): os.mkdir(os.path.join(os.getcwd(),‘今日头条可爱图集‘)) header = {‘User-Agent‘: ‘Mozilla/5.0 (X11;Ubuntu;Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0‘} try: response = requests.get(url,headers=header) if response.status_code == 200: urlretrieve(url,filepath) print(‘已下载完成:‘,url) return True return False except: return False # 提取每个图集页面的信息,标题,图片的url,返回字典格式的信息。 def handle_detail_html(html,url): from bs4 import BeautifulSoup import re from urllib.parse import urljoin soup = BeautifulSoup(html,‘lxml‘) title_text = soup.find(‘title‘).get_text() pattern = re.compile(‘gallery: JSON.parse\((.*?)\),‘) result = re.findall(pattern, html) pattern = re.compile("(\w{19,23})", re.S) result_end = re.findall(pattern, result[0]) img_url = [] url_header_1 = ‘http://p3.pstatp.com/origin/pgc-image/‘ url_header_2 = ‘http://p3.pstatp.com/origin/‘ for each_url in set(result_end): url_1 = Accessable_download(urljoin(url_header_1,each_url)) url_2 = Accessable_download(urljoin(url_header_2,each_url)) if url_1: img_url.append(urljoin(url_header_1,each_url)) elif url_2: img_url.append(urljoin(url_header_2,each_url)) data_dic = { ‘url‘:url, ‘title‘:title_text, ‘img_list‘:img_url } return data_dic # 连接数据库,将爬取的信息存储到数据库 def mongo_db_conn(data): from pymongo import MongoClient try: conn = MongoClient(‘localhost‘,27017) db = conn.maoyan collection = db.img_data collection.insert_one(data) except: print(‘数据未写入‘) conn.close() # 主函数 def main(url): i = 0 for offset in range(0,121,20): html = get_response(url,str(offset)) dic_data = loads_python(html) for each_url in get_data(dic_data): i += 1 print(i, each_url) each_html = get_each_html(each_url) result = handle_detail_html(each_html,each_url) mongo_db_conn(result) print(i,result) if __name__ == ‘__main__‘: # 初始url url = ‘https://www.toutiao.com/search_content/‘ main(url)
爬取今日头条历史图集将信息保存到MongDB,并且下载图片到本地
标签:file pre 服务 分享图片 参数 下载图片 鼠标 request请求 family
原文地址:https://www.cnblogs.com/scorpionSpace/p/9277711.html