标签:append 建模 分享 select 100% png 图片 预测 k近邻
代码:
1 # -*- coding: utf-8 -*- 2 """ 3 Created on Thu Jul 12 09:36:49 2018 4 5 @author: zhen 6 """ 7 """ 8 分析n_neighbors的大小对K近邻算法预测精度和泛化能力的影响 9 """ 10 from sklearn.datasets import load_breast_cancer 11 12 from sklearn.model_selection import train_test_split 13 14 from sklearn.neighbors import KNeighborsClassifier 15 16 import matplotlib.pyplot as plt 17 18 cancer = load_breast_cancer() 19 20 x_train, x_test, y_train, y_test = train_test_split( 21 cancer.data, cancer.target, stratify=cancer.target, random_state=66) 22 23 training_accuracy = [] 24 25 test_accuracy = [] 26 27 # n_neighbors取值从1~10 28 neighbors_settings = range(1, 11) 29 30 for n_neighbors in neighbors_settings: 31 # 构建模型 32 clf = KNeighborsClassifier(n_neighbors=n_neighbors) 33 clf.fit(x_train, y_train) 34 # 记录训练集精度S 35 training_accuracy.append(clf.score(x_train, y_train)) 36 # 记录泛化能力 37 test_accuracy.append(clf.score(x_test, y_test)) 38 39 plt.plot(neighbors_settings, training_accuracy, label="training accuracy") 40 plt.plot(neighbors_settings, test_accuracy, label="test accuracy") 41 42 plt.xlabel("n_neighbors") 43 plt.ylabel("Accuracy") 44 45 plt.legend()
结果:
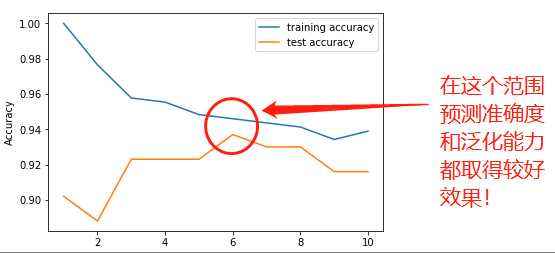
总结:在仅考虑单一近邻时,训练集上的预测结果十分完美(接近100%)。但随着邻居个数的增多,模型变得更简单(泛化能力越好),训练集精度也随之下降。为求得较好的预测精度和泛化能力,最佳性能在neighbors为6左右!
查看neighbors大小对K近邻分类算法预测准确度和泛化能力的影响
标签:append 建模 分享 select 100% png 图片 预测 k近邻
原文地址:https://www.cnblogs.com/yszd/p/9298214.html