标签:contain onclick 取出 syn sys 数组 丢失 play 开始
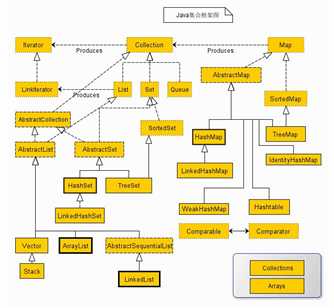
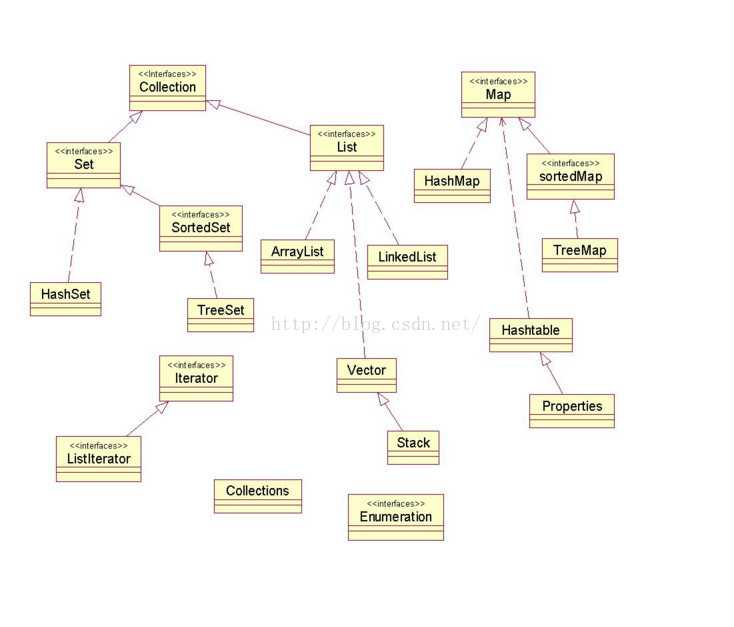
List代表一种线性表的数据结构, List集合是有序集合,集合中的元素可以重复,访问集合中的元素可以根据元素的索引来访问。
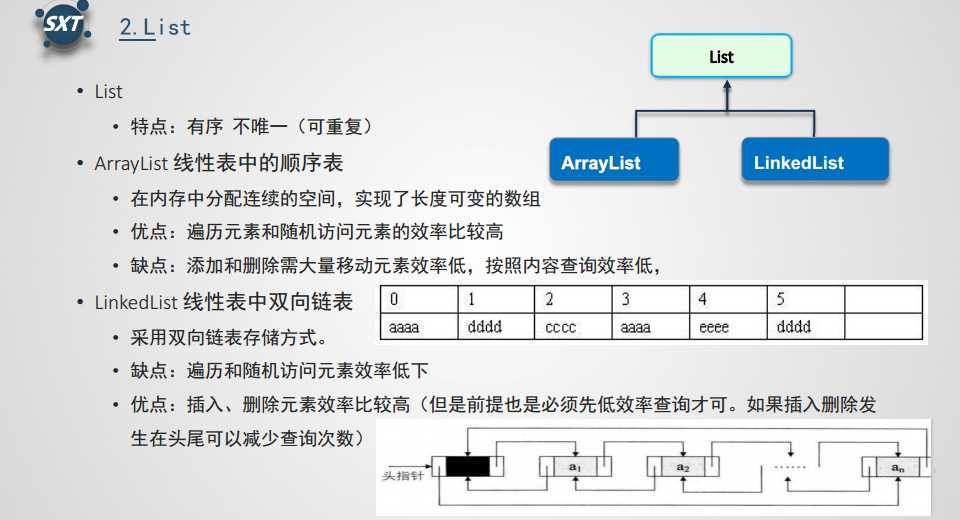
ArrayList则是一种顺序存储的线性表。ArrayList 底层采用数组来保存每个集合元素。线程不安全。ArrayList源码分析
遍历List集合的三种方法
List<String> list = new ArrayList<String>(); list.add("aaa"); list.add("bbb"); list.add("ccc"); //方法一:foreach for(String attribute : list) { System.out.println(attribute); } //方法二:对于ArrayList来说速度比较快, 用for循环, 以size为条件遍历: for(int i = 0 ; i < list.size() ; i++) { System.out.println(list.get(i)); } //方法三:集合类的通用遍历方式, 从很早的版本就有, 用迭代器迭代 Iterator it = list.iterator(); while(it.hasNext()) { System.out.println(it.next()); }
LinkedList 则是一种链式存储的线性表。其本质上就是一个双向链表,但它不仅实现了 List 接口,还实现了 Deque 接口。
也就是说LinkedList既可以当成双向链表使用,也可以当成队列使用,还可以当成栈来使用(Deque 代表双端队列,既具有队列的特征,也具有栈的特征)。线程不安全。

@Test public void test2(){ Queue<String> queue = new LinkedList<String>(); queue.offer("Hello"); queue.offer("World!"); queue.offer("你好!"); System.out.println("队列长度:"+queue.size()); String str; while((str=queue.poll())!=null){ System.out.println(str); } System.out.println("队列长度:"+queue.size()); }
Arraylist和Linklist区别:Java 的 List 集合本身就是线性表的实现,其中 ArrayList是线性表的顺序存储实现;而 LinkedList 则是线性表的链式存储实现。
1、Arraylist(优点):它是实现了基于动态数组的数据结构,因为地址连续,一旦数据存储好了,查询操作效率会比较高(在内存里是连着放的)。
(缺点):因为地址连续, ArrayList要移动数据,所以插入和删除操作效率比较低。
2、Linklist(优点):LinkedList基于链表的数据结构,地址是任意的,所以在开辟内存空间的时候不需要等一个连续的地址,对于新增和删除操作add和remove,LinedList比较占优势。
LinkedList 适用于要头尾操作或插入指定位置的场景
(缺点):因为LinkedList要移动指针,所以查询操作性能比较低。
适用场景分析:当需要对数据进行多次访问的情况下选用ArrayList,当需要对数据进行多次增加删除修改时采用LinkedList。
Vector向量类具体类:底层数据结构是数组。线程安全。
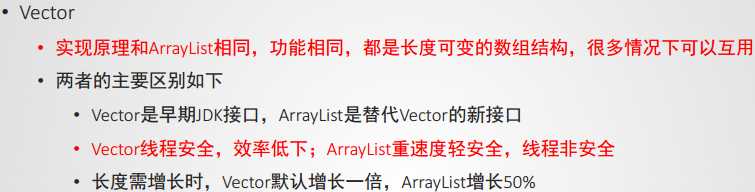
Vector 其实就是 ArrayList 的线程安全版本, ArrayList 和 Vector 绝大部分方法的实现都是相同的,只是 Vector 的方法增加了 synchronized 修饰。
ArrayList 的序列化实现比 Vector 的序列化实现更安全,因此 Vector 基本上已经被ArrayList 所代替了。 Vector 唯一的好处是它是线程安全的。
Stack具体类
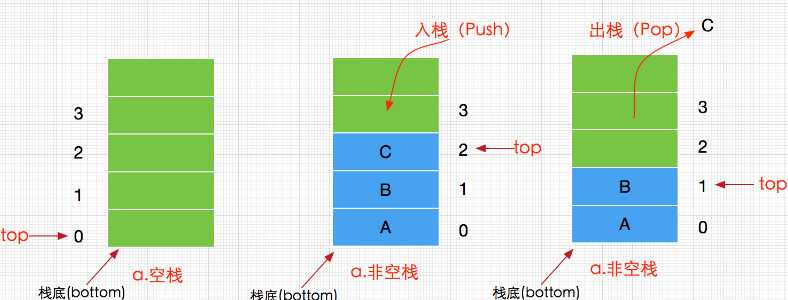
public class Stack<E> extends Vector<E>
@Test public void test2(){ Stack<String> stack = new Stack<String>(); System.out.println("now the stack is " + isEmpty(stack)); stack.push("1"); stack.push("2"); stack.push("3"); stack.push("4"); stack.push("5"); System.out.println("now the stack is " + isEmpty(stack)); System.out.println(stack.peek()); //peek 不改变栈的值(不删除栈顶的值) System.out.println(stack.pop()); //pop会把栈顶的值删除 System.out.println(stack.search("1")); //方法调用返回从堆栈中,对象位于顶部的基于1的位置。 } public static String isEmpty(Stack<String> stack) { return stack.empty() ? "empty" : "not empty"; }
Deque双端队列
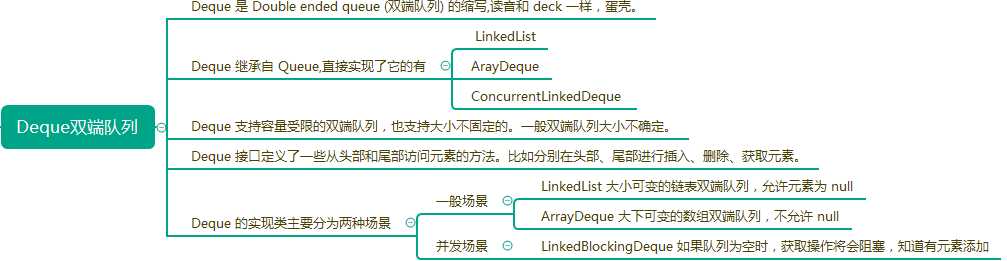
Java 也不再推荐使用 Stack 类,而是推荐使用 Deque 实现类。
在无需保证线程安全的情况下,程序完全可以使用ArrayDueue来代替Stack 类。
从 JDK 1.6 开始,Java 为 Deque提供了一个常用的实现类ArrayDeque。就像List集合拥有 ArrayList 实现类一样,Deque集合则拥有ArrayDeque 实现类。
@Test public void test1() { ArrayDeque stack = new ArrayDeque(); // 依次将三个元素push入“栈”,先进后出 stack.push("疯狂Java讲义"); stack.push("轻量级Java EE企业应用实战"); stack.push("疯狂Android讲义"); System.out.println(stack); // [疯狂Android讲义, 轻量级Java EE企业应用实战, 疯狂Java讲义] System.out.println(stack.peek()); // 疯狂Android讲义 System.out.println(stack); // [疯狂Android讲义, 轻量级Java EE企业应用实战, 疯狂Java讲义] System.out.println(stack.pop()); // 疯狂Android讲义 System.out.println(stack);// [轻量级Java EE企业应用实战, 疯狂Java讲义] // 当做队列来使用,先进先出 ArrayDeque queue = new ArrayDeque(); queue.offer("疯狂Java讲义"); queue.offer("轻量级JavaEE企业应用实践"); queue.offer("疯狂Android讲义"); System.out.println(queue); // [疯狂Java讲义, 轻量级JavaEE企业应用实践, 疯狂Android讲义] // 访问队列头部元素,但不将其poll出队列 System.out.println(queue.peek()); System.out.println(queue); // poll出第一个元素 System.out.println(queue.poll()); System.out.println(queue);// [轻量级JavaEE企业应用实践, 疯狂Android讲义] }
Deque 接口代表双端队列这种数据结构。 双端队列已经不再是简单的队列了,它既具有队列的性质先进先出( FIFO),也具有栈的性质( FILO),也就是说双端队列既是队列,也是栈。
@Test public void test1(){ Deque<String> deque = new LinkedList<String>(); deque.add("d"); deque.add("e"); deque.add("f"); //从队首取出元素,不会删除 System.out.println("队首取出元素:"+deque.peek()); System.out.println("队列为:"+deque); //从队首加入元素(队列有容量限制时用,无则用addFirst) deque.offerFirst("c"); System.out.println("队首加入元素后为:"+deque); //从队尾加入元素(队列有容量限制时用,无则用addLast) deque.offerLast("g"); System.out.println("队尾加入元素后为:"+deque); //队尾加入元素 deque.offer("h"); System.out.println("队尾加入元素后为:"+deque); //获取并移除队列第一个元素,pollFirst()也是,区别在于队列为空时,removeFirst会抛出NoSuchElementException异常,后者返回null deque.removeFirst(); System.out.println("获取并移除队列第一个元素后为:"+deque); //获取并移除队列第一个元素,此方法与pollLast 唯一区别在于队列为空时,removeLast会抛出NoSuchElementException异常,后者返回null deque.removeLast(); System.out.println("获取并移除队列最后一个元素后为:"+deque); //获取队列第一个元素.此方法与 peekFirst 唯一的不同在于:如果此双端队列为空,它将抛出NoSuchElementException,后者返回null System.out.println("获取队列第一个元素为:"+deque.getFirst()); System.out.println("获取队列第一个元素后为:"+deque); //获取队列最后一个元素.此方法与 peekLast 唯一的不同在于:如果此双端队列为空,它将抛出NoSuchElementException,后者返回null System.out.println("获取队列最后一个元素为:"+deque.getLast()); System.out.println("获取队列第一个元素后为:"+deque); //循环获取元素并在队列移除元素 while(deque.size()>0){ System.out.println("获取元素为:"+ deque.pop()+" 并删除"); } System.out.println("队列为:"+deque); }
继承关系是:deque => queue => collection=》Iterable
1.使用队列的时候,new LinkedList的时候为什么用deque接收,不用LinkedList呢?
答:deque继承queue接口,因为它有两个实现,LinkedList与ArrayDeque。用deque接收是因为向上转型(子类往父类转,会丢失子类的特殊功能)了。可以试试,用get()方法,LinkedList接收才有。
2.为什么有一个实现还不够,还弄两个呢,它们总有区别吧?
答:ArrayDeque是基于头尾指针来实现的Deque,意味着不能访问除第一个和最后一个元素。想访问得用迭代器,可以正反迭代。
ArrayDeque一般优于链表队列/双端队列,有限数量的垃圾产生(旧数组将被丢弃在扩展),建议使用deque,ArrayDeque优先。
Set集合是无序集合,集合中的元素不可以重复,访问集合中的元素只能根据元素本身来访问(也是不能集合里元素不允许重复的原因)。
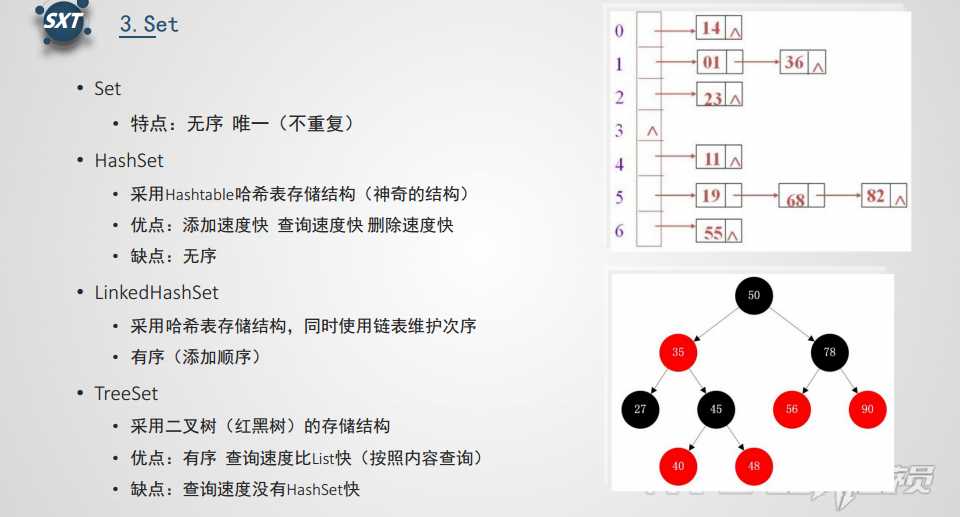
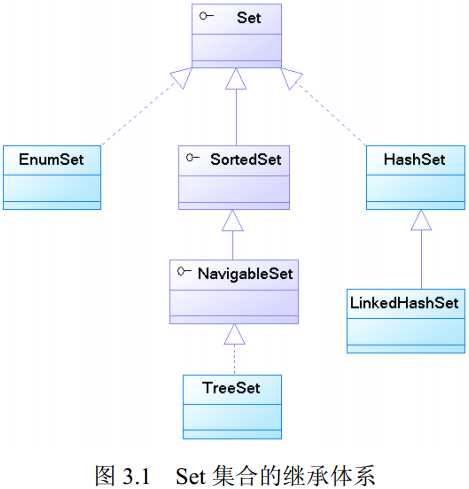
HashSet集合:底层数据结构是哈希表(是一个元素为链表的数组)
如何正确地重写某个类的 hashCode()方法和 equals()方法?
TreeSet集合:底层数据结构是红黑树(是一个自平衡的二叉树);保证元素的排序方式
LinkedHashSet集合:底层数据结构由哈希表和链表组成。
Map集合中保存Key-value对形式的元素,访问时只能根据每项元素的key来访问其value。
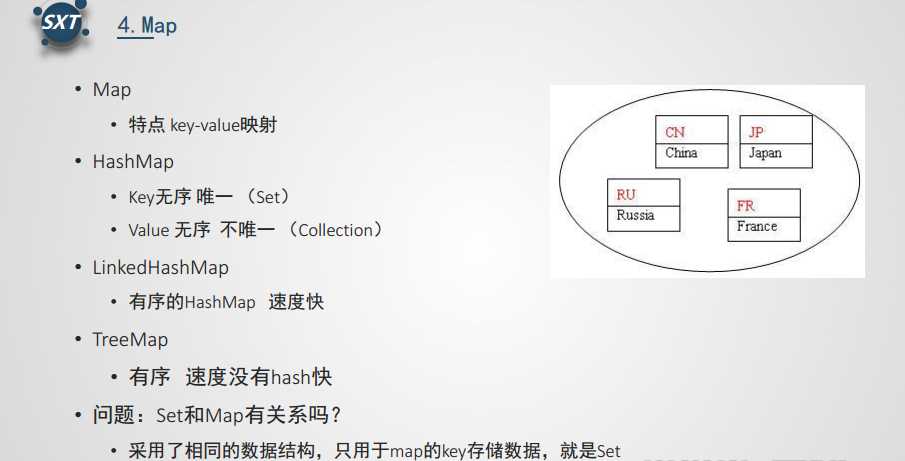
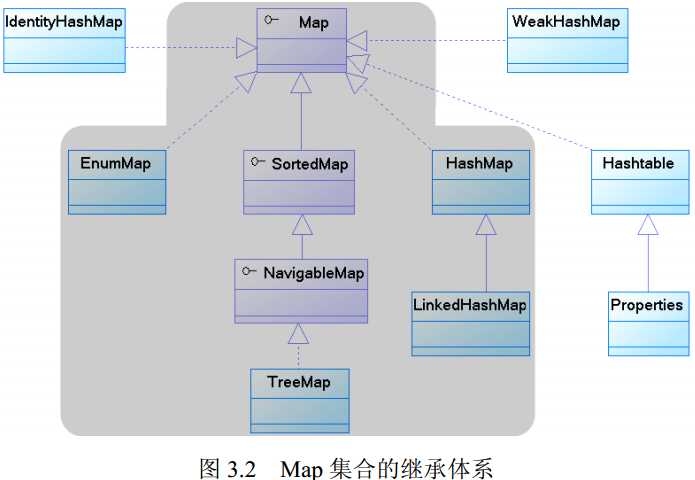
HashMap类
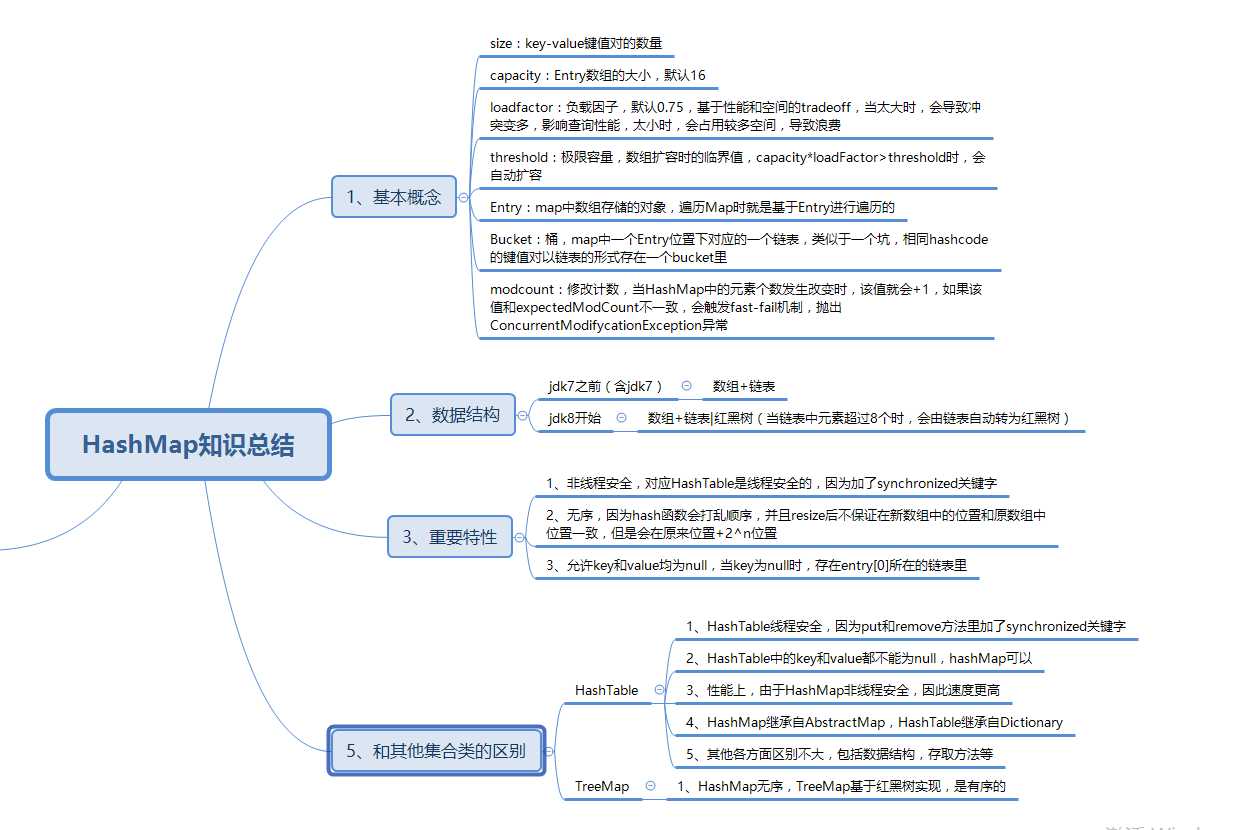
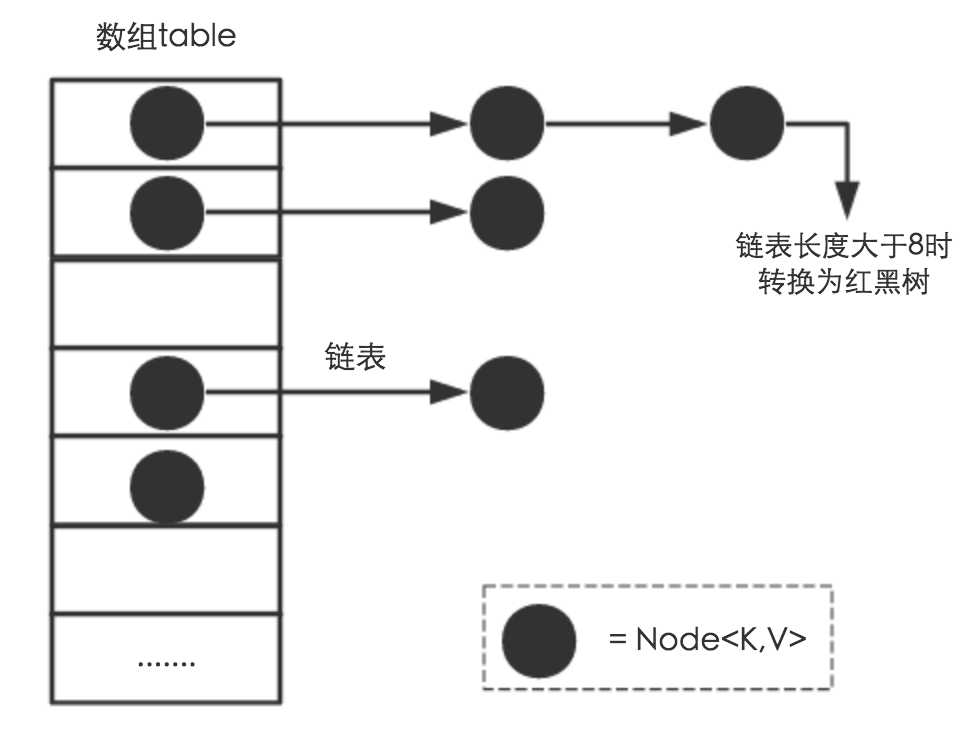
HashMap是数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的。
当创建 HashMap 时,有一个默认的负载因子( load factor),其默认值为 0.75。这是时间和空间成本上的一种折衷:增大负载因子可以减少 Hash 表(就是那个 Entry 数组)所占用的内存空间,
但会增加查询数据的时间开销,
而查询是最频繁的的操作 ( HashMap 的 get()与 put()方法都要用到查询);减小负载因子会提高数据查询的性能,但会增加 Hash 表所占用的内存空间。
package com.pb.collection; import java.util.HashMap; import java.util.Iterator; import java.util.Set; import java.util.Map.Entry; public class HashMapDemo { public static void main(String[] args) { HashMap<String, String> hashMap = new HashMap<String, String>(); hashMap.put("cn", "中国"); hashMap.put("jp", "日本"); hashMap.put("fr", "法国"); System.out.println(hashMap); System.out.println("cn:" + hashMap.get("cn")); System.out.println(hashMap.containsKey("cn")); System.out.println(hashMap.keySet()); System.out.println(hashMap.isEmpty()); hashMap.remove("cn"); System.out.println(hashMap.containsKey("cn")); //采用Iterator遍历HashMap Iterator it = hashMap.keySet().iterator(); while(it.hasNext()) { String key = (String)it.next(); System.out.println("key:" + key); System.out.println("value:" + hashMap.get(key)); } //遍历HashMap的另一个方法 Set<Entry<String, String>> sets = hashMap.entrySet(); for(Entry<String, String> entry : sets) { System.out.print(entry.getKey() + ", "); System.out.println(entry.getValue()); } } }
LinkedHashMap类
Hashtable

TreeMap类
对于 TreeMap 而言,它采用一种被称为“红黑树”的排序二叉树来保存 Map中每个Entry—每个 Entry 都被当成“红黑树”的一个节点对待。
迭代器是一种设计模式,它是一个对象,它可以遍历并选择序列中的对象,而开发人员不需要了解该序列的底层结构。迭代器通常被称为“轻量级”对象,因为创建它的代价小。
Java中的Iterator功能比较简单,并且只能单向移动:
(1) 使用方法iterator()要求容器返回一个Iterator。第一次调用Iterator的next()方法时,它返回序列的第一个元素。注意:iterator()方法是java.lang.Iterable接口,被Collection继承。
(2) 使用next()获得序列中的下一个元素。
(3) 使用hasNext()检查序列中是否还有元素。
(4) 使用remove()将迭代器新返回的元素删除。
Iterator是Java迭代器最简单的实现,为List设计的ListIterator具有更多的功能,它可以从两个方向遍历List,也可以从List中插入和删除元素。
迭代器应用:
list l = new ArrayList(); l.add("aa"); l.add("bb"); l.add("cc"); for (Iterator iter = l.iterator(); iter.hasNext();) { String str = (String)iter.next(); System.out.println(str); } //迭代器用于while循环 Iterator iter = l.iterator(); while(iter.hasNext()){ String str = (String) iter.next(); System.out.println(str); }

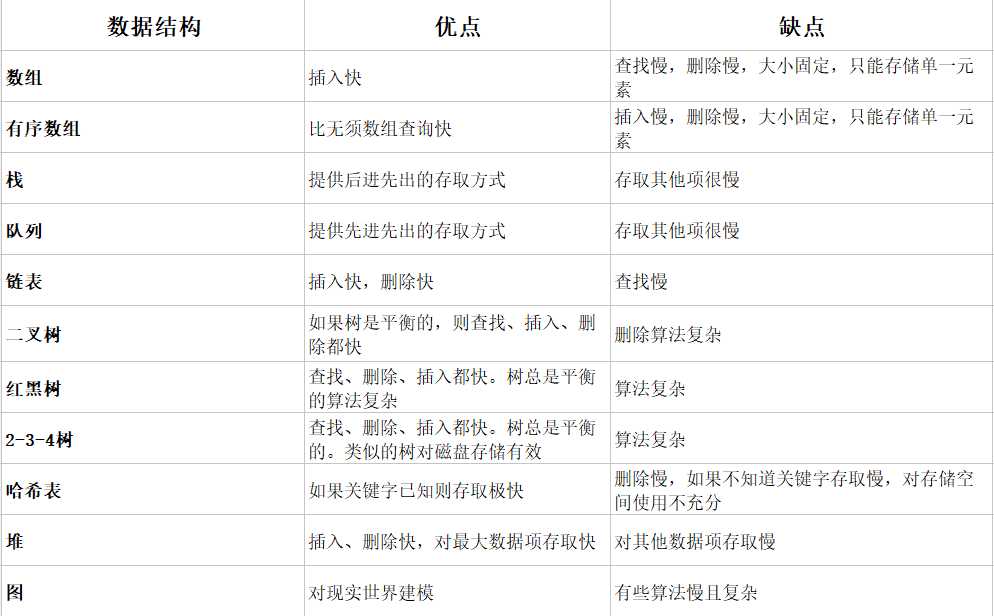
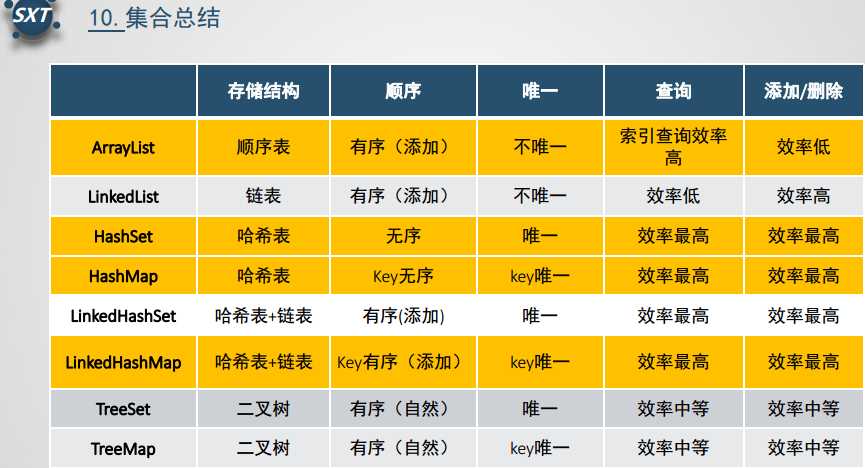
关于集合中List、Map、Set这三个的总结如下:
List:List和数组类似,可以动态增长,根据实际存储的数据的长度自动增长List的长度。查找元素效率高,插入删除效率低,因为会引起其他元素位置改变 。
ArrayList:非线程安全,适合随机查找和遍历,不适合插入和删除。
LinkedList : 非线程安全,适合插入和删除,不适合查找。
Vector : 线程安全。不过不推荐。
Map:一个key到value的映射的类 。
HashMap:非线程安全,键和值都允许有null值存在。
TreeMap:非线程安全,按自然顺序或自定义顺序遍历键(key)。
LinkedHashMap:非线程安全,维护一个双链表,可以将里面的数据按写入的顺序读出。写入比HashMap强,新增和删除比HashMap差。
Hashtable:线程安全,键和值不允许有null值存在。不推荐使用。
ConcurrentHashMap:线程安全,Hashtable的升级版。推荐多线程使用。
Set:不允许重复的数据 。检索效率低下,删除和插入效率高。
HashSet: 非线程安全、无序、数据可为空。
TreeSet: 非线程安全、有序、数据不可为空。
LinkedHashSet:非线程安全、无序、数据可为空。写入比HashSet强,新增和删除比HashSet差。
虽然集合号称存储的是 Java 对象,但实际上并不会真正将 Java 对象放入 Set 集合中,而只是在 Set 集合中保留这些对象的引用而已。
也就是说,Java 集合实际上是多个引用变量所组成的集合,这些引用变量指向实际的 Java 对象。
就像引用类型的数组一样,当把 Java 对象放入数组之时,并不是真正把 Java 对象放入数组中,而只是把对象的引用放入数组中,每个数组元素都是一个引用变量。
对于每个 Java 集合来说,其实它只是多个引用变量的集合.
资料
http://www.cnblogs.com/Java3y/p/8782788.html
https://www.cnblogs.com/Java3y/p/8808818.html
()Java入门系列(七)Java 集合框架(JCF, Java Collections Framework)
标签:contain onclick 取出 syn sys 数组 丢失 play 开始
原文地址:https://www.cnblogs.com/cnki/p/6727183.html
