标签:错误 描述 成功 今天 else int install info size
找不到要写什么东西了!今天有个潭州大牛讲师 说了个 文本词频分析
我基本上就照抄了一遍
中间遇到一些小小的问题 自我百度 填坑补全了 如下 :
效果演示

python3.x版本 随意
安装jieba库
pip install jieba
jieba三种模式:
1.精准模式 lcut函数,返回一个分词列表
2.全模式
3.搜索引擎模式
词频:
<单词>:<出现次数>的键值对
IPO描述 imput output process
输入 :从文件读取三国演义的内容
处理 :采用jiedb进行分词,字典数据结构统计词语出现的频率
输出 :文章中出现最对的前10个词
代码:
第一步:读取文件
第二步:分词
第三步:统计
第四步:排序
完整代码如下:
1 import jieba 2 3 content = open(‘三国演义.txt‘, ‘r‘,encoding=‘utf-8‘).read() 4 words =jieba.lcut(content)#分词 5 excludes={"将军","却说","二人","后主","上马","不知","天子","大叫","众将","不可","主公","蜀兵","只见","如何","商议","都督","一人","汉中","不敢","人马","陛下","魏兵","天下","今日","左右","东吴","于是","荆州","不能","如此","大喜","引兵","次日","军士","军马"}#排除的词汇 6 words=jieba.lcut(content) 7 counts={} 8 9 for word in words: 10 if len(word) == 1: # 排除单个字符的分词结果 11 continue 12 elif word == ‘孔明‘ or word == ‘孔明曰‘: 13 real_word = ‘孔明‘ 14 elif word == ‘关公‘ or word == ‘云长‘: 15 real_word = ‘关羽‘ 16 elif word == ‘孟德‘ or word == ‘丞相‘: 17 real_word = ‘曹操‘ 18 elif word == ‘玄德‘ or word == ‘玄德曰‘: 19 real_word = ‘刘备‘ 20 else: 21 real_word =word 22 counts[word] = counts.get(word, 0) + 1 23 24 25 26 for word in excludes: 27 del(counts[word]) 28 items=list(counts.items()) 29 items.sort(key=lambda x:x[1],reverse=True) 30 for i in range(10): 31 word,count=items[i] 32 print("{0:<10}{1:>5}".format(word,count))
① 在执行的过程中遇到:‘gbk‘ codec can‘t decode byte 0x82 in position 20: illegal multibyte sequence 编码错误:content = open("C:\\Users\\geek\\Desktop\\python.txt", "r",encoding= ‘utf-8‘)
这里是我下载的txt文件 《三国演义》是ASCII,怎么办呢!搜索过后得知,要正常运行就得把TXT的编码改为UTF-8的形式才能运行成功,怎么做呢!
首先:打开TXT文本→文件→另存为→编码→UTF-8 →确定 完成第一个坑。 到这里呢!配合以上代码你成功了,但是我遇到的远远要多2个的所以我准备一并写出来。
② 坑②,这里呢!就是他在在线讲课啊 ,没有TXT三国演义文件怎办呢!没办法 自己找个三国演义文本 附上下载地址: http://vdisk.weibo.com/s/AfY-rVkr38Gg
③ 下载好以后就可以就可以愉快的玩耍了,但是我要说但是了,要问我为什么?容我一一道来! 15个字组太多会出现什么呢!我截图
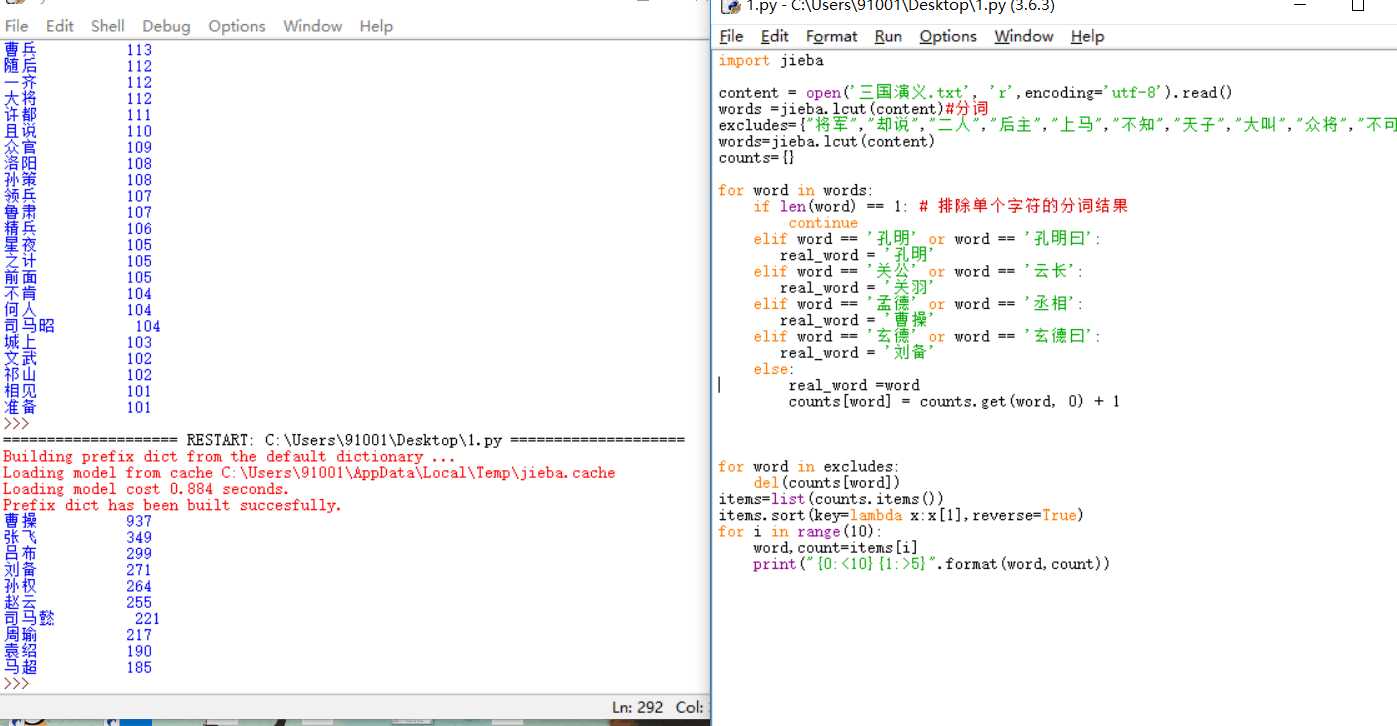
运行后会出现很多不相干的词汇,行,没办法只能清理 ,但是我清理大多数还是有 ,实在没办法了,本为了练手所用所以我降到10个词组,不错,那么想要完整的名字词组呢?就需要排除的词汇增多,所以这个玩法就到此结束。
标签:错误 描述 成功 今天 else int install info size
原文地址:https://www.cnblogs.com/A9kl/p/9311246.html