标签:应用 包括 commit 导致 官方文档 联合 跳转 数据 kudu
接触到RAFT是在学习KUDU的时候,KUDU的官方文档中一个连接指向了RAFT;只是觉得这个算法一定有其特点,要知道KUDU可以是一帮HBASE的大神写的。原始开始了解。
RAFT是一致性算法,说到一致性算法很多都会想到zookeeper,是的,这是我们接触比较多的内部包含一致性算法的应用产品了。zookeeper是基于Paxos。RAFT的假想敌无疑就是Paxos,因为RAFT的论文中全文都在那自己和Paxos进行比较。
下图是RAFT的基本架构:
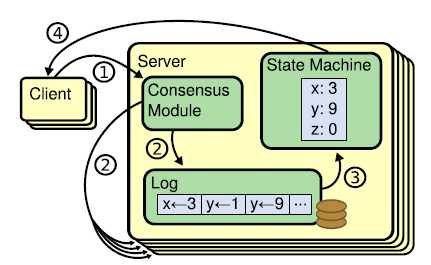
既然是一致性算法,就是要保持存储的数据在各个分布节点保持一致,整体来讲有两种场景需要进行讨论,一种正常情况下,另外一种是异常情况。我们分开来讲。
首先是正常情况,RAFT是leader-follower模式,所有的请求都是有leader进行处理,如果client请求发送到了follower(比如某个leader挂机了,后来又起来了,但是client还是保存了之前的记录,就会仍然请求该节点),将会被转接到leader。
Leader自身将请求处理完毕后(主要是对于数据的操作)将会通过AppendEntries RPC指令向各个follower发送同步信息;这里有一个概念,就是log entry,对于一次数据处理就是一个log entry;每个log entry将会处理一条记录,每个log entry有三个主键:logindex,term以及command,logIndex是log entry的索引,term则是代表一个leader的时代,一个term的开始一次选举,term的结束于一次leader消亡;
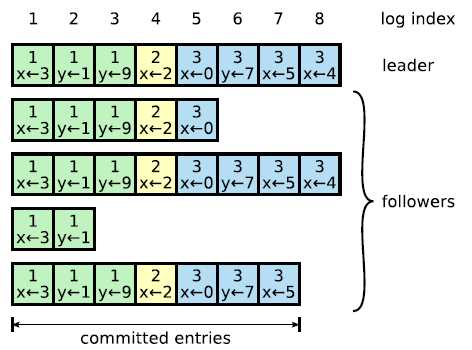
只要有多于一半的机器给予正常相应,那么就认为这条数据的同步是安全状态(safety),这条log entry将会被标记为commited。这种"多于一半"的概念很重要,称之为major servers,包括下面讲述的异常场景处理,都会应用到这个概念。那么为什么是安全状态呢?看到下面的异常场景将会对此进行解释。
作为follower接收到了appendEntries rpc之后,将会首先判断自己的logindex是否能够和该log连续上,如果连续不上则进行拒绝(这个场景多半见于follower离线又上线,或者leader发布还没有完成就挂点,发布还没有波及到该follower),leader将会继续和该follower交互,这次会把logindex降低1,然后看看,直到能够该follower匹配上。
下面讲一下异常场景,所谓的异常场景分为三种情况,分别是leader挂了,follower挂了以及配置变了(机器分布发生变化)。
首先讲leader挂了的场景。上面提到了"多于一半是安全",这是因为即使当前leader挂掉了,再次进行选举,也一定是已经包含这条记录的follower选举成功;RAFT算法里面天然保证一点,如果你接收某个logentry,那么代表这个logentry之前的log你都已经拥有;因为如果你发现接收到的log是不连续,你会和leader沟通,leader将会把能够和你的logindex接续上的log entries(应该是多个)发送给你;选举的规则呢也比较简单,就是比较发送RequestVote RPC(关于RequestVote RPC下面我们会讲到),当且仅当里面包含的logindex以及term和自己一致或者比自己大,才会投票给该Candidate否则拒绝;
所以,一旦某条logentry超过半数已经发布成功;即使这个leader挂了,再次能够选举成功的一定是拥有最后这条log的follower,任何一个follower选举成功后对于进行一次数据同步;RAFT的简洁之处就在这里:永远都只是单向同步,如果follower和leader数据不一致,无论是数据多于leader还是少于leader,都会被leader的日志信息进行覆盖;然后将会保障这条数据将会同步到其他没有这条数据的节点。
这里有一个场景要提下一下,就是一个logentry可能并不是连续的,尽管我们上面到了log entry被保存了就认为是之前都已经OK了。见下图:
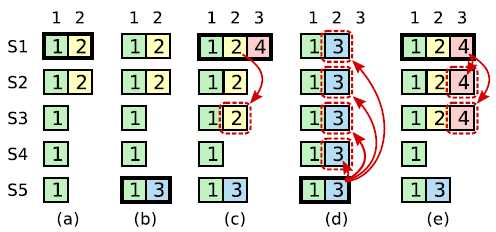
(a),S1是leader,logindex=2还没有形成major servers;(b),s1挂了,S5成为leader;处理了logindex=3的日志;(c),S5挂了,S1成为了leader,接收到了logindex=4以及分发了logindex=2;(d),S1挂了,S5成为Leader进行强行赋值(Overridewrite);于是S1的日志"成功的"被覆盖了。这个例子说明了major server的重要性,S1开始没有保证初始logindex=2处于safty状态,这样就容易被覆盖。
Leader挂了之后,所有的follower将会等待一个election timeout,一旦timeout达到,将会跳转状态为candidate,这里牵涉到了一个状态迁移,见下图;
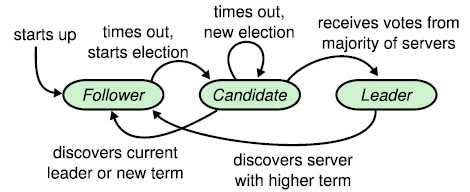
Candidate的发送RequetVote RPC到各个节点进行选举;各个节点接收到之后对比数据,只有至少和自己一样的请求才会投票,而且每台机器只有一票(和美国大选是一样的),那么当这个请求节点总投票数超过半数(包括节点投自己的一票),将会成功选举。如果选举不成功,比如同时进入到Candidate的机器比较多,每个人都只投自己,那么就不会有超过半数,从新进入到选举。为了避免这种分散投票场景(Splite Vote)的发生,RAFT设计为每个follower等待的election timeout时间长短不一样,避免大家同时进入到Candidate状态。一般是150-300ms区间。
Leader成功选举之后,将会进行数据同步上面已经提到了,Leader的数据同步策略是"Overwrite",保持follower的数据和自己同步,这一点也是不同于大部分一致性算法的地方。
如果follower挂了呢?Leader将会不断的向其发送AppendEntries RPC,其实Leader进行replicate的本质是定时发送rpc包,可以说是心跳包;直到这个follower重启之后,接收到了然后判断是否能够接续上,之后处理就和上面描述一样了。
最后一个场景是配置变了,就是当向RAFT集群中增加或者减少节点。如果一次性把所有的节点config进行切换,将会导致同一时间有两套leader,第一种可能是如果新加入的节点数是大于原来机器数量,因为这些机器一段时间没有接收到leader的心跳(leader可能切换比较晚),就会自行进行选组,这些新建加入的设备可能互相就会投票,导致在新的机器范围内新的leader产生;第二种可能是3台机器加入了两台新机器;在切换过程中当两台切换慢,一台切换快,那么这台快的将会和两台新机器成为一套新的群组,两台新机器在没有接收到leader的心跳之后,将会自行选主,于是将会形成一个leader,和就有那三台中leader形成了一个term两个leader。
为了避免这种情况的发生,RAFT做了两件事情;第一件事设计了两阶段的切换过程:首先是分为两个阶段,第一个阶段称之为联合配置阶段(Joint Config)就是Leader保存新的config,但是还是使用老的机器配置;当major Server是接收到了新的config之后,到了第二个阶段,统一切换为新的节点分布进行处理;第二件事情设计了新加入的节点还没有获得leader的log之前是没有投票权的。
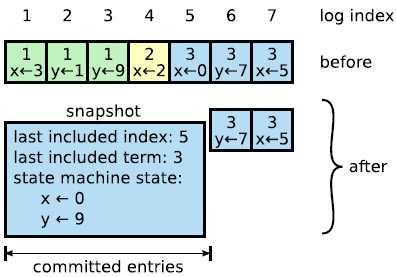
最后说一下RAFT的snapshot,日志如果很大了,其实保留历史记录并不是很有意义,RAFT里面采用的snapshot的模式,对于历史日志记录进行处理,如下图所示。这样只是保留历史某个点的数据,后面再是基于这个点的数据的日志。
RAFT的核心点有两个一个major server,用于数据同步safety判断以及选主。
标签:应用 包括 commit 导致 官方文档 联合 跳转 数据 kudu
原文地址:https://www.cnblogs.com/xiashiwendao/p/9288500.html