标签:des style blog http color os ar for 文件
#! /usr/bin/env python #coding=utf-8
# by chuxing 2014/10/1
# qq:121866673
from os.path import dirname, abspath from extract import extract,extract_all import urllib2 # 抓取搜索页面 mainurl = ‘http://desk.**.com.cn‘ hosturl = ‘http://desk.**.com.cn/pc/‘ ‘‘‘ 循环页面列表 ==================== 抓取主题页面地址 返回主题页面地址列表 ‘‘‘ hreflist = [] def spider1(): for page in range(0,236):#236 # 页面地址规律,第一张主题页面按数组递增到236页 i_pageurl = hosturl+str(page+1)+‘.html‘ i_urlopen = urllib2.urlopen(i_pageurl) i_readhtml = i_urlopen.read() print ‘main:‘,i_pageurl,len(i_readhtml) i_htmldata = extract_all(‘<ul class="pic-list2 clearfix">‘,‘</ul>‘,i_readhtml) # print newdata i_htmldata = extract_all(‘href="‘,‘"‘,str(i_htmldata)) # print newdata for d in i_htmldata: i_pageurl = mainurl+d hreflist.append(i_pageurl) # print ‘imgpage:‘,i_pageurl print ‘imgpagecount:‘,len(hreflist) ‘‘‘ 抓取主题中的每一张图片的页面地址 返回图片页面地址列表 ‘‘‘ contentpage = [] def spider2(): for cp in hreflist: try: i_urlopen = urllib2.urlopen(cp) i_readhtml = i_urlopen.read() print ‘main:‘,cp,len(i_readhtml) i_htmldata = extract_all(‘<div class="photo-list-box">‘,‘</ul>‘,i_readhtml) # print i_htmldata i_htmldata = extract_all(‘href="‘,‘"‘,str(i_htmldata)) # print ‘i_htmldata:‘+str(i_htmldata) for i in i_htmldata: i_pageurl = mainurl+i contentpage.append(i_pageurl) # print ‘imgpage:‘,i_pageurl except: pass ‘‘‘ 抓图每一张图片页面中图片最大分辨率的页面地址 返回图片页面列表 ‘‘‘ imgpage = [] def spider3(): for ip in contentpage: try: i_urlopen = urllib2.urlopen(ip) i_readhtml = i_urlopen.read() # print ‘main:‘,ip,len(i_readhtml) i_htmldata = extract_all(‘<dd id="tagfbl">‘,‘</dd>‘,i_readhtml) # print i_htmldata i_htmldata = extract_all(‘href="‘,‘"‘,str(i_htmldata)) # print ‘i_htmldata:‘+str(i_htmldata) i_pageurl = mainurl + i_htmldata[0] imgpage.append(i_pageurl) print ‘imgpage:‘,i_pageurl # for i in i_htmldata: # i_pageurl = mainurl+i # contentpage.append(i_pageurl) # print ‘imgpage:‘,i_pageurl except: pass ‘‘‘ 抓取图片列表中的图片地址构造列表 返回图片地址列表 ‘‘‘ imgurl = [] def spider4(): for img in imgpage: try: i_urlopen = urllib2.urlopen(img) i_readhtml = i_urlopen.read() # print ‘main:‘,ip,len(i_readhtml) i_htmldata = extract_all(‘<img src="‘,‘"‘,i_readhtml) # print i_htmldata imgurl.append(i_htmldata[0]) print i_htmldata[0] except: pass # 程序所在文件夹路径 PREFIX = dirname(abspath(__file__)) spider1() spider2() spider3() spider4() # 生成bat文件,需要wget组件支持 with open("%s\pic\downpic.bat"%PREFIX,"w") as down: for n in range(0,len(imgurl)): data = ‘wget %s -O "%s\pic\%s.jpg"\n‘%(imgurl[n],PREFIX,str(n)) down.write(data
extract库文件:
#! /usr/bin/env python #coding=utf-8 ‘‘‘ 取出所有begin和end之间的字符串,并以列表的方式返回。 ‘‘‘ def extract(begin, end, html): if not html: return ‘‘ start = html.find(begin) if start >= 0: start += len(begin) if end is not None: end = html.find(end, start) if end is None or end >= 0: return html[start:end].strip() def extract_all(begin, end, html): return map(str.strip, _extract_all(begin, end, html)) def _extract_all(begin, end, html): if not html: return ‘‘ result = [] from_pos = 0 while True: start = html.find(begin, from_pos) if start >= 0: start += len(begin) endpos = html.find(end, start) if endpos >= 0: result.append(html[start:endpos]) from_pos = endpos+len(end) continue break return result
需要wget组件。
结果:
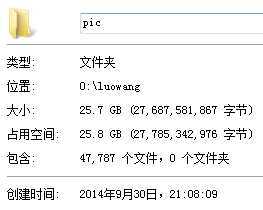
声明:代码仅供研究学习用,作者不对滥用本代码产生的后果负责。
标签:des style blog http color os ar for 文件
原文地址:http://www.cnblogs.com/zxlovenet/p/4003494.html