标签:nbsp 使用 blog 格式化 一个 行操作 pat for value
Python中有join和os.path.join()两个函数,具体作用如下:
join:连接字符串数组。将字符串、元组、列表中的元素以指定的字符(分隔符)连接生成一个新的字符串
os.path.join(): 将多个路径组合后返回
一、函数说明
1.join()函数
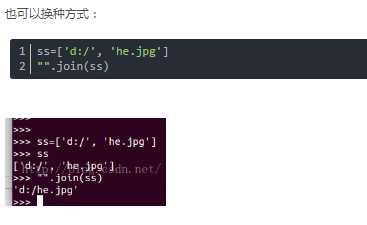
语法:‘sep’.join(seq)
参数说明:
sep:分隔符。可以为空
seq:要连接的元素序列、字符串、元组、字典等
上面的语法即:以sep作为分隔符,将seq所有的元素合并成一个新的字符串
返回值:返回一个以分隔符sep连接各个元素后生成的字符串
2、os.path.join()函数
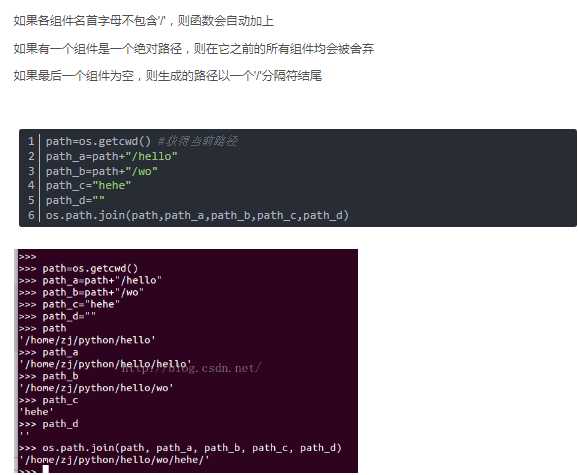
语法: os.path.join(path1[,path2[,......]])
返回值:将多个路径组合后返回
注:第一个绝对路径之前的参数将被忽略
实例:
在OSChina上也有一个九九乘法表的代码,如下(原文链接:http://www.oschina.net/code/snippet_53549_2238)
print ‘\n‘.join([‘ ‘.join([‘%s*%s=%-2s‘ % (y,x,x*y) for y in range(1,x+1)])for x in range(1,10)])
短短一句话,就完美打印出九九乘法表。
对此段代码的赏析,百度博客有篇文章介绍的很清楚,在此不多说。
原文如下:(链接:http://hi.baidu.com/fc_lamp/blog/item/fb7d410bf7314c0295ca6b8c.html)
最近在oschina上看到段九九乘法表 的代码,如下:
print‘\n‘.join([‘ ‘.join([‘%s*%s=%-2s‘%(y,x,x*y) fory in range(1,x+1)]) forx in range(1,10)])
(来至于:http://www.oschina.net/code/snippet_53549_2238)
我稍微调整了一下:
#coding:utf-8
print(‘\n‘.join([‘ ‘.join(‘%sx%s=%-2s‘%(x,y,x*y) for x in xrange(1,y+1)) for y in xrange(1,10)]))
恩,其实两代码都参不多,那么我们就来解析一下,这段代码:
首先:要使用的主要知识点:
1 列表解析知识(以及元组知识)
2 range,xrange,join函数的使用
3 字符串格式化输出
Python中有split()和os.path.split()两个函数:
split():拆分字符串。通过指定分隔符对字符串进行切片,并返回分割后的字符串列表。
os.path.split():将文件名和路径分割开。
1、split()函数
语法:str.split(str=" ",num=string.count(str))[n]
参数说明:
str: 表示为分隔符,默认为空格,但是不能为空串。若字符串中没有分隔符,则把整个字符串作为列表的一个元素。
num:表示分割次数。如果存在参数num,则仅分隔成 num+1 个子字符串。
[n]: 表示选取第n个分片(从0计数)
默认情况下,使用空格作为分隔符,则分隔后,空串会自动忽略,如:
>>> s=‘love python‘ >>> s.split() [‘love‘, ‘python‘]
但若显式指定空格为分隔符,则不会自动忽略空串,如:
>>> s.split(‘ ‘) [‘love‘, ‘‘, ‘‘, ‘‘, ‘python‘]
默认的分隔符除了空格,还有 ‘\n\t\r‘,分隔后,空串会自动忽略,如下:

>>> s=‘love \n\t\r \t\r\n python \n\t\r‘ >>> s.split() [‘love‘, ‘python‘] >>> s=‘www.pku.edu.cn‘
>>> s.split() #默认空格作为分隔符,但字符串中没有分隔符,因此,把整个字符串作为列表的一个元素
[‘www.pku.edu.cn‘]
>>> s.split(‘.‘) #以‘.‘作为分隔符,没有指定分隔次数,则有多少 ‘.‘ 就分隔多少次
[‘www‘, ‘pku‘, ‘edu‘, ‘cn‘]
>>> s.split(‘.‘,0) #分隔0次
[‘www.pku.edu.cn‘]
>>> s.split(‘.‘,1) #分隔1次
[‘www‘, ‘pku.edu.cn‘]
>>> s.split(‘.‘,2)#分隔2次
[‘www‘, ‘pku‘, ‘edu.cn‘]
>>> s.split(‘.‘,2)[1]#分隔2次,取索引为1的项
‘pku‘
>>> s.split(‘.‘,-1) #尽可能多的分隔,与不加num参数相同
[‘www‘, ‘pku‘, ‘edu‘, ‘cn‘]
>>> s1,s2=s.split(‘.‘,1)#分隔1次,并把分隔后的2个字符串存放在s1和s2中
>>> s1
‘www
‘love\nhello\npython‘
>>> s.split(‘\n‘)#以‘\n‘作为分隔符,分隔次数尽可能的多
[‘love‘, ‘hello‘, ‘python‘]
>>> print s
love
hello
python
练习一下下面的例子:
>>> s=‘hello python<[www.python.com]>hello python‘ >>> s.split(‘[‘)[1].split(‘]‘)[0] ‘www.python.com‘ >>> s.split(‘[‘)[1].split(‘]‘)[0].split(‘.‘) [‘www‘, ‘python‘, ‘com‘]
2、os.path.split()函数
语法:os.path.split(‘PATH‘)
参数说明:
>>> import os >>> os.path.split(‘C:/soft/python/test.py‘) (‘C:/soft/python‘, ‘test.py‘) >>> os.path.split(‘C:/soft/python/test‘) (‘C:/soft/python‘, ‘test‘) >>> os.path.split(‘C:/soft/python/‘) (‘C:/soft/python‘, ‘‘)
Python基本知识 os.path.join与split() 函数
标签:nbsp 使用 blog 格式化 一个 行操作 pat for value
原文地址:https://www.cnblogs.com/klb561/p/9310841.html