标签:解压 apach 环境变量path util 2.0 启动 apache tools.jar png
在win10下搭建spark,需要安装java的jdk,scala,spark,hadoop。
一、安装配置jdk
下载 jdk版本:jdk-8u151-windows-x64.exe
增加2个环境变量:
JAVA_HOME E:\Java\jdk1.8.0_151 (注意,这里把jdk安装的目录,不是C盘的默认目录,路径中不能有空格)
CLASSPATH %JAVA_HOME%\lib;%JAVA_HOME%\lib\tools.jar
在系统环境变量Path中 ,在原来基础上加:%JAVA_HOME%\bin
二、安装配置scala
访问官方地址http://www.scala-lang.org/download/2.11.8.html
下载:scala-2.11.8.msi
在系统环境变量 Path 中,增加:C:\Program Files (x86)\scala\bin
三、安装配置spark
1、下载spark
访问官方地址http://spark.apache.org/downloads.html
下载文件:spark-2.2.0-bin-hadoop2.7.tgz
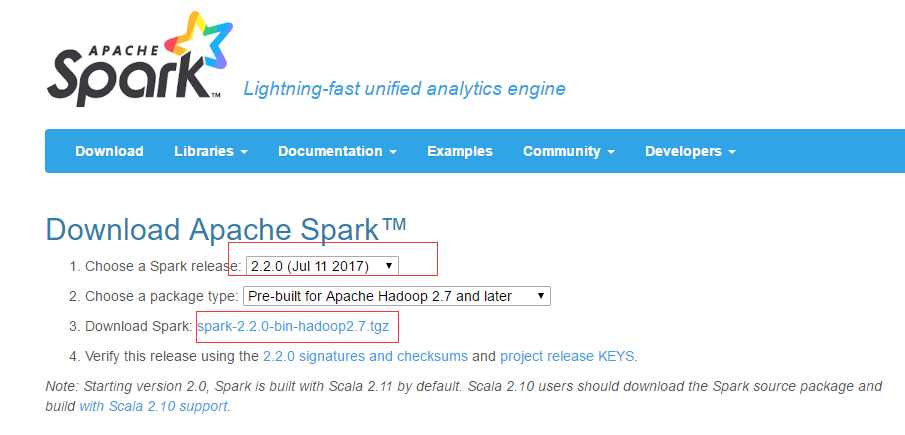
2、解压tgz文件
我把文件解压到目录:D:\spark-2.2.0-bin-hadoop2.7
在这个目录下,有 bin等文件夹。
3、配置
添加系统环境变量:
SPARK_HOME D:\spark-2.2.0-bin-hadoop2.7
在系统环境变量Path增加:%SPARK_HOME%\bin
四、安装配置hadoop
1、下载hadoop
访问官方http://hadoop.apache.org/releases.html
可以下载 2.7.6版的binary文件
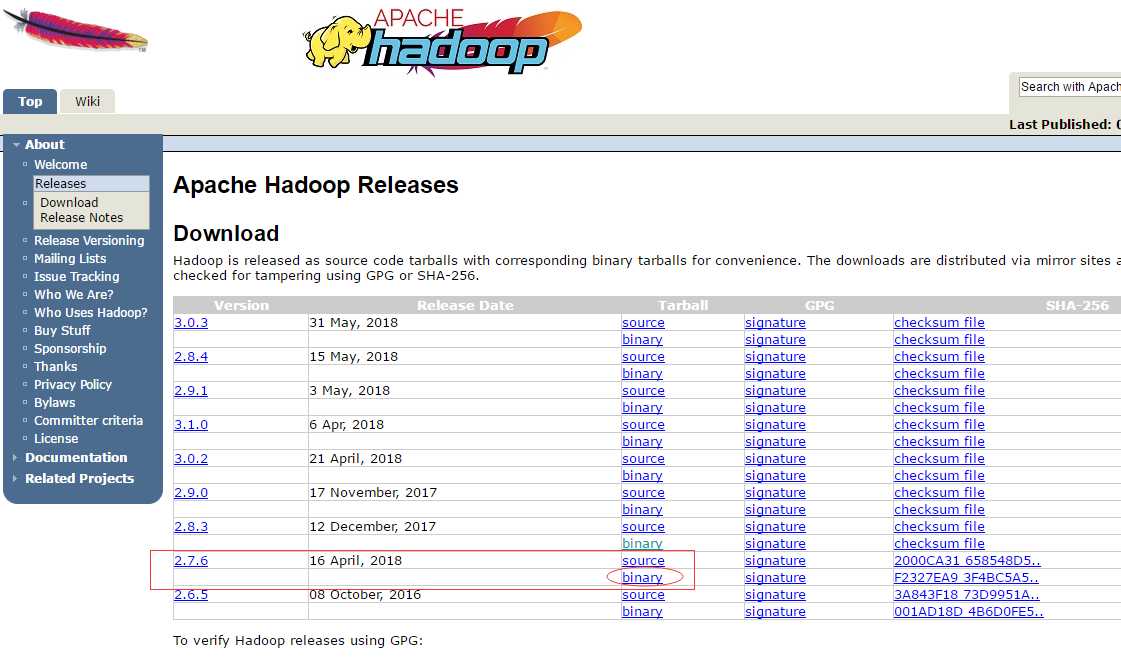
但是,我在安装的时候,直接百度,找了 hadoop2.7.1的压缩文件。
在bin目录中,包含了:hadoop.dll , winutils.exe ,这2个文件就够用了。
然后解压为:D:\hadoop2.7.1
2、配置
增加系统环境变量:
HADOOP_HOME D:\hadoop2.7.1
在系统环境变量Path增加:%HADOOP_HOME%\bin
3、下载winutils
下载路径:https://github.com/steveloughran/winutils
五、配置pyspark
在搭建spark环境之前,安装了Anaconda,包含了python,为了使用pyspark:
1、把 D:\spark-2.2.0-bin-hadoop2.7\python 复制到 E:\Anaconda3\Lib\site-packages 路径下。
2、通过pip install py4j 安装 py4j。
3、修改权限 winutils.exe chmod 777 D:\tmp\Hive,在运行命令前先创建目录 D:\tmp\Hive 。
4、配置
增加系统环境变量: PYTHONPATH %SPARK_HOME%\python\lib\py4j;%SPARK_HOME%\python\lib\pyspark;E:\Anaconda3;
在系统环境变量Path,增加:E:\Anaconda3
六、验证
启动cmd,输入 : pyspark
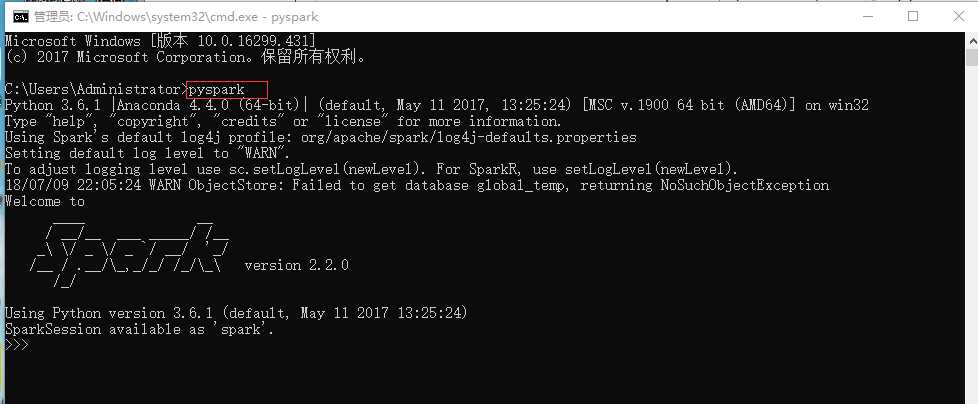
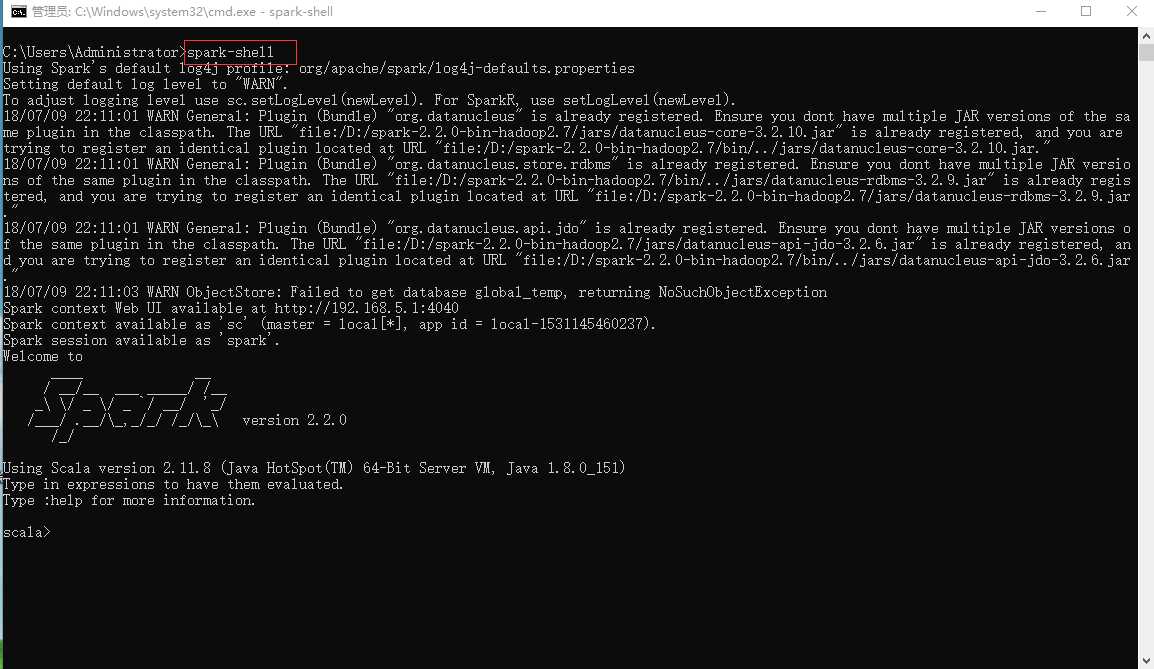
或者输入:spark-shell
标签:解压 apach 环境变量path util 2.0 启动 apache tools.jar png
原文地址:https://www.cnblogs.com/momogua/p/9285930.html