标签:dns 根据 xpath 方式 支持 语法 种类 ade 传输
什么是爬虫?
爬虫可以做什么?
爬虫的本质
爬虫的基本流程
什么是request&response
爬取到数据该怎么办
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
其实通俗的讲就是通过程序去获取web页面上自己想要的数据,也就是自动抓取数据
你可以爬取小姐姐的图片,爬取自己有兴趣的岛国视频,或者其他任何你想要的东西,前提是,你想要的资源必须可以通过浏览器访问的到。
上面关于爬虫可以做什么,定义了一个前提,是浏览器可以访问到的任何资源,特别是对于知晓web请求生命周期的学者来说,爬虫的本质就更简单了。爬虫的本质就是模拟浏览器打开网页,获取网页中我们想要的那部分数据。
浏览器打开网页的过程:
1、在浏览器的输入地址栏,输入想要访问的网址。
2、经过DNS服务器找到服务器主机,向服务器发送一个请求
3、服务器经过解析处理后返回给用户结果(包括html,js,css文件等等内容)
4、浏览器接收到结果,进行解释通过浏览器屏幕呈现给用户结果
上面我们说了爬虫的本质就是模拟浏览器自动向服务器发送请求,获取、处理并解析结果的自动化程序。
爬虫的关键点:模拟请求,解析处理,自动化。
发起请求
通过HTTP库向目标站点发起请求(request),请求可以
包含额外的header等信息,等待服务器响应
获取响应内容
如果服务器能正常响应,会得到一个Response,Response的内容便是所要获取的页面内容,类型可能是HTML,Json字符串,二进制数据(图片或者视频)等类型
解析内容
得到的内容可能是HTML,可以用正则表达式,页面解析库进行解析,可能是Json,可以直接转换为Json对象解析,可能是二进制数据,可以做保存或者进一步的处理
保存数据
保存形式多样,可以存为文本,也可以保存到数据库,或者保存特定格式的文件
浏览器发送消息给网址所在的服务器,这个过程就叫做HTPP Request
服务器收到浏览器发送的消息后,能够根据浏览器发送消息的内容,做相应的处理,然后把消息回传给浏览器,这个过程就是HTTP Response
浏览器收到服务器的Response信息后,会对信息进行相应的处理,然后通过显示器呈现给用户
我们以访问百度为例:
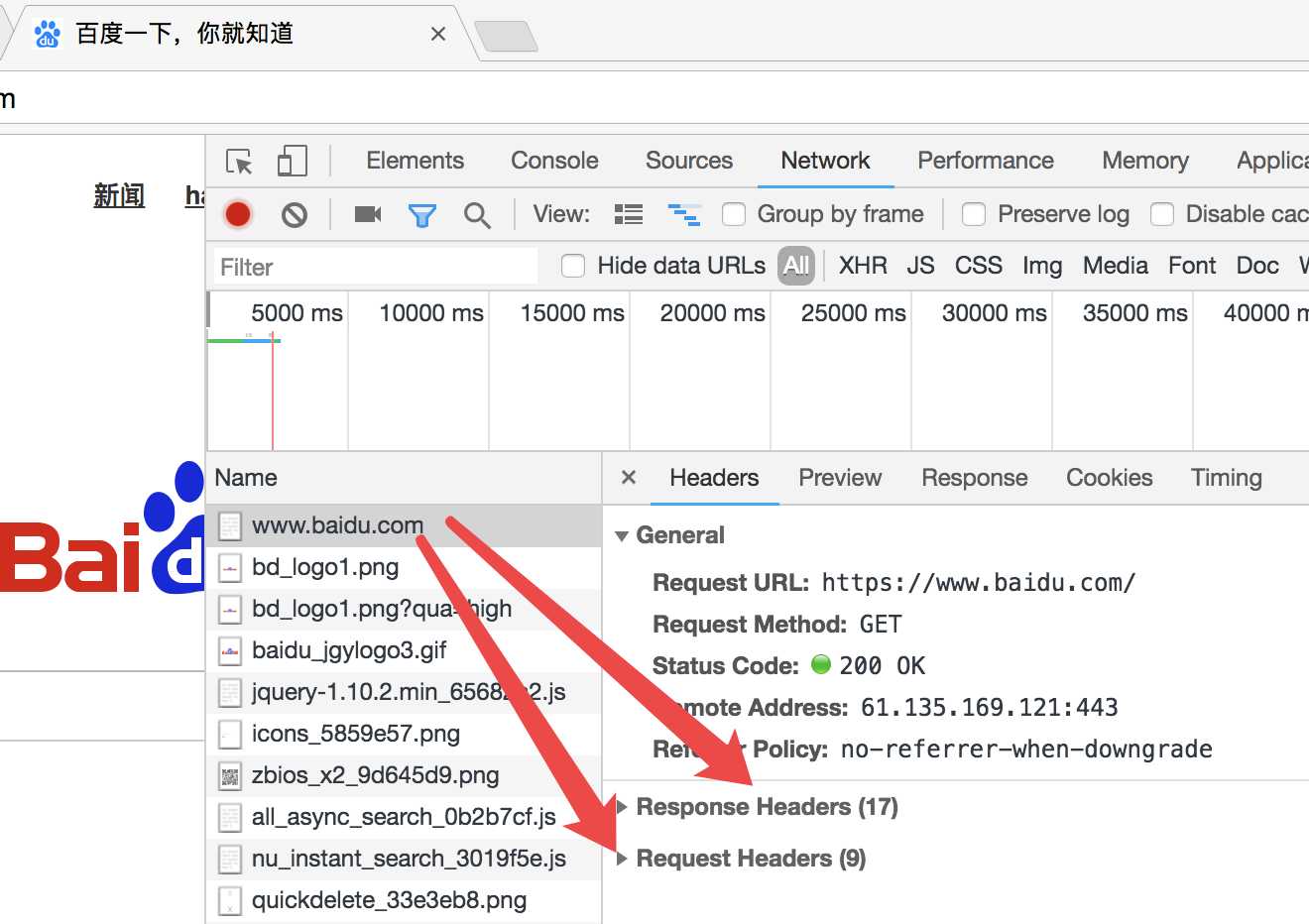
请求方式
主要有:GET/POST两种类型常用,另外还有HEAD/PUT/DELETE/OPTIONS
GET和POST的区别就是:请求的数据GET是在url中,POST则是存放在头部
GET:向指定的资源发出“显示”请求。使用GET方法应该只用在读取数据,而不应当被用于产生“副作用”的操作中,例如在Web Application中。其中一个原因是GET可能会被网络蜘蛛等随意访问
POST:向指定资源提交数据,请求服务器进行处理(例如提交表单或者上传文件)。数据被包含在请求本文中。这个请求可能会创建新的资源或修改现有资源,或二者皆有。
HEAD:与GET方法一样,都是向服务器发出指定资源的请求。只不过服务器将不传回资源的本文部分。它的好处在于,使用这个方法可以在不必传输全部内容的情况下,就可以获取其中“关于该资源的信息”(元信息或称元数据)。
PUT:向指定资源位置上传其最新内容。
OPTIONS:这个方法可使服务器传回该资源所支持的所有HTTP请求方法。用‘*‘来代替资源名称,向Web服务器发送OPTIONS请求,可以测试服务器功能是否正常运作。
DELETE:请求服务器删除Request-URI所标识的资源。
请求URL
URL,即统一资源定位符,也就是我们说的网址,统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。
URL的格式由三个部分组成:
第一部分是协议(或称为服务方式)。
第二部分是存有该资源的主机IP地址(有时也包括端口号)。
第三部分是主机资源的具体地址,如目录和文件名等。
爬虫爬取数据时必须要有一个目标的URL才可以获取数据,因此,它是爬虫获取数据的基本依据。
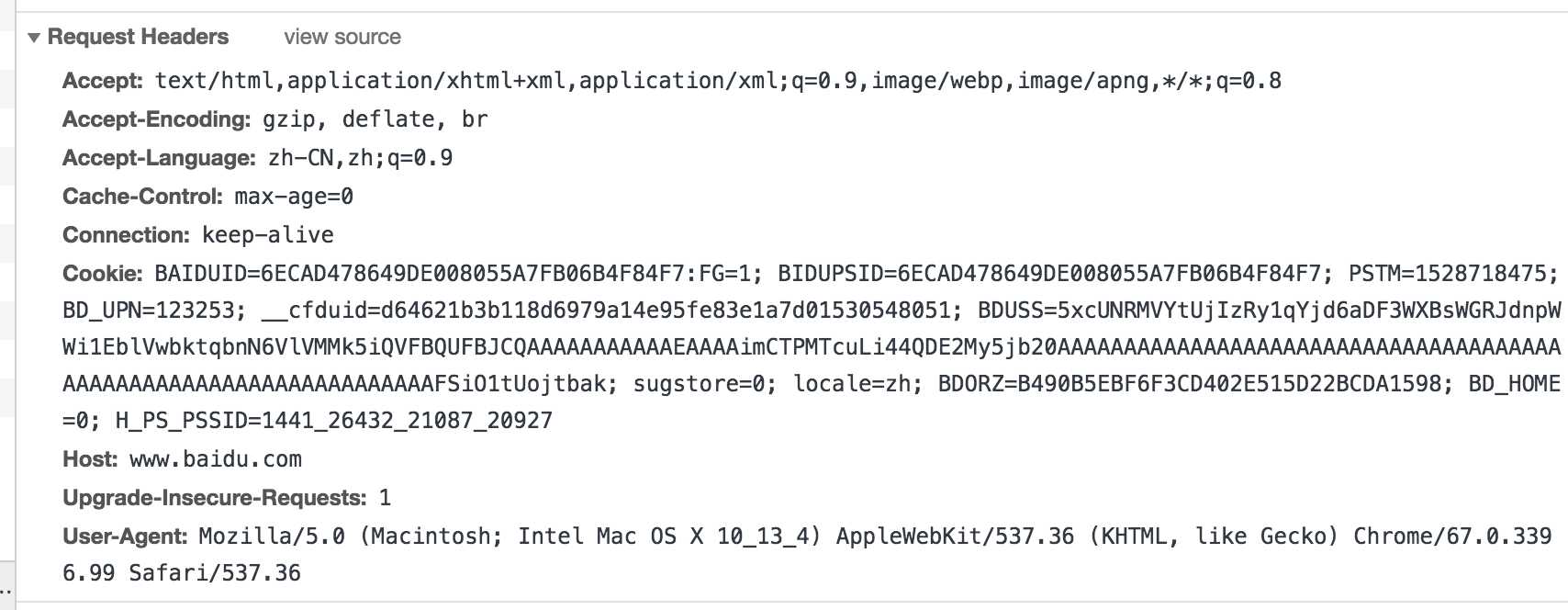
请求头
包含请求时的头部信息,如User-Agent,Host,Cookies等信息,下图是请求请求百度时,所有的请求头部信息参数
请求体
请求是携带的数据,如提交form表单数据时候的表单数据(POST)
所有HTTP响应的第一行都是状态行,依次是当前HTTP版本号,3位数字组成的状态代码,以及描述状态的短语,彼此由空格分隔。
响应状态
有多种响应状态,如:200代表成功,301跳转,404找不到页面,502服务器错误
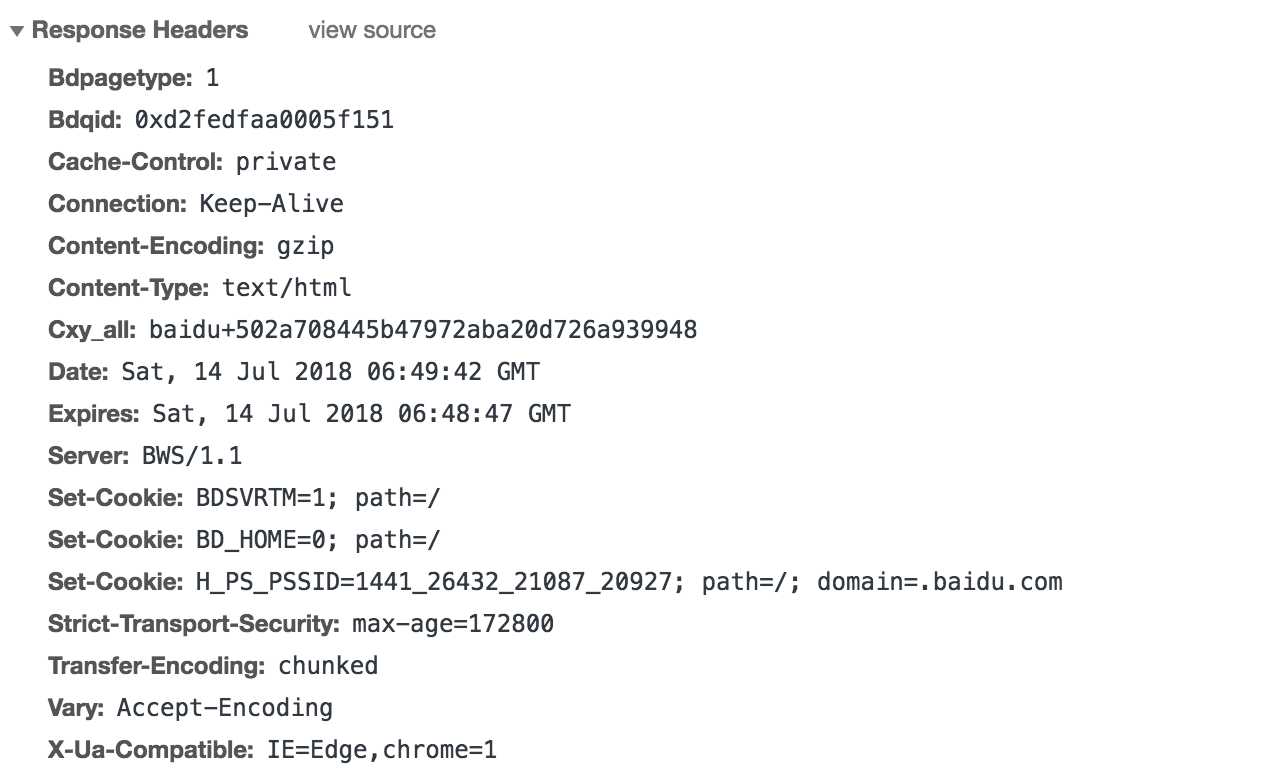
响应头
如内容类型,类型的长度,服务器信息,设置Cookie,如下图:
响应体
最主要的部分,包含请求资源的内容,如网页HTMl,图片,二进制数据等
网页文本:如HTML文档,Json格式化文本等
图片:获取到的是二进制文件,保存为图片格式
视频:同样是二进制文件
其他:只要请求到的,都可以获取
1 直接处理 2 Json解析 3 正则表达式处理 4 BeautifulSoup解析处理 5 PyQuery解析处理 6 XPath解析处理
出现这种情况是因为,很多网站中的数据都是通过js,ajax动态加载的,所以直接通过get请求获取的页面和浏览器显示的不同。
如何解决js渲染的问题?
分析ajax
Selenium/webdriver
Splash
PyV8,Ghost.py
文本:纯文本,Json,Xml等
关系型数据库:如mysql,oracle,sql server等结构化数据库
非关系型数据库:MongoDB,Redis等key-value形式存储
标签:dns 根据 xpath 方式 支持 语法 种类 ade 传输
原文地址:https://www.cnblogs.com/wuzdandz/p/9309665.html