标签:with creat 表达 原码 agent comment open lis created
爬取糗事百科的段子:
1.用xpath分析首要爬去内容的表达式;
2.用发起请求,获得原码;
3.用xpath分析源码,提取有用信息;
4.由python格式转为json格式,写入文件
#_*_ coding: utf-8 _*_
‘‘‘
Created on 2018年7月17日
@author: sss
function: 爬取糗事百科里面的内容
‘‘‘
import requests
import json
from lxml import etree
url = "https://www.qiushibaike.com/8hr/page/3/"
headers = {‘User-Agent‘: ‘Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1 Trident/5.0;‘}
html= requests.get(url, headers = headers).text
# print(html)
#将返回的字符串格式,转为HTML DOM模式
text = etree.HTML(html)
#获得包含每个糗事的链表
#返回所有糗事的节点位置,contains()模糊查询方法,第一个参数为要匹配的标签,第二个参数为标签的内容
node_list = text.xpath(‘//div[contains(@id, "qiushi_tag_")]‘)
items = {}
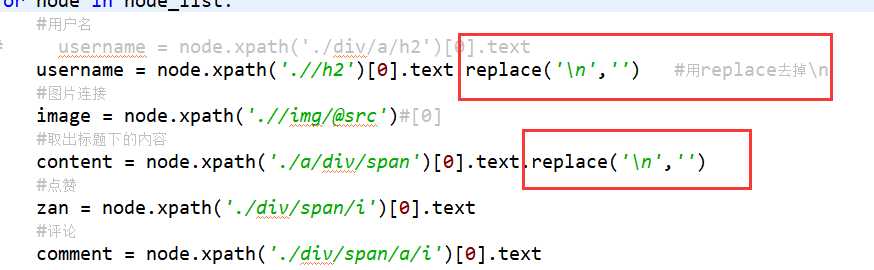
for node in node_list:
#用户名
# username = node.xpath(‘./div/a/h2‘)[0].text
username = node.xpath(‘.//h2‘)[0].text
#图片连接
image = node.xpath(‘.//img/@src‘)#[0]
#取出标题下的内容
content = node.xpath(‘./a/div/span‘)[0].text
#点赞
zan = node.xpath(‘./div/span/i‘)[0].text
#评论
comment = node.xpath(‘./div/span/a/i‘)[0].text
items = {
‘username‘ : username,
‘image‘ : image,
‘content‘ : content,
‘zan‘ : zan,
‘comments‘ : comment
}
#把python格式的转换为json格式,此时转换成了字符串,就可以写入糗事段子.txt文件中了
we=json.dumps(items, ensure_ascii=False)
print(we)
with open(‘qiushi.txt‘, ‘a‘, encoding=‘utf-8‘) as f: #注意在这里转为utf-8格式
f.write((we + ‘\n‘))
效果:


标签:with creat 表达 原码 agent comment open lis created
原文地址:https://www.cnblogs.com/zhumengdexiaobai/p/9322779.html