标签:ide site nbsp code pipe items 分享图片 pipeline install
Scrapy 是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
下面是Scrapy的架构,包括组件以及在系统中发生的数据流的概览(绿色箭头所示)。
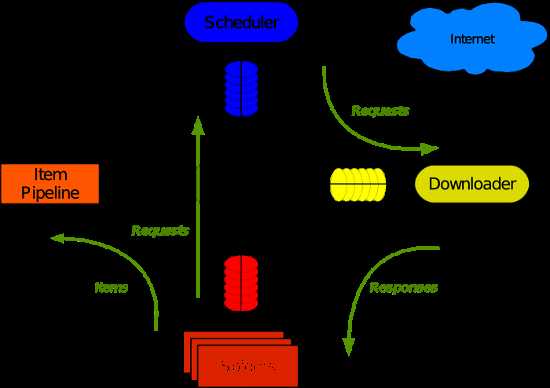


数据流
Scrapy中的数据流由执行引擎控制,其过程如下:

Scarpy的安装
1 安装: 2 Linux/mac 3 - pip3 install scrapy 4 Windows: 5 - 安装twsited 6 a. pip3 install wheel 7 b. 下载twisted http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted 8 c. 进入下载目录,执行 pip3 install Twisted-xxxxx.whl 9 - 安装scrapy 10 d. pip3 install scrapy -i http://pypi.douban.com/simple --trusted-host pypi.douban.com 11 - 安装pywin32 12 e. pip3 install pywin32 -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
Scarpy的基本使用
创建项目:
scrapy startproject tutorial #该命令将会创建一个新的Scarpy项目
得到:
tutorial/ scrapy.cfg # 项目的配置文件 tutorial/ # 该项目的python模块。之后您将在此加入代码 __init__.py items.py # 项目中的item文件 pipelines.py # 项目中的pipelines文件 settings.py # 项目的设置文件 spiders/ # 放置spider代码的目录 __init__.py
标签:ide site nbsp code pipe items 分享图片 pipeline install
原文地址:https://www.cnblogs.com/aberwang/p/9304291.html