标签:style blog http color io os 使用 ar for
Load_(modelFile); //model直接序列化
string normalizerName = read_file(OBJ_NAME_PATH(_normalizer));
if (!normalizerName.empty())
{ //由于没有利用shared ptr直接序列化,不知道具体信息,所以我save的时候写了normalzier类型名字到文本,load时候通过这个确定类型
_normalizer = NormalizerFactory::CreateNormalizer(normalizerName, OBJ_PATH(_normalizer));
}
string calibratorName = read_file(OBJ_NAME_PATH(_calibrator));
if (!calibratorName.empty())
{
_calibrator = CalibratorFactory::CreateCalibrator(calibratorName, OBJ_PATH(_calibrator));
}
static NormalizerPtr CreateNormalizer(string name)
{
boost::to_lower(name);
if (name == "minmax" || name == "minmaxnormalizer")
{
return make_shared<MinMaxNormalizer>();
}
if (name == "gaussian" || name == "gaussiannormalizer")
{
return make_shared<GaussianNormalizer>();
}
if (name == "bin" || name == "binnormalizer")
{
return make_shared<BinNormalizer>();
}
LOG(WARNING) << name << " is not supported now, do not use normalzier, return nullptr";
return nullptr;
}
? ?
static NormalizerPtr CreateNormalizer(string name, string path)
{
NormalizerPtr normalizer = CreateNormalizer(name);
if (normalizer != nullptr)
{
normalizer->Load(path); //normalzier直接序列化
}
return normalizer;
}
? ?
@TODO 确认下是否没有办法直接序列化shared ptr,
另外可以尝试下开源的专门序列化库creal,creal仿照boost 序列化 同时boost序列化只支持binary,文本,xml三种序列化,文本序列化可读性不强,binary速度最快,xml可读性最高速度慢一些。我一般只用binary和xml格式。而creal 支持json格式的输出,号称支持shared ptr
? ?
同一个模型boost序列化速度
?? | Binary | Text |
Save | 1.8 | 2.29 |
Load | 1.9 | 2.67 |
? ?
? ?
? ?
friend class boost::serialization::access;
template<class Archive>
void serialize(Archive &ar, const unsigned int version)
{
/*????????ar & boost::serialization::base_object<Predictor>(*this);
ar & _weights;
ar & _bias;*/ //这种写法只支持binary
ar & BOOST_SERIALIZATION_BASE_OBJECT_NVP(Predictor);
ar & BOOST_SERIALIZATION_NVP(_weights); //这样宏比较方便 如果需要改名字比如_weights->weights可以使用原函数
ar & BOOST_SERIALIZATION_NVP(_bias);
}
? ?
? ?
Predictors]$ get-lines.py LinearPredictor.h 98 99 | gen-boost-seralize-xml.py
? ?
friend class boost::serialization::access;
template<class Archive>
void serialize(Archive &ar, const unsigned int version)
{
ar & BOOST_SERIALIZATION_NVP(_weights);
ar & BOOST_SERIALIZATION_NVP(_bias);
}
? ?
4. 对于Predictor 默认是Save二进制,可选的SaveXml方式这个自动支持,可选的SaveText这个是特定的Precitor子类型如果有需要手动写的文本输出格式。
xml输出类似这样
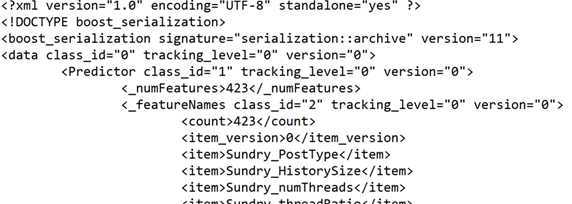
? ?
转换为json
xml2json.py model.xml > model.json
more model.json

采用json pretty print来查看json文件
jpp.py model.json | more

? ?
Xml2tojson.py 利用xmltodict 进行向json的转换
? ?
import sys,os
import xmltodict, json
doc = xmltodict.parse(open(sys.argv[1]), process_namespaces=True)
print json.dumps(doc)
? ?
Jpp.py
import sys,os
import json
s = open(sys.argv[1]).readline().decode(‘gbk‘)
print json.dumps(json.loads(s),sort_keys=True, indent=4, ensure_ascii=False).encode(‘gbk‘)
? ?
小的模型输出直接看xml文本就好,如果数据比较多处理xml不是很方便,json好一些 用python,
但是如果转换为json的map也不是很方便因为你要按照key去访问string类型是没有自动提示的
? ?
In [6]: import json
? ?
In [7]: m = json.loads(open(‘./model.json‘).readline())
? ?
In [8]: m.keys()
Out[8]: [u‘boost_serialization‘]
? ?
In [9]: m[‘boost_serialization‘].keys()
Out[9]: [u‘@version‘, u‘@signature‘, u‘data‘]
? ?
In [18]: m[‘boost_serialization‘][‘data‘][‘_trees‘][‘item‘][0].keys()
Out[18]:
[u‘_gainPValue‘,
u‘@tracking_level‘,
u‘@class_id‘,
u‘_lteChild‘,
u‘_gtChild‘,
u‘_maxOutput‘,
u‘_leafValue‘,
u‘NumLeaves‘,
u‘_splitGain‘,
u‘_splitFeature‘,
u‘_previousLeafValue‘,
u‘_threshold‘,
u‘@version‘,
u‘_weight‘]
? ?
In [19]: m[‘boost_serialization‘][‘data‘][‘_trees‘][‘item‘][0][‘_splitGain‘][‘item‘][10]
Out[19]: u‘3.89894126598927926e+00‘
? ?
由于python提示的时候_开头的作为private默认是不提示的,因此做了修改
#include "conf_util.h"
#include <boost/serialization/nvp.hpp>
#define GEZI_SERIALIZATION_NVP(name)
boost::serialization::make_nvp(gezi::conf_trim(#name).c_str(), name)
? ?
这样展示的就是gainPvalue这样没有_开头了
? ?
利用python的自省功能可以把json解析得到的dict数据,string作为key的转为一个python object方便访问如下
def h2o(x):
if isinstance(x, dict):
return type(‘jo‘, (), {k: h2o(v) for k, v in x.iteritems()})
elif isinstance(x, list):
l = [h2o(item) for item in x]
return l
else:
return x
? ?
def h2o2(x):
if isinstance(x, dict):
return type(‘jo‘, (), {k: h2o2(v) for k, v in x.iteritems()})
elif isinstance(x, list):
return type(‘jo‘, (), {"i" + str(idx): h2o2(val) for idx, val in enumerate(x)})
return l
else:
return x
? ?
def xmlfile2obj(path):
import xmltodict
doc = xmltodict.parse(open(path), process_namespaces=True)
return h2o(doc)
? ?
def xmlfile2obj2(path):
import xmltodict
doc = xmltodict.parse(open(path), process_namespaces=True)
return h2o2(doc)
? ?
这样对于序列化之后的xml文件可以直接使用 m = xmlfile2obj(‘*.xml‘) 或者 m = xml2obj2(‘*.xml‘)
建议是用第一种,是标准转换,提供第二个接口主要是python的自动提示对于list的item就没有了,只能dir()查看。。
第二种将[3]这样转为了.i3也就是去掉了所有list都用dict表示。
? ?
m = xmlfile2obj(‘./model.xml‘)
In [14]: m.boost_serialization.data.trees.item[0].splitGain.item[13]
Out[14]: u‘3.26213753939964946e+00‘
? ?
m = xmlfile2obj2(‘./model.xml‘)
In [16]: m.boost_serialization.data.trees.item.i0.splitGain.item.i13
Out[16]: u‘3.26213753939964946e+00‘
? ?
? ?
? ?
? ?
? ?
? ?
标签:style blog http color io os 使用 ar for
原文地址:http://www.cnblogs.com/rocketfan/p/4003362.html