标签:文本文件 buffer 分布 日志采集 com oca conf try 获取
Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的软件。
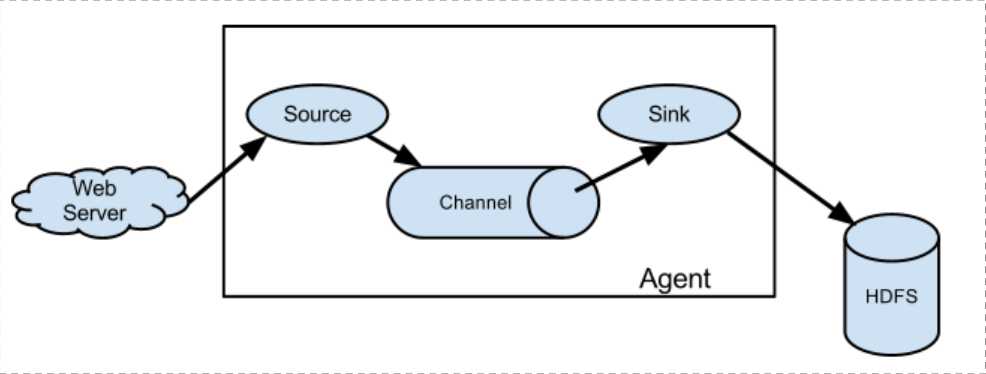
Flume 的核心是把数据从数据源(source)收集过来,再将收集到的数据送到指定的目的地(sink)。为了保证输送的过程一定成功,在送到目的地(sink)之前,会先缓存数据(channel),待数据真正到达目的地(sink)后,flume 在删除自己缓存的数据。
Flume 支持定制各类数据发送方,用于收集各类型数据;同时,Flume 支持定制各种数据接受方,用于最终存储数据。一般的采集需求,通过对 flume 的简单配置即可实现。针对特殊场景也具备良好的自定义扩展能力。因此,flume 可以适用于大部分的日常数据采集场景。
Flume 系统中核心的角色是 agent,agent 本身是一个 Java 进程,一般运行在日志收集节点。
Source:采集源,用于跟数据源对接,以获取数据;
Sink:下沉地,采集数据的传送目的,用于往下一级 agent 传递数据或者往最终存储系统传递数据;
Channel:agent 内部的数据传输通道,用于从 source 将数据传递到 sink;
单个 agent 采集数据
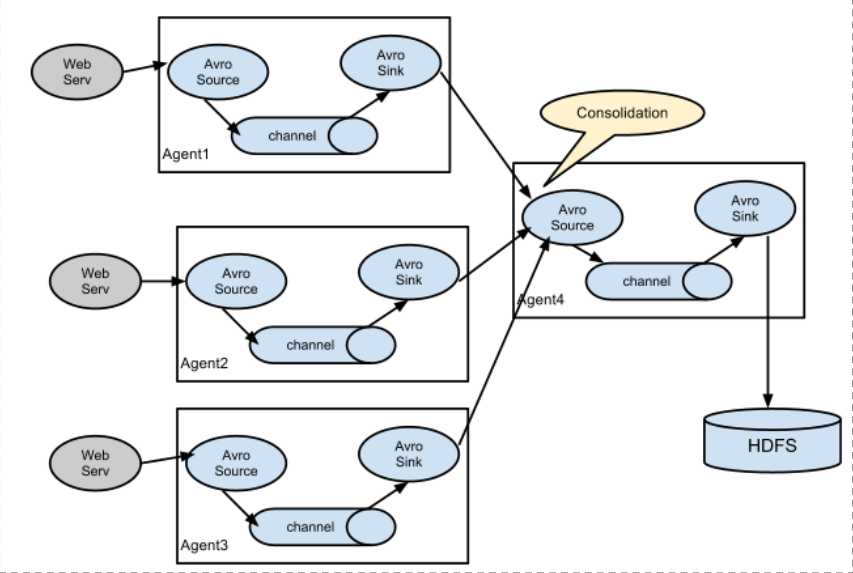
多级 agent 之间串联
tar -zxvf apache-flume-1.6.0-bin.tar.gz
在 flume 的 的 conf 目录下新建一个文件
vi netcat-logger.conf
#从网络端口接收数据,下沉到logger #采集配置文件,netcat-logger.conf # Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
bin/flume-ng agent --conf conf --conf-file conf/netcat-logger.conf --name a1 -Dflume.root.logger=INFO,console
#--conf-file指定采集方案是哪一个(-f)
#--name 给本次flume agent起个名字
#安装telnet
yum install -y telnet
传入数据:
$ telnet localhost 44444
Trying 127.0.0.1...
Connected to localhost.localdomain (127.0.0.1).
Escape character is ‘^]‘.
Hello world! <ENTER>
OK
标签:文本文件 buffer 分布 日志采集 com oca conf try 获取
原文地址:https://www.cnblogs.com/jifengblog/p/9277793.html