标签:afn uml title 分享 btree lines ring ota __name__
1912年当时世界上体积最庞大,内部设施最豪华的客运轮船’泰坦尼克号’,拥有美誉‘永不沉没’。然而在第一次下水穿越大西洋时,就在航行中撞上冰山,永远沉没海底。船上丧生者达到1500多人。假如我们穿越时空回到了过去,成为船上的一名普通乘客,那么我们有多大的存活率?试根据船上乘客的各种信息特征来预测一下生存率。
数据可以通过Kggle网站获取,分为测试集合训练集。由于获取的数据,测试集将结果与特征信息分开了。为了便于将统一对测试集合训练集进行清洗,所以首先将原始测试集中的特征信息与结果放入到了同一个文件之中。数据样式如下表一所示:

表1 泰坦尼克号乘客信息表
因为所给的数据之中Age,Embarked,Cabin三个数据集存在元素缺失,根据经验,分别用平均值和众数来填充Age特征,并以20岁为一个年龄阶段来划分年龄段和Embarked特征。Cabin缺失数据较多,根据Cabin的有无将该特征分为两大类。
基于以上对原始数据的初步清洗之后,开始对数据进行可视化分析,并以此来选出有效特征。一般来说,乘客的姓名和船票号码对于乘客的生存率是没有影响的。因为票价与乘客的乘船距离和船舱等级都有关系,因此不作为本预测模的特征。下面通过Python里面的pandas库,对剩余的各个数据特征进行逐一分析。
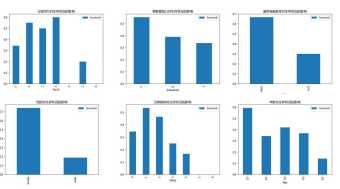
图 1 数据特征可视化分析
由以上图表可以看出来船舱等级和性别,以及是否有船舱对于生存率有较大影响。同时其他特征对于生存状况也有不同程度的影响。所以采用这些特征作为决策树的决策特征。
决策树基本原理很简单,就是通过对一个拥有许多特征的数据集按照某种方式来进行划分,在该种划分模式下得到结果的准确性最高。在树中的每一个结点是对对象属性的一种判断条件,支点表示符合结点的对象,叶子节点表示的是分类结果。构造决策树的过程也就是将数据集进行划分的过程,使得无序的数据变得更加有序。描述数据的混乱程度,可以用信息熵或者称为香农熵的量来定量衡量。当数据越混乱时,信息熵越大。信息熵可以用下列公式进行计算:
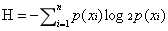
其中xi表示一种分类方式,p(xi)表示该分类的概率。
因此在进行特征选择的时候,需要计算信息增益,也就是混乱度的减少量。信息增益越高,那么对这个特征进行划分也就是最好的方式。选择信息增益最大的方式进行划分。算法的主要步骤如下:
Step1:对数据集每个特征进行划分,计算每种划分后的信息增益
Step2:选出信息增益最大的划分方式对所有特征进行划分
Step3:递归,直到所有特征划分完成。完成决策树的构建
Step4:将生成的数进行可视化,在图形窗口绘出决策树
Step4:利用生成的决策树对测试集进行预测
算法的主要部分代码如图2所示。绘出的决策树和程序运行计算的准确率如下图11.所示。从运行结果来看,预测的准确率较高。但是为了进一步提高算法的有效性,需要采取决策树的剪枝处理。


图 2决策树算法的主要程序
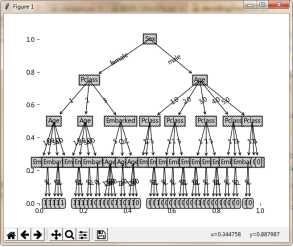
图 3未经剪枝的决策树

图 4未剪枝处理的决策树运行结果
决策树在进行划分的时候,会划分出某些不必要的节点。在划分之后,决策树预测的准确率的期望可能会降低。如果能在划分之前预先看一下是否会出现这样的情况,那么对于算法的优化有很大的帮助。预剪枝的主要思想为:在划分结点时,计算划分之前和划分之后在训练集上的准确率,如果没有提高其在训练集上的准确率则不进行划分。预剪枝的实现主要通过下面两个函数。
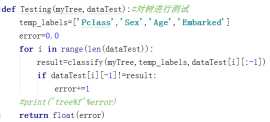
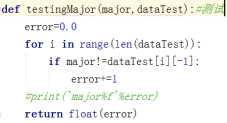
判断结点是否划分用如下方式表达:
if Testing(myTree,dataTest)<testingMajor(majorityCnt(classList),dataTest): return myTree
剪枝处理的结果如图5所示:

图 5剪枝处理之后的运行结果
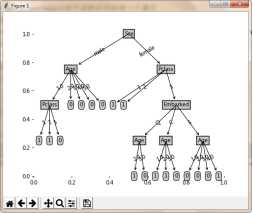
图 6剪枝后的决策树
从运行的结果来看进行过剪枝之后的决策树在形式上显得更加简洁,从准确率来看在算法的效果也更好。
朴素贝叶斯算法是基于概率论,对各个特征出现进行了独立假设的一个算法。假如有两个事件A、B,如果已知A事件发生时B事件的发生概率P(B|A)以及A、B发生的概率P(A)、P(B),那么根据贝叶斯决策理论能计算出在B事件发生的条件下A事件的概率P(A|B).计算公式如下:
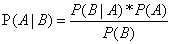
这就是贝叶斯全概率公式。假如数据集有n种不同的分类结果,要判断一个样本B的分类,只需要分别计算它在所有情况下发生的条件概率:
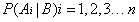
比较它们的大小,找出其中最大的那个概率对应的类别Amax作为该样本的类别。对每个样本都进行相同的分类,这样对每个样本都有最大概率准确判断它的类别。下面是在上述问题的背景下的算法伪代码:
Step1:找出样本中出现的所有特征属性featList,并计算每种类别的概率Pi
Step2:把样本的特征向量转化为以featList相同长度的只包含0、1的向量,其中1代表该 样本中出现了featList中的该属性;0代表没有出现
Step3:计算每种类别的样本每个特征出现的概率
Step4:根据每个样本中的特征属性出现的情况计算它是每种类别的概率选出其中最大的作 为该样本的特征。
Step5:对数据集中所有样本进行分类,计算预测的准确率
准备好数据集之后,对数据进行了测试,结果如图7所示。
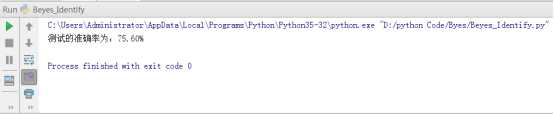
图7 贝叶斯算法运行结果
从测试的结果来看效果并不太好,对训练集和测试集进行互换之后结果相似。计算的准确率不高的原因,应该是在对数据集的使用采用了独立性假设,而实际情况可能会出现两种属性想依赖的关系。目前尚未找到改进算法的方式,这个工作留给以后对概率有了更深的理解之后在研究。
本次实验使用了两个问题的数据集对两个机器学习的分类算法进行了测试和改进,从整体上来看它们都能够达到了预期的目标。在算法思想方面,它们分别从混乱度和概率两个完全不同的角度来对数据集进行分类。事实上在日常的生活之中,我们也会经常用到这两种方法,应用到计算机上也是人类智慧的一个延伸。对于不同的问题需要采用不同的方法,也需要根据实际情况进行合理的改进。在决策树的实现过程中采用了剪枝之后我们发现准确率有了很大的提高,决策树也变得简洁了许多,从而实际意义更大。
对于不同的算法它们共同的难点都在于特征的选取。但是在特征选取之后,即使是相同的数据集,不同算法在具体使用过程所需要考虑的问题也不相同。比如在决策树的构建中对结点进行划分的过程,我们对不能完全划分的点采用投票处理,选概率大的作为样本的标签。而在朴素贝叶斯算法中,在计算全概率的时候使用对数加法代替了惩罚,从而使得计算更加方便。通过对算法的实例操作,不仅能够提高对算法本身的理解,也能从总获取许多思想,并应用到现实生活之中。
1.朴素贝叶斯算法
#本模块用于贝叶斯算法的实现 from numpy import* from math import* import pandas as pd import numpy as np import os ###############___loadTxtDaat__############### def loadData(filePath):#准备数据,输入文件 f=open(filePath)#打开文件 lines=f.readlines() trainData=[]#记录文档数组 trainLabel=[]#记录类标签 for line in lines: Line=line.strip(‘\n‘) data=Line.split(‘\t‘) trainLabel.append(data[-1]) trainData.append(data[:-1]) return trainData,trainLabel def creatVocabList(dataSet):#创建包含所有出现特征的数据集,需要将数字转化为字符处理 vocabSet=set([])#创建一个空集 for document in dataSet: vocabSet=vocabSet|set(document)#创建两个集合的并 return list(vocabSet) def setOfWords2Vec(vocabList,inputSet):#将文本转化为数字列表 returnVec=[0]*len(vocabList)#创建一个其中所含元素都为0的向量 for word in inputSet: if word in vocabList: returnVec[vocabList.index(word)]=1 return returnVec def bagOfWords2Vec(vocabList,inputSet):#袋装模型,也记录下每个词出现的个数 returnVec=[0]*len(vocabList)#信件一个长度为len(vocabList)的0列表 for word in inputSet: if word in vocabList: returnVec[vocabList.index[word]]+=1 return returnVec ###############_创建有大于2中类别的数据__######################## def trainNB(trainMatrix,trainCategory):#输出特征概率数组,每种类别出现的概率 Class=set(trainCategory)#存储所有类别 Class=[data for data in Class] classNum=len(Class)#类别的个数 numTrainDoc=len(trainMatrix)#样本集的个数 numWord=len(trainMatrix[0])#特征的个数 count=array([0]*classNum)#建立一个空列表存储所有类别出现次数的数据 for i in range(classNum):#计算每个类别出现的个数 for j in range(len(trainCategory)): if trainCategory[j]==Class[i]: count[i]+=1 pClass=count/numTrainDoc#计算每种类别的概率 pNum=[ones(numWord) for i in range(classNum)]#为每种类别创建一个保存特征数目的向量 pDenom=[2 for i in range(classNum)]#为每个类别创建一个记录元素总数的向量 for k in range(numTrainDoc): for i in range(classNum): if trainCategory[k]==Class[i]: pNum[i]+=trainMatrix[k] pDenom+=sum(trainMatrix[k]) pVect=[[] for i in range(classNum)] for i in range(classNum):#计算每个特征出现的概率 pVect[i]=vectorize(log)(pNum[i]/pDenom[i]) return pVect,pClass,Class ########################__classify__################# def classifyNB(vec2Calssify,pVec,pClass,Class): p=[0]*len(pClass) for i in range(len(pClass)): p[i]=sum(vec2Calssify*pVec[i])+log(pClass[i]) idx=p.index(max(p)) return Class[idx] #################__test__########################### def testingNB(trainData,trainLabel,testData,testLabel):#贝叶斯测函数,输出测试的准确率 myVocabList=creatVocabList(trainData) trainMat=[] for daat in trainData: trainMat.append(setOfWords2Vec(myVocabList,daat)) pVect,pClass,Class=trainNB(array(trainMat),array(trainLabel)) count=0 for i in range(len(testData)): thisDoc=array(setOfWords2Vec(myVocabList,testData[i])) label=classifyNB(thisDoc,pVect,pClass,Class) if label==testLabel[i]: count+=1 corRate=100*count/len(testData) print(‘测试的准确率为:%.2f%%‘%float(corRate)) return corRate ########################__getCsvData__############################### def get_data(filename):#清洗数据,获取可以使用的数据 dataSet=pd.read_csv(filename) mean=dataSet[‘Age‘].mean()#用平均值代替空缺的年龄 dataSet=dataSet.fillna({‘Cabin‘:‘Lost‘,‘Age‘:mean,‘Embarked‘:‘S‘})#处理完Cabin,Embarked dataSet[‘Age‘]=(dataSet[‘Age‘]/20).apply(np.round)+1 label=dataSet[‘Survived‘].values.tolist() dataSet=dataSet.drop([‘Name‘,‘PassengerId‘,‘Fare‘,‘Ticket‘,‘Survived‘,‘SibSp‘,‘Parch‘],axis=1)#删除不需要的列 dataSet.ix[dataSet[‘Cabin‘]!=‘Lost‘,‘Cabin‘]=‘Have‘#修改数据 vecData=dataSet.values.tolist() return vecData,label def main(): trainFile=r‘E:\PythonData\tatanic\train.csv‘ testFile=r‘E:\PythonData\tatanic\test.csv‘ trainData,trainLabel=get_data(trainFile) testData,testLabel=get_data(testFile) testingNB(trainData,trainLabel,testData,testLabel) if __name__==‘__main__‘: main()
2.决策树算法
#dataAnalize import pandas as pd import matplotlib.pyplot as plt import numpy as np dataSet=pd.read_csv(‘E:\\PythonData\\tatanic\\train.csv‘) mean=dataSet[‘Age‘].mean()#用平均值代替空缺的年龄 dataSet=dataSet.fillna({‘Cabin‘:‘Lost‘,‘Age‘:mean,‘Embarked‘:‘S‘})#处理完Cabin,Embarked dataSet[‘Age‘]=(dataSet[‘Age‘]/20).apply(np.round)+1#年龄按20岁分成不同阶段 dataSet.ix[dataSet[‘Cabin‘]!=‘Lost‘,‘Cabin‘]=‘Have‘ #1、总体分析 #print(dataSet.describe())#观察样本总体数据情况 #2、船舱等级对乘客生存状况的影响 s_Pclass=pd.pivot_table(dataSet,index=‘Pclass‘,values=‘Survived‘,aggfunc=[np.sum,len,np.mean]) s_Pclass[‘mean‘].plot(kind=‘Bar‘) plt.title(‘创仓等级对生存状况的影响‘) #3.性别对乘客生存状况的影响 s_Sex=pd.pivot_table(dataSet,index=‘Sex‘,values=‘Survived‘,aggfunc=[np.sum,len,np.mean]) s_Sex[‘mean‘].plot(kind=‘Bar‘) plt.title(‘性别对生存状况的影响‘) #4、年龄对生存状况的影响 s_Age=pd.pivot_table(dataSet,index=‘Age‘,values=‘Survived‘,aggfunc=[np.sum,len,np.mean]) s_Age[‘mean‘].plot(kind=‘Bar‘) plt.title(‘年龄对生存状况的影响‘) #5、兄弟姐妹个数对生存状况的影响 s_SibSp=pd.pivot_table(dataSet,index=‘SibSp‘,values=‘Survived‘,aggfunc=[np.sum,len,np.mean]) s_SibSp[‘mean‘].plot(kind=‘Bar‘) plt.title(‘兄弟姐妹对生存状况的影响‘) #6、父母同行对生存状况的影响 s_Parch=pd.pivot_table(dataSet,index=‘Parch‘,values=‘Survived‘,aggfunc=[np.sum,len,np.mean]) s_Parch[‘mean‘].plot(kind=‘Bar‘) plt.title(‘父母同行对生存状况的影响‘) #7、登陆口对生存状况的影响 s_Embarked=pd.pivot_table(dataSet,index=‘Embarked‘,values=‘Survived‘,aggfunc=[np.sum,len,np.mean]) s_Embarked[‘mean‘].plot(kind=‘Bar‘) plt.title(‘乘客登陆口对生存状况的影响‘) #8、是否有船舱号对生存状况的影响 s_Cabin=pd.pivot_table(dataSet,index=‘Cabin‘,values=‘Survived‘,aggfunc=[np.sum,len,np.mean]) s_Cabin[‘mean‘].plot(kind=‘Bar‘) plt.title(‘是否有船舱号对生存状况的影响‘) plt.show()
#decidingTree ‘‘‘ 本例我们依然使用tatanic数据集用来训练决策树,这是一个原始模型,没有对决策树进行剪枝操作。 第一步对数据进行整体分析,选取特征。经分析,发现可以利用的特征有:Sex,Age,Embarked,Cabin,Parch,Sibsp ,Pclass.需要剔除的有PassangerId,Fare,Name,Ticket。所选特征中需要清洗的数据有Age,Cabin,Parch,Embarked 运算结果:准确率为85%左右 ‘‘‘ ######__导入库__############# import operator import pandas as pd from numpy import* import numpy as np from pandas import Series,DataFrame import pickle from treePlotter import* from math import log import time import copy #############################__代码区__############################### #########__为构建树准备__######### #计算数据集的香农熵,香农熵越小说明数据集的混乱度越小 def calcShannonEnt(dataSet):#计算香农熵的函数 numEntries=len(dataSet)#计算数据集中实例的总数 labelCounts={}#创建一个字典 for featVec in dataSet:#对于dataSet中的每个数据 currentLabel=featVec[-1]#currentLabel储存当前该数据的标签 if currentLabel not in labelCounts.keys():#如果标签不在labelCout字典中 labelCounts[currentLabel]=0 labelCounts[currentLabel]+=1 shannonEnt=0.0 for key in labelCounts: prob=float(labelCounts[key])/numEntries shannonEnt-=prob*log(prob,2) return shannonEnt #数据类型如下所示 def creatDataSet(): dataSet=[[1,1,‘yes‘], [1,1,‘yes‘], [1,0,‘no‘], [0,1,‘no‘], [0,1,‘no‘]] labels=[‘no surfacing‘,‘flippers‘] return dataSet,labels #多数据集按照第axis中的value属性进行划分 def splitDataSet(dataSet,axis,value): retDataSet=[] for featVec in dataSet: if featVec[axis]==value: #下面两行用来确定出去featVec[axis]之外的其他元素。 reducedFeatVec=featVec[:axis]#表示featVec[0],[1]...[axis-1] reducedFeatVec.extend(featVec[axis+1:])#表示a[axis+1],[axis+2]...[-1] retDataSet.append(reducedFeatVec) return retDataSet #选出最好的划分方式,使得划分后的数据集的香农熵最低,也就是混乱度最低 def chooseBestFeatureToSplit(dataSet): numFeatures=len(dataSet[0])-1#特征个数 baseEntropy=calcShannonEnt(dataSet) bestInfoGain=0.0;bestFeature=-1 for i in range(numFeatures):# featList=[example[i] for example in dataSet]#用于存放第i列特征 uniqueVals=set(featList)#set用于创建唯一的集合类型如:set(1,1,1)=1 newEntropy=0.0 for value in uniqueVals:#计算按照各种类别得到的香农熵 subDataSet=splitDataSet(dataSet,i,value) prob=len(subDataSet)/float(len(dataSet)) newEntropy+=prob*calcShannonEnt(subDataSet) infoGain=baseEntropy-newEntropy if(infoGain>bestInfoGain): bestInfoGain=infoGain bestFeature=i return bestFeature #当所有特征都遍历完成之后还不能完全确定时,就进行投票选出最概然标签 def majorityCnt(classList):#在叶子节点时根据投票,选择票数最多的作为该分类的标签 classCount={} for vote in classList: if vote not in classCount.keys():classCount[vote]=0 classCount[vote]+=1 sortedClassCount=sorted(classCount.items(), key=operator.itemgetter(1),reverse=True)#排序 return sortedClassCount[0][0] ##################__创建树__############### ‘‘‘ def creatTree(dataSet,labels): Labels=labels[:]#此处应当将lables浅复制一下,避免对原数据进行了修改 classList=[example[-1] for example in dataSet]#classLIst存放数据中的所有类(‘yes‘,‘no‘...) if classList.count(classList[0])==len(classList):#如果只有的一种类别的话 return classList[0]#就返回这种类别 if len(dataSet[0])==1:#当所有特征值都用完了,即到了叶子节点 return majorityCnt(classList)#返回由投票投出的类别 bestFeat=chooseBestFeatureToSplit(dataSet)#选择一个最好的特征值 bestFeatLabel=Labels[bestFeat] myTree={bestFeatLabel:{}} del(Labels[bestFeat])#删除掉标签里面的用过的特征值的标签 featValues=[example[bestFeat] for example in dataSet] uniqueVals=set(featValues) for value in uniqueVals:#对于该特征中的每一个属性 subLabels=Labels[:]#下面进行决策树的递归构建 myTree[bestFeatLabel][value]=creatTree(splitDataSet(dataSet,bestFeat,value),subLabels) return myTree def storeTree(inputTree,filename):# fw=open(filename,‘wb‘)#注意此处应该要把打开方式变为‘wb‘,因为下面pickle默认以二进制方式打开 pickle.dump(inputTree,fw) fw.clo def grabTree(filename): fr=open(filename,‘rb‘)#此处也应该改为‘rb‘以二进制方式打开 return pickle.load(fr) ‘‘‘ ###############__构建决策树分类器__############# def classify(inputTree,featLabels,testVec):#输入构造好的决策树 firstStr=list(inputTree.keys())[0]#第一层 secondDict=inputTree[firstStr]#第二层 featIndex=featLabels.index(firstStr)#特征值得索引 for key in list(secondDict.keys()): if testVec[featIndex]==key: if type(secondDict[key]).__name__==‘dict‘: global classLabel#注意局部变量与全局变量的关系,否则会报错 classLabel=classify(secondDict[key],featLabels,testVec) else: classLabel=secondDict[key] return classLabel ###############__获取数据并进行预测__################## def get_data(filename):#清洗数据,获取可以使用的数据 dataSet=pd.read_csv(filename) mean=dataSet[‘Age‘].mean()#用平均值代替空缺的年龄 dataSet=dataSet.fillna({‘Cabin‘:‘Lost‘,‘Age‘:mean,‘Embarked‘:‘S‘})#处理完Cabin,Embarked dataSet[‘Age‘]=(dataSet[‘Age‘]/20).apply(np.round)+1 dataSet[‘Survived2‘]=dataSet[‘Survived‘] dataSet=dataSet.drop([‘Name‘,‘PassengerId‘,‘Fare‘,‘Ticket‘,‘Survived‘,‘SibSp‘,‘Parch‘,‘Cabin‘],axis=1)#删除不需要的列 #dataSet.ix[dataSet[‘Cabin‘]!=‘Lost‘,‘Cabin‘]=‘Have‘ returnData=dataSet.values.tolist() return returnData def test(test_data,inputTree,featLabels): errors=0.0 for i in range(len(test_data)): classResult=classify(inputTree,featLabels,test_data[i][:-1]) if classResult!=test_data[i][-1]: errors+=1 return errors def predict(test_data,inputTree,featLabels):#参数为待测数据,决策树,特征标签 classCount=0.0#用于记录正确的次数 lenOfDatas=len(test_data)#测试集的个数 for i in range(lenOfDatas):#统计测试成功的个数 classResult=classify(inputTree,featLabels,test_data[i][:-1]) if classResult==test_data[i][-1]: classCount+=1 corRate=float(100*classCount/lenOfDatas)#计算准确率 corRate=round(corRate,2) return(corRate) #########################草稿################## def Testing(myTree,dataTest):#对树进行测试 temp_labels=[‘Pclass‘,‘Sex‘,‘Age‘,‘Embarked‘] error=0.0 for i in range(len(dataTest)): result=classify(myTree,temp_labels,dataTest[i][:-1]) if dataTest[i][-1]!=result: error+=1 #print(‘tree%f‘%error) return float(error) def testingMajor(major,dataTest):#测试 error=0.0 for i in range(len(dataTest)): if major!=dataTest[i][-1]: error+=1 #print(‘major%f‘%error) return float(error) #创建决策树 def creatTree(dataSet,labels,dataTest): Labels=copy.deepcopy(labels)#此处应当将lables深复制一下,避免对原数据进行了修改 classList=[example[-1] for example in dataSet]#classLIst存放数据中的所有类(‘yes‘,‘no‘...) if classList.count(classList[0])==len(classList):#如果只有的一种类别的话 return classList[0]#就返回这种类别 if len(dataSet[0])==1:#当所有特征值都用完了,即到了叶子节点 return majorityCnt(classList)#返回由投票投出的类别 bestFeat=chooseBestFeatureToSplit(dataSet)#选择一个最好的特征值,返回索引 bestFeatLabel=Labels[bestFeat] myTree={bestFeatLabel:{}} del(Labels[bestFeat])#删除掉标签里面的用过的特征值的标签 featValues=[example[bestFeat] for example in dataSet] uniqueVals=set(featValues) for value in uniqueVals:#对于该特征中的每一个属性 subLabels=Labels[:]#下面进行决策树的递归构建 myTree[bestFeatLabel][value]=creatTree(splitDataSet(dataSet,bestFeat,value),subLabels,dataTest) if Testing(myTree,dataTest)<testingMajor(majorityCnt(classList),dataTest): return myTree return majorityCnt(classList) #return myTree ########################__主函数__########################### def main(): train_filename=‘E:\\PythonData\\tatanic\\test.csv‘ test_filename=‘E:\\PythonData\\tatanic\\train.csv‘ #feat_labels=[‘Pclass‘,‘Sex‘,‘Age‘,‘SibSp‘,‘Parch‘,‘Cabin‘,‘Embarked‘] feat_labels=[‘Pclass‘,‘Sex‘,‘Age‘,‘Embarked‘]#特征标签 train_datas=get_data(train_filename)#训练集 test_datas=get_data(test_filename)#测试集 tatanicTree=creatTree(test_datas,feat_labels,train_datas)#创建树 #print(tatanicTree)#输出构造好的决策树 createPlot(tatanicTree)#绘出决策树的图 corRate=predict(train_datas,tatanicTree,feat_labels)#计算准确率 print(‘This decision-making tree\‘s correct Rate is:%.2f%%‘%corRate) ###########################__程序运行__############################ if __name__==‘__main__‘: print(‘程序开始运行...‘) t1=time.time() main() t2=time.time() print(‘程序运行的时间为:%.2fs‘%(t2-t1))
#treePlotter #本模块主要任务为绘制决策树,让决策树直观显示出来 import matplotlib.pyplot as plt #这里是对绘制是图形属性的一些定义,可以不用管,主要是后面的算法 decisionNode = dict(boxstyle="sawtooth", fc="0.8") leafNode = dict(boxstyle="round4", fc="0.8") arrow_args = dict(arrowstyle="<-") #这是递归计算树的叶子节点个数,比较简单 def getNumLeafs(myTree): numLeafs = 0 firstStr =list(myTree.keys())[0] secondDict = myTree[firstStr] for key in secondDict.keys(): if type(secondDict[key]).__name__==‘dict‘:#test to see if the nodes are dictonaires, if not they are leaf nodes numLeafs += getNumLeafs(secondDict[key]) else: numLeafs +=1 return numLeafs #这是递归计算树的深度,比较简单 def getTreeDepth(myTree): maxDepth = 0 firstStr =list(myTree.keys())[0] secondDict = myTree[firstStr] for key in secondDict.keys(): if type(secondDict[key]).__name__==‘dict‘:#test to see if the nodes are dictonaires, if not they are leaf nodes thisDepth = 1 + getTreeDepth(secondDict[key]) else: thisDepth = 1 if thisDepth > maxDepth: maxDepth = thisDepth return maxDepth #这个是用来一注释形式绘制节点和箭头线,可以不用管 def plotNode(nodeTxt, centerPt, parentPt, nodeType): createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords=‘axes fraction‘, xytext=centerPt, textcoords=‘axes fraction‘, va="center", ha="center", bbox=nodeType, arrowprops=arrow_args ) #这个是用来绘制线上的标注,简单 def plotMidText(cntrPt, parentPt, txtString): xMid = (parentPt[0]-cntrPt[0])/2.0 + cntrPt[0] yMid = (parentPt[1]-cntrPt[1])/2.0 + cntrPt[1] createPlot.ax1.text(xMid, yMid, txtString, va="center", ha="center", rotation=30) #重点,递归,决定整个树图的绘制,难(自己认为) def plotTree(myTree, parentPt, nodeTxt):#if the first key tells you what feat was split on numLeafs = getNumLeafs(myTree) #this determines the x width of this tree depth = getTreeDepth(myTree) firstStr =list(myTree.keys())[0] #the text label for this node should be this cntrPt = (plotTree.xOff + (1.0 + float(numLeafs))/2.0/plotTree.totalW, plotTree.yOff) plotMidText(cntrPt, parentPt, nodeTxt) plotNode(firstStr, cntrPt, parentPt, decisionNode) secondDict = myTree[firstStr] plotTree.yOff = plotTree.yOff - 1.0/plotTree.totalD for key in secondDict.keys(): if type(secondDict[key]).__name__==‘dict‘:#test to see if the nodes are dictonaires, if not they are leaf nodes plotTree(secondDict[key],cntrPt,str(key)) #recursion else: #it‘s a leaf node print the leaf node plotTree.xOff = plotTree.xOff + 1.0/plotTree.totalW plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode) plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key)) plotTree.yOff = plotTree.yOff + 1.0/plotTree.totalD #if you do get a dictonary you know it‘s a tree, and the first element will be another dict #这个是真正的绘制,上边是逻辑的绘制 def createPlot(inTree): fig = plt.figure(1, facecolor=‘white‘) fig.clf() axprops = dict(xticks=[], yticks=[]) createPlot.ax1 = plt.subplot(111, frameon=False) #no ticks plotTree.totalW = float(getNumLeafs(inTree)) plotTree.totalD = float(getTreeDepth(inTree)) plotTree.xOff = -0.5/plotTree.totalW; plotTree.yOff = 1.0; plotTree(inTree, (0.5,1.0), ‘‘) plt.show() #这个是用来创建数据集即决策树 def retrieveTree(i): listOfTrees =[{‘no surfacing‘: {0:{‘flippers‘: {0: ‘no‘, 1: ‘yes‘}}, 1: {‘flippers‘: {0: ‘no‘, 1: ‘yes‘}}, 2: {‘flippers‘: {0: ‘no‘, 1: ‘yes‘}}}}, {‘no surfacing‘: {0: ‘no‘, 1: {‘flippers‘: {0: {‘head‘: {0: ‘no‘, 1: ‘yes‘}}, 1: ‘no‘}}}} ] return listOfTrees[i]
标签:afn uml title 分享 btree lines ring ota __name__
原文地址:https://www.cnblogs.com/xfydjy/p/9290881.html