标签:style blog http color io os ar for sp
本想抓取网易摄影上的图,但发现查看html源代码时找不到图片的url,但firebug却能定位得到。(不知道为什么???)
目标是抓取前50页的爆乳图,代码如下:
import urllib2,urllib,re,os ‘‘‘ http://www.dbmeizi.com/category/2?p=% ‘‘‘ def get_url_from_douban(): url_list=[] p=re.compile(r‘‘‘<img.*?src="(.+?\.jpg)‘‘‘) #找出发布人的标题和url for i in range(1,50): target = r"http://www.dbmeizi.com/category/2?p=%d"%i # print target req=urllib2.urlopen(target) result=req.read() matchs=p.findall(result) url_list.extend(matchs) # print matchs # print "-----"*40 return url_list def download_pic(url_list): # print url_lists count=0 if not os.path.exists(‘/tmp/pic‘): os.mkdir(‘/tmp/pic/‘) for url in url_list: urllib.urlretrieve(url,‘/tmp/pic/‘+str(count)+‘.jpg‘) count+=1 if __name__==‘__main__‘: # start_time=time.time() print "start getting url..." url_lists=get_url_from_douban() print "url getted! downloading..." download_pic(url_lists) print "download finish!!!" # cost_time=time.time() - start_time() # print cost_time # download_pic(url_lists)
------------------------------------------------------------------------------
/System/Library/Frameworks/Python.framework/Versions/2.7/bin/python /Users/lsf/PycharmProjects/some_subject/get_doubanmeizi_pic.py
start getting url...
url getted! downloading...
download finish!!!
Process finished with exit code 0
运行结果如图:
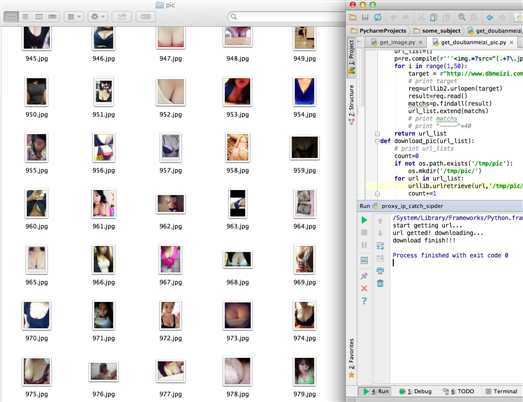
只是一个简单的实现方式,没有考虑性能,速度挺慢的。
ps:贴图会不会被查水表!!??
一个简单的python爬虫,以豆瓣妹子“http://www.dbmeizi.com/category/2?p= ”为例
标签:style blog http color io os ar for sp
原文地址:http://www.cnblogs.com/alexkn/p/4003436.html