标签:screens tar settings 自动 firefox into 火狐浏览器 next 关闭浏览器
爬取今日头条https://www.toutiao.com/首页推荐的新闻,打开网址得到如下界面
查看源代码你会发现

全是js代码,说明今日头条的内容是通过js动态生成的。
用火狐浏览器F12查看得知
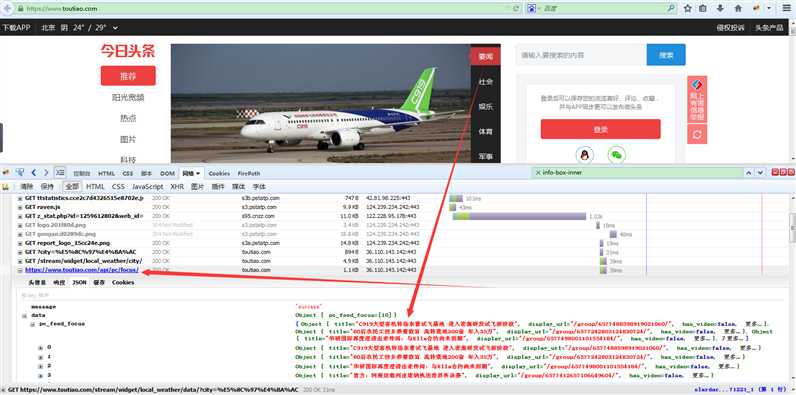
得到了今日头条的推荐新闻的接口地址:https://www.toutiao.com/api/pc/focus/
单独访问这个地址得到
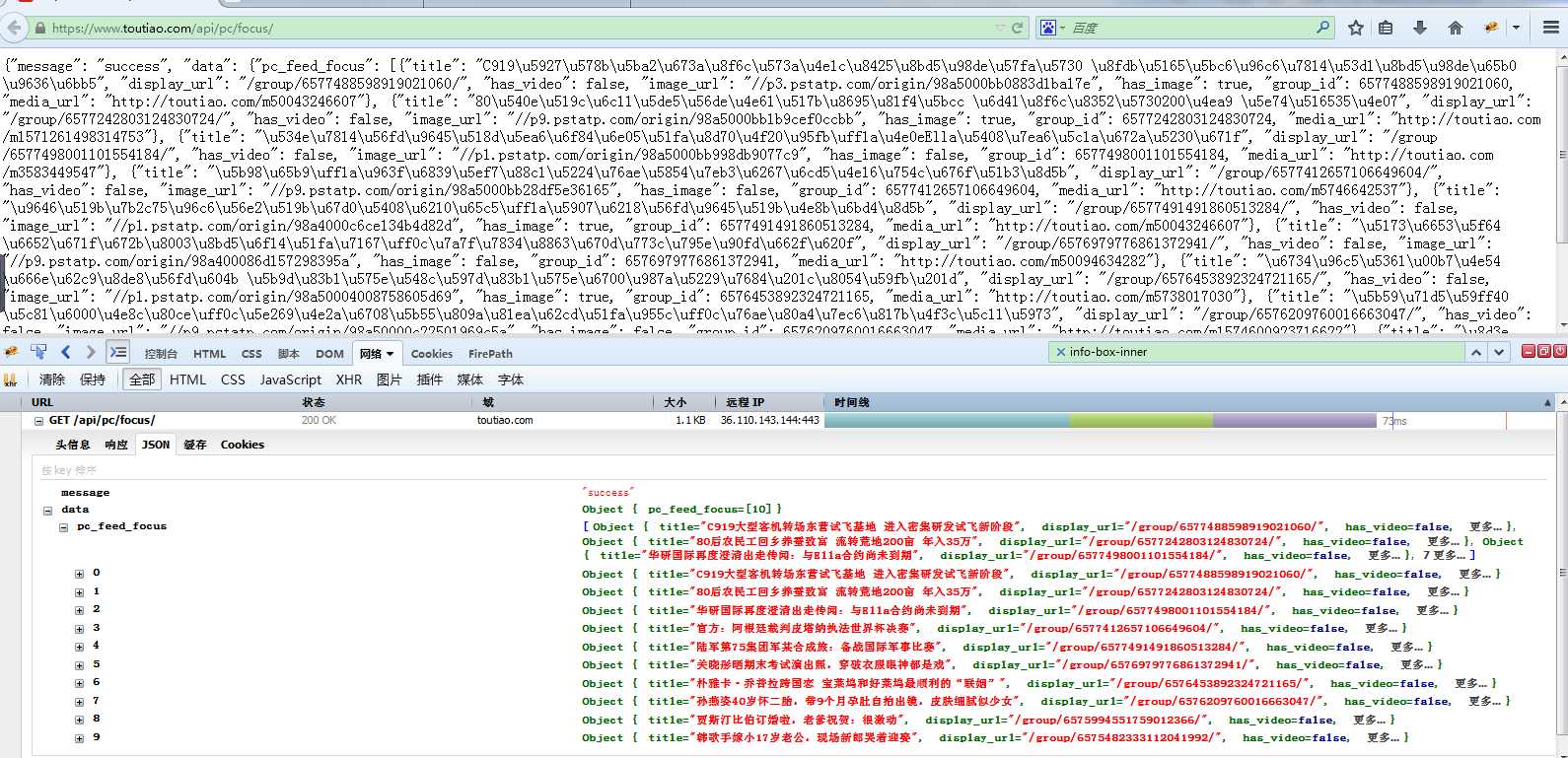
此接口得到的数据格式为json数据
我们用scrapy+selenium+PhantomJS的方式获取今日头条推荐的内容
下面是是scrapy中最核心的代码,位于spiders中的toutiao_example.py
# -*- coding: utf-8 -*-
import scrapy
import json
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
import time
import re
class ToutiaoExampleSpider(scrapy.Spider):
name = ‘toutiao_example‘
allowed_domains = [‘toutiao.com‘]
start_urls = [‘https://www.toutiao.com/api/pc/focus/‘] ###今日头条焦点的api接口
def parse(self, response):
#print(response,123)
conten_json=json.loads(response.text) ###得到json数据
#print(conten_json,type(conten_json),456)
conten_news=conten_json[‘data‘] ###从json数据中抽取data字段数据,其中data字段数据里面包含了pc_feed_focus这个字段,其中这个字段包含了:新闻的标题title,链接url等信息
#print(conten_news,789)
for aa in conten_news[‘pc_feed_focus‘]:
#print(aa)
title=aa[‘title‘]
link_url=‘https://www.toutiao.com‘+aa[‘display_url‘] ###如果写(www.toutiao.com‘+aa[‘display_url‘])会报错,加上https://,(https://www.toutiao.com‘+aa[‘display_url‘])则不会报错!
#print(link_url)
link_url_new=link_url.replace(‘group/‘,‘a‘)###把链接https://www.toutiao.com/group/6574248586484122126/,放到浏览器中,地址会自动变成https://www.toutiao.com/a6574248586484122126/这个。所以我们需要把group/ 替换成a
#print(link_url_new)
yield scrapy.Request(link_url_new, callback=self.next_parse)
def next_parse(self, response):
dcap = dict(DesiredCapabilities.PHANTOMJS) # 设置useragent信息
dcap[‘phantomjs.page.settings.userAgent‘] = (
‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:25.0) Gecko/20100101 Firefox/25.0 ‘) # 根据需要设置具体的浏览器信息
###r"D:\\phantomjs-2.1.1-windows\bin\phantomjs.exe",
driver = webdriver.PhantomJS(desired_capabilities=dcap) #封装浏览器信息) # 指定使用的浏览器,
#driver.set_page_load_timeout(5) # 设置超时时间
driver.get(response.url)##使用浏览器请求页面
time.sleep(3)#加载3秒,等待所有数据加载完毕
###通过class来定位元素属性
###title是标题
title=driver.find_element_by_class_name(‘title‘).text ###.text获取元素的文本数据
content1=driver.find_element_by_class_name(‘abstract-index‘).text###.text获取元素的文本数据
content2=driver.find_element_by_class_name(‘abstract‘).text###.text获取元素的文本数据
###content是内容
content=content1+content2
print(title,content,6666666666666666)
# 关闭浏览器
driver.close()
# data = driver.page_source# 获取网页文本
# driver.save_screenshot(‘1.jpg‘) # 系统截图保存
运行代码我们得到结果为标题加内容呈现方式如下

使用scrapy爬虫,爬取今日头条首页推荐新闻(scrapy+selenium+PhantomJS)
标签:screens tar settings 自动 firefox into 火狐浏览器 next 关闭浏览器
原文地址:https://www.cnblogs.com/stevenshushu/p/9306026.html