标签:line 请求 .com lan 序列号 height 详细 open hyper
本篇主要为为了实现WEB服务器,其中包含了HTTP协议的理解,以及TCP的三次握手、四次挥手等方面相关知识,同时还包含了关于web浏览器与服务器之间的通信过程。
通常在我们上网时会在浏览器的地址栏输入网址,①、浏览器首先要对URL进行解析,②、随后通过HTTP协议定义消息内容和步骤,即规定发送请求的格式;③、根据服务器的域名通过操作系统下的解析器(DNS客户端)向最近的DNS服务器发送请求获取目标服务器的IP地址并存储在指定的内存空间内,,通过操作系统下的协议栈以及socket库将消息发送出去,④、当服务器接收到请求消息会返回响应消息(该响应消息也是根据HTTP协议定义消息内容的格式)最后经过类似的过程返回给web浏览器。接下来我们根据这几个步骤进行解析:
1.浏览器怎么对URL进行解析?

通常常用的访问数据的机制有以下几种:
HTTP协议:即 Hypertxt Transfer Protocal 超文本传送协议)访问Web服务器,例如:http://www.baidu.com/dir/file1.html
FTP协议:File Transfer Protocol,文件传输协议,主要用于文件的上传和下载,例如:ftp://ftp.glasscom.com/dir/file1.html
File协议:本地文件传输协议,例如:file://localhost/c:path/file1.zip。
maito协议:该协议可以创建一个指向电子邮件地址的超级链接,通过该链接可以在Internet中发送电子邮件。例如:maito.tone@glasscom.com
等等
2、根据HTTP协议生成怎样格式的请求消息和接收的响应消息?
需要我们需要知道的是:
HTTP协议:
我们知道服务端和客户端之间进行通信过程便是:首先客户端根据HTTP协议给服务端发送请求消息,随后服务器给客户端发送响应消息。那么请求消息和响应消息具体是什么样的呢?
请求消息:
1 # 以下便是浏览器给服务器发送的请求消息 2 3 GET / HTTP/1.1 4 Host: www.baidu.com 5 Connection: keep-alive 6 Cache-Control: max-age=0 7 Upgrade-Insecure-Requests: 1 8 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36 9 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8 10 Accept-Encoding: gzip, deflate, br 11 Accept-Language: zh-CN,zh;q=0.9 12 13 #接下来对这些信息进行解析:
第一部分:请求头行,包含请求类型、URI、HTTP协议版本;
请求信息类型通常有:get、post、put等等;
第二部分:即紧跟第一行之后的,请求头部,包含服务器所使用的说明信息;接下来解释一下这些说明信息的意思:
1、host:请求web服务器的域名地址
2、Connection: 表示是否持久连接;即keep-alive表示持久连接;
3、Cache-Control:指定请求和响应的缓存机制;no-cache(不能缓存)、no-store(在请求消息中发送将使得请求和响应消息都不使用缓存)、
max-age(客户机可以接收生存期不大于指定时间(以秒为单位)的响应)、max-stale(客户机可以接收超出超时期间的响应消息)、min-fresh(客户机可以接收响应时间小于当前时间加上指定时间的响应)、
only-if-cached等等
4、User-Agent: HTTP协议运行的浏览器类型的详细信息;比如:谷歌/67.0.3396.99
5、Accept: 指浏览器可以接收的内容类型;
6、Accept-Encoding: 客户端浏览器可以支持的web服务器返回内容压缩编码类型;
7、Accept-Language:浏览器支持的语言类型,
8、Cookie: 某些网站为了辨别用户身份、进行 session 跟踪而储存在用户本地终端上的数据(通常经过加密);例如当我们上网时,某些网站能准确的推送我们想要的信息。
第三部分:"\r\n" --> 分割header和body部分的分界线
响应消息:
1 # 响应消息 2 3 HTTP/1.1 200 OK 4 Bdpagetype: 1 5 Bdqid: 0x8bda58760001baca 6 Cache-Control: private 7 Connection: Keep-Alive 8 Content-Encoding: gzip 9 Content-Type: text/html 10 Cxy_all: baidu+10412ee70bbb9e9eec33f3dbcb3e2df7 11 Date: Wed, 18 Jul 2018 03:26:13 GMT 12 Expires: Wed, 18 Jul 2018 03:25:42 GMT 13 Server: BWS/1.1 14 Set-Cookie: BDSVRTM=0; path=/ 15 Set-Cookie: BD_HOME=0; path=/ 16 Set-Cookie: H_PS_PSSID=1435_21118_20929; path=/; domain=.baidu.com 17 Strict-Transport-Security: max-age=172800 18 Vary: Accept-Encoding 19 X-Ua-Compatible: IE=Edge,chrome=1 20 Transfer-Encoding: chunked 21 22 # 响应消息的解析:
第一部分:响应头,包含:HTTP协议版本、状态码(1XX-告知请求处理进度和情况,2XX-成功,3XX-表示需要进一步操作,4XX-客户端错误;5XX-服务器错误;)
第二部分:响应头部,包含服务器发送的附加信息;这里针对几个重要的进行解析说明:
https://www.cnblogs.com/mylanguage/p/5689879.html -->有详细说明。
第三部分:"\r\n" --分割header和body的分割线
第四部分:包含服务器向客户端发送的数据。
以上就请求消息和响应消息的内容格式,由浏览器或者客户端将信息根据HTTP协议转换而来。
3、怎么根据域名获取服务器的IP地址?
前面便提到了要想实现两台终端之间的通信必须知道对方的IP地址和端口号,但是我们在浏览器地址栏输入的仅是域名,那么我们怎么获得目标服务器的IP地址呢?
首先web浏览器会调用操作系统下的解析器即DNS客户端,随后由解析器发送请求给最近的DNS服务器(发送过程与C/S架构模型一样),若所需域名不在最近的DNS服务器,则由该服务器向域的DNS服务器发送询查消息,若该域名不在根域DNS服务器上,则让最近DNS服务器向其下级域发送询查消息,以此递归便能查找到该域名所在域的DNS服务器,最后由请求的DNS服务器发送响应消息到最近的DNS服务器,得到该域名的IP地址;
同时DNS服务器有一个缓存功能,可以记住之前查询过的域名,如果所查询的域名和相关信息已经在缓存中,那么久可以直接返回响应。
首先我们需要知道在客户端与服务器基于TCP协议建立联系时需要经过三次握手,而在断开连接时需经历四次挥手的过程,那么我们来看一下该过程是怎样的?
三次握手:
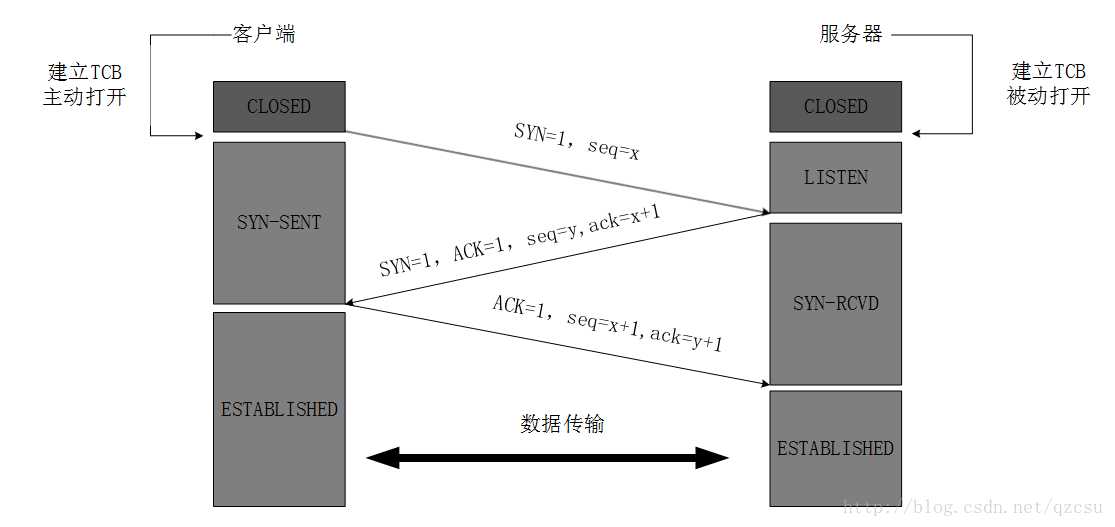
解析:
首先服务器通常是处于监听的状态,而客户端通常是主动建立连接的一方,即
四次挥手:
同时我们需要知道的是:通常服务器不会主动断开连接,而是客户端主动断开连接。
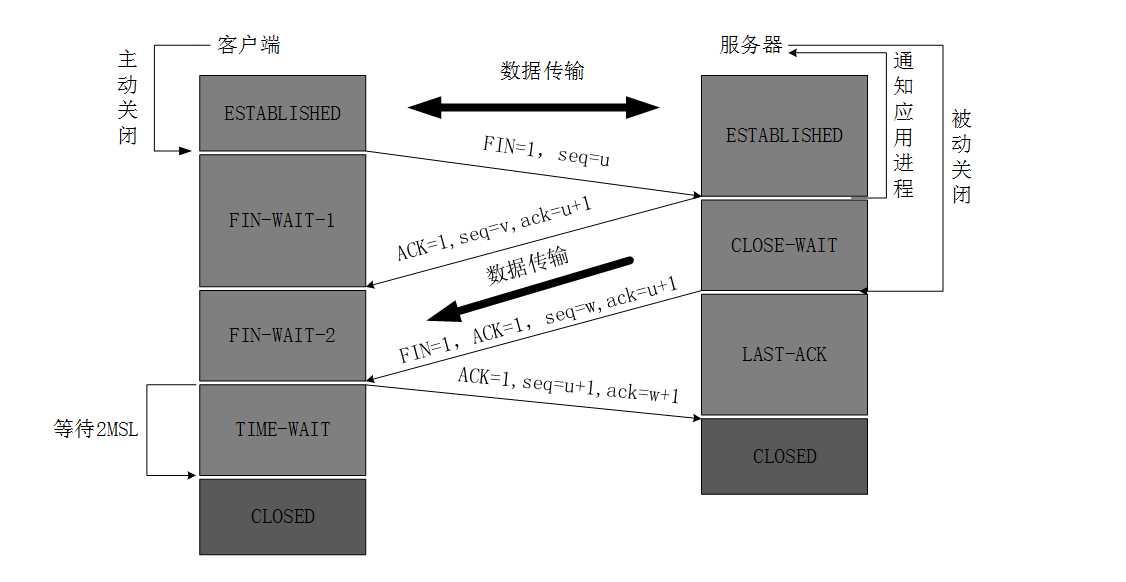
1、客户端进程发出连接释放报文,并且停止发送数据。释放数据报文首部,FIN=1,其序列号为seq=u(等于前面已经传送过来的数据的最后一个字节的序号加1),此时,客户端进入FIN-WAIT-1(终止等待1)状态。 TCP规定,FIN报文段即使不携带数据,也要消耗一个序号。
直接看示例:
import socket import re def server_client(server_client_socket): """接收来自浏览器的数据和发送报文""" # 对接收到的请求消息进行解析 request = server_client_socket.recv(1024).decode("utf-8") # 请求消息头部格式大概为 : GET /index.html HTTP/1.1 request_lines = request.splitlines() # 将接收到的信息按行分割,并返回列表 ret = re.match(r"[^/]+(/[^ ]*)",request_lines[0]) # 若正则表达式匹配成功有返回值,则检测是由为 "/"或者空字符,则设置默认文件为/index.html文件 if ret: filename = ret.group(1) if filename == "/" or filename == "": filename = "/index.html" # print(request) respone = "HTTP/1.1 200 OK\r\n" respone += "\r\n" # respone += "<h2>hello world</h2>" # 检测服务器中是否有该文件,有则发生内容,无则返回错误 try: f = open("html"+ filename,"rb") except: respone = "HTTP/1.1 404 Not found file \r\n" respone += "\r\n" respone += "<h1>Not found File</h1>" respone = respone.encode("utf-8") else: file_content = f.read() f.close() respone = respone.encode("utf-8") + file_content # 字节之间的拼接 server_client_socket.send(respone) server_client_socket.close() def main(): # 1、创建套接字对象 server_socket = socket.socket(socket.AF_INET,socket.SOCK_STREAM) server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) # 2、绑定本地信息 server_socket.bind(("",6969)) # 3、监听 server_socket.listen(128) while True: # 4、等待客户端连接 server_client_socket,client_addr = server_socket.accept() # 5、服务客户端 server_client(server_client_socket) server_socket.close() if __name__ == "__main__": main()
这样就实现了一个静态的web服务器,可以接收web浏览器的请求,对请求的数据进行解析,通过正则表达式得到需要浏览器请求的页面的文件名,通过文件的读取得到数据,并将内容符合给web浏览器。
标签:line 请求 .com lan 序列号 height 详细 open hyper
原文地址:https://www.cnblogs.com/littlefivebolg/p/9320901.html