标签:span 解决 back 长度 保存 length 可变 font 就是
电脑的传输, 还有储存的实际都是01010101010
美国 :ascii码 只能表示256可能,太少
为了解决这个全球化的文字问题,创建了万国码,unicode
中文有9万多字,16位表示一个字符不够用,32位表示一个字符
A 0100 0001 0100 0001 0100 0001 0100 0001
ascii 码 : 1个字节表示所有的英文,特殊字符,数字等等
unicode : 2个字节,16位表示一个中文,不够用。Unicode一个中文要用四个字节表示
Unicode 升级 utf-8(一个中文要用3个字节去表示) utf-16 utf- 32
00000001 8位 == 1个字节byte
1byte 1024byte == 1kb
1kb 1024kb == 1MB
1MB 1024MB == 1GB
1GB 1GB == 1YB
utf-8 一个字符最少用8位去表示:
英文用8位 一个字节表示
欧洲文字用16位去表示 两个字节表示
中文用24 位去表示 三个字节表示
utf-16 一个字符最少用16位去表示
gbk国内使用,一个中文用两个字节 (中国国产,只能用于中文和ascii码中的文字)
gbk和utf-8只能通过unicode进行互换。
在python3中所有的整数都是int类型. 但在python2中如果数据量比较大. 会使用long类型. 在python3中不存在long类型
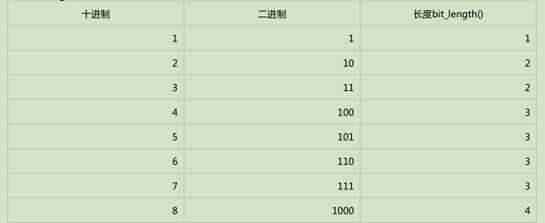
bit_length() 计算整数在内存中占用的二进制码的长度

bool 类型转换 :
1. 你想转换成什么. 就用什么把目标包裹起来
2. 带空的是False, 不带空的True
取值只有True, False. bool值没有操作.
转换问题:
str => int int(str)
int => str str(int)
int => bool bool(int). 0是False 非0是True
bool=>int int(bool) True是1, False是0
str => bool bool(str) 空字符串是False, 不空是True
bool => str str(bool) 把bool值转换成相应的"值"
在python中用‘, ", ‘‘‘, """引起来的内容被称为字符串.
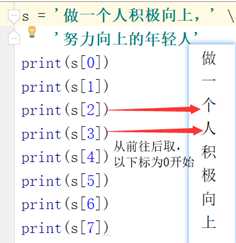
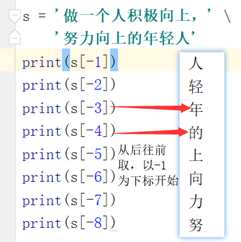
1. 索引:
索引就是下标. 切记, 下标从0开始。
起始位置下标是0(从左到右),-1(从右到左)

4.2.切片:
切片就是通过索引(索引:索引:步长)截取字符串的一段,形成新的字符串
原则:顾头不顾尾
4.2.1按着顺序切(从左到右 或 从右到左) 语法:str[start:end]

2.2跳着截取
步长: 如果是整数, 则从左往右取. 如果是负数. 则从右往左取. 默认是1
切片语法:
Str[start:end:step] Start:起始位置 end:结束位置 step:步长

字符串的操做
切记, 字符串是不可变的对象, 所以任何操作对原字符串是不会有任何影响的
标签:span 解决 back 长度 保存 length 可变 font 就是
原文地址:https://www.cnblogs.com/mwhylj/p/9292143.html