标签:常见 交换 break 总结 ima inf 阅读 双引号 特点
python中断多重循环的方法exit_flag
常见的方法: exit_flag = flase for 循环: for 循环: if 条件 exit_flag = true break #跳出里面的循环 if exit_flag: break #跳出外面的循环
基本数据类型和扩展数据类型的分类?
基本数据类型:
可变数据类型:列表,字典,集合
不可变数据类型:字符串,元祖,数字
扩展性数据类型:
1,namedtuole():生成可以使用名字来访问元素内容的tuple子类
2,deque:双端队列,可以快速的从另一侧追加和推出对象
3,counter:计数器,主要用来计数
4,orderdict:有序字典
5,defaultdict:带有默认值的字典
字符串是 Python 中最常用的数据类型。我们可以使用引号(‘或")来创建字符串。
创建字符串很简单,只要为变量分配一个值即可。例如:
var1 = ‘Hello World!‘ var2 = "Runoob"
Python 不支持单字符类型,单字符在 Python 中也是作为一个字符串使用。
Python 访问子字符串,可以使用方括号来截取字符串,如下实例:
#!/usr/bin/python3 var1 = ‘Hello World!‘ var2 = "Runoob" print ("var1[0]: ", var1[0]) print ("var2[1:5]: ", var2[1:5])
执行结果
var1[0]: H
var2[1:5]: unoo
#!/usr/bin/python3 var1 = ‘Hello World!‘ print ("已更新字符串 : ", var1[:6] + ‘Runoob!‘)
执行结果
已更新字符串 : Hello Runoob!
Python转义字符
转义字符 描述 \(在行尾时) 续行符 \\ 反斜杠符号 \‘ 单引号 \" 双引号 \a 响铃 \b 退格(Backspace) \e 转义 \000 空 \n 换行 \v 纵向制表符 \t 横向制表符 \r 回车 \f 换页 \oyy 八进制数,yy代表的字符,例如:\o12代表换行 \xyy 十六进制数,yy代表的字符,例如:\x0a代表换行 \other 其它的字符以普通格式输出
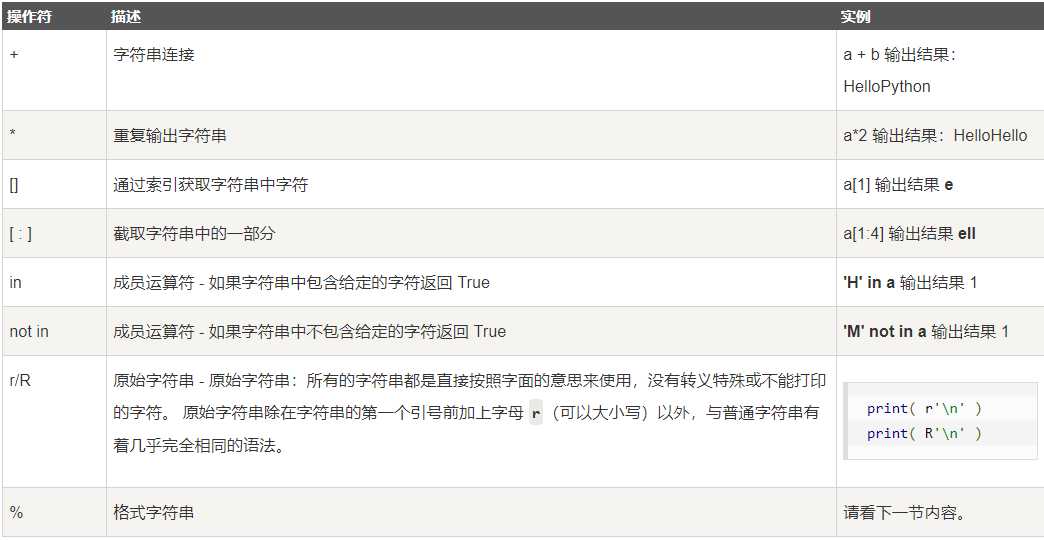
#!/usr/bin/python3 a = "Hello" b = "Python" print("a + b 输出结果:", a + b) print("a * 2 输出结果:", a * 2) print("a[1] 输出结果:", a[1]) print("a[1:4] 输出结果:", a[1:4]) if( "H" in a) : print("H 在变量 a 中") else : print("H 不在变量 a 中") if( "M" not in a) : print("M 不在变量 a 中") else : print("M 在变量 a 中") print (r‘\n‘) print (R‘\n‘)
a + b 输出结果: HelloPython a * 2 输出结果: HelloHello a[1] 输出结果: e a[1:4] 输出结果: ell H 在变量 a 中 M 不在变量 a 中 \n \n
http://www.runoob.com/python3/python3-string.html
元组的特点和功能
特点:
不可变,所以又称只读列表
本身不可变,但是如果元祖中还包含了其他可变元素,这些可变元素可以改变
功能:
索引
count
切片
简单讲一下hash
hash,一般翻译做“散列”,也有直接音译为“哈希”的,就是把任意长度的输入,通过散列算法,变化成固定长度的输出,该输出就是散列值,这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能散列成相同的输出,所以不可能从散列值来唯一的确定输入值,简单的说就是有一种将任意长度的消息压缩到某一固定长度的函数。
特性:hash值的计算过程是依据这个值的一些特性计算的,这就要求被hash的值必须固定,因此被hash的值是不可变的。
为什么使用16进制
1,计算机硬件是0101二进制,16进制刚好是2的倍数,更容易表达一个命令或者数据,十六进制更简短,因为换算的时候一位16进制数可以顶4位二进制数,也就是一个字节(8位进制可以用两个16进制表示)
2,最早规定ASCII字符采取的就是8bit(后期扩展了,但是基础单位还是8bit),8bit用两个16进制直接就能表达出来,不管阅读还是存储逗逼其他进制更方便。
3,计算机中CPU计算也是遵循ASCII字符串,以16,32,64这样的方法在发展,因此数据交换的时候16进制也显得更好
4,为了统一规范,CPU,内存,硬盘我们看到的都是采取的16进制计算
字符编码转换总结
python2.x
内存中字符默认编码是ASCII,默认文件编码也是ASCII
当声明了文件头的编码后,字符串的编码就按照文件编码来,总之,文件编码是什么,那么python2.x的str就是什么
python2.x的unicode是一个单独的类型,按u"编码"来表示
python2.x str==bytes,bytes直接是按照字符编码存成2进制格式在内存里
python3.x
字符串都是unicode
文件编码都默认是utf-8,读到内存会被python解释器自动转成unicode
bytes和str做了明确的区分
所有的unicode字符编码后都会编程bytes格式
请用代码实现,查找列表中元素,移除每个元素的空格,并查找以a或者A开头并且以c结尾的所有元素
li =[‘alex‘,‘eric‘,‘rain‘] tu =(‘alex‘,‘aric‘,‘Tony‘,‘rain‘) dic = {‘k1‘:‘alex‘,‘aroc‘:‘dada‘,‘k4‘:‘dadadad‘} for i in li: i_new = i.strip().capitalize() if i_new.startswith(‘A‘) and i_new.endswith(‘c‘): print(i_new) for i in tu: i_new0 = i.strip().capitalize() if i_new0.startswith(‘A‘) and i_new.endswith(‘c‘): print(i_new0) for i in dic: i_new1 = i.strip().capitalize() if i_new1.startswith(‘A‘) and i_new.endswith(‘c‘): print(i_new1)
利用for循环和range输出9*9乘法表
for i in range(1,10): for j in range(1,i+1): print(str(i)+"*"+str(j) +"="+str(i*j),end=‘ ‘) print( )
标签:常见 交换 break 总结 ima inf 阅读 双引号 特点
原文地址:https://www.cnblogs.com/xuan-xue/p/9309334.html