标签:lib 部分 sch 连接 sele 存储 failure shang gluster
glusterfs 怎么集群,网上一搜铺天盖地的
可利用这个特点做单节点高可用,因为K8S 哪怕节点宕机了 master 会在随意一台节点把挂掉的复活
当然我是在自己的环境下跑,经过网络的glusterfs,数据传输,等都有一定的性能损耗,对网络要求也特别高
小文件存储性能也不高等问题.
这里记录一下rabbitmq 单机高可用情景,mysql,mongodb, redis 等,万变不离其宗
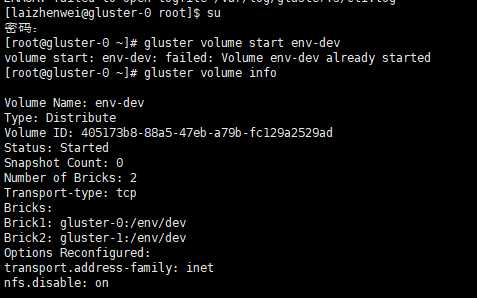
事先创建好了 volume,卷名为 env-dev
随便找个客户机挂载
mount -t glusterfs 192.168.91.135:/env-dev /mnt/env/dev
预先创建需要的文件夹
mkdir -p /mnt/env/dev/rabbitmq/mnesia
编写 glusterfs endpoint
[root@k8s-master-0 dev]# cat pv-ep.yaml apiVersion: v1 kind: Endpoints metadata: name: glusterfs namespace: env-dev subsets: - addresses: - ip: 192.168.91.135 - ip: 192.168.91.136 ports: - port: 49152 protocol: TCP --- apiVersion: v1 kind: Service metadata: name: glusterfs namespace: env-dev spec: ports: - port: 49152 protocol: TCP targetPort: 49152 sessionAffinity: None type: ClusterIP
编写 pv,注意这里path 是 volume名称 + 具体路径
[root@k8s-master-0 dev]# cat rabbitmq-pv.yaml apiVersion: v1 kind: PersistentVolume metadata: name: rabbitmq-pv labels: type: glusterfs spec: storageClassName: rabbitmq-dir capacity: storage: 3Gi accessModes: - ReadWriteMany glusterfs: endpoints: glusterfs path: "env-dev/rabbitmq/mnesia" readOnly: false
编写pvc
[root@k8s-master-0 dev]# cat rabbitmq-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: rabbitmq-pvc
namespace: env-dev
spec:
storageClassName: rabbitmq-dir
accessModes:
- ReadWriteMany
resources:
requests:
storage: 3Gi
创建endpoint pv pcv
kubectl apply -f pv-ep.yaml kubectl apply -f rabbitmq-pv.yaml
kubectl apply -f rabbitmq-pvc.yaml



使用方式,红字部分
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: ha-rabbitmq
namespace: env-dev
spec:
replicas: 1
selector:
matchLabels:
app: ha-rabbitmq
template:
metadata:
labels:
app: ha-rabbitmq
spec:
#hostNetwork: true
hostname: ha-rabbitmq
terminationGracePeriodSeconds: 60
containers:
- name: ha-rabbitmq
image: 192.168.91.137:5000/rabbitmq:3.7.7-management-alpine
securityContext:
privileged: true
env:
- name: "RABBITMQ_DEFAULT_USER"
value: "rabbit"
- name: "RABBITMQ_DEFAULT_PASS"
value: "rabbit"
ports:
- name: tcp
containerPort: 5672
hostPort: 5672
- name: http
containerPort: 15672
hostPort: 15672
livenessProbe:
failureThreshold: 3
httpGet:
path: /
port: 15672
scheme: HTTP
initialDelaySeconds: 20
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
readinessProbe:
failureThreshold: 3
httpGet:
path: /
port: 15672
scheme: HTTP
initialDelaySeconds: 20
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
volumeMounts:
- name: date
mountPath: /etc/localtime
- name: workdir
mountPath: "/var/lib/rabbitmq/mnesia"
volumes:
- name: date
hostPath:
path: /usr/share/zoneinfo/Asia/Shanghai
- name: workdir
persistentVolumeClaim:
claimName: rabbitmq-pvc
---
apiVersion: v1
kind: Service
metadata:
name: ha-rabbitmq
namespace: env-dev
labels:
app: ha-rabbitmq
spec:
ports:
- name: tcp
port: 5672
targetPort: 5672
- name: http
port: 15672
targetPort: 15672
创建rabbitmq pod以及service.
kubectl create -f ha-rabbitmq.yaml

分配到了第一个节点,看看数据文件

在管理页面创建一个创建一个 virtual host
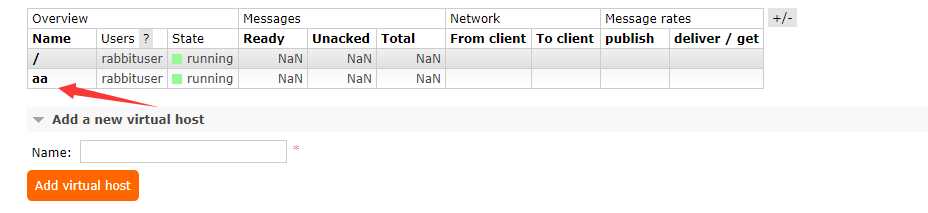
环境东西太多,这里就不暴力关机了,直接删除再创建
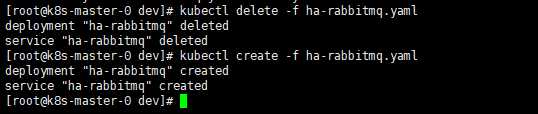

这次分配到节点0
看看刚才创建的virtual host
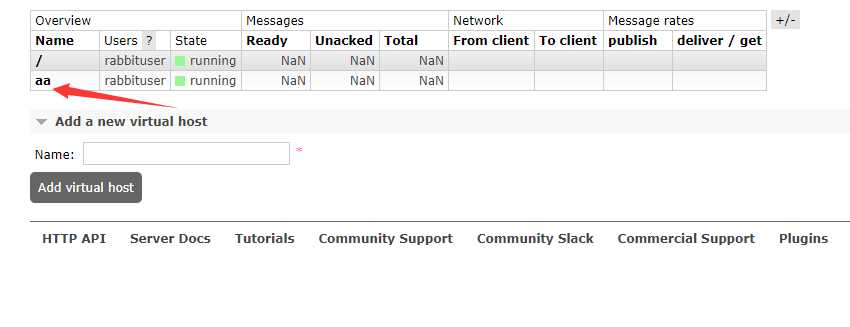
还健在
haproxy 代理
[root@localhost conf]# cat haproxy.cfg
global
chroot /usr/local
daemon
nbproc 1
group nobody
user nobody
pidfile /haproxy.pid
#ulimit-n 65536
#spread-checks 5m
#stats timeout 5m
#stats maxconn 100
########默认配置############
defaults
mode tcp
retries 3 #两次连接失败就认为是服务器不可用,也可以通过后面设置
option redispatch #当serverId对应的服务器挂掉后,强制定向到其他健康的服务器
option abortonclose #当服务器负载很高的时候,自动结束掉当前队列处理比较久的链接
maxconn 32000 #默认的最大连接数
timeout connect 10s #连接超时
timeout client 8h #客户端超时
timeout server 8h #服务器超时
timeout check 10s #心跳检测超时
log 127.0.0.1 local0 err #[err warning info debug]
########MariaDB配置#################
listen mariadb
bind 0.0.0.0:3306
mode tcp
balance leastconn
server mariadb1 192.168.91.141:3306 check port 3306 inter 2s rise 1 fall 2 maxconn 1000
server mariadb2 192.168.91.142:3306 check port 3306 inter 2s rise 1 fall 2 maxconn 1000
server mariadb3 192.168.91.143:3306 check port 3306 inter 2s rise 1 fall 2 maxconn 1000
#######RabbitMq配置#################
listen rabbitmq
bind 0.0.0.0:5672
mode tcp
balance leastconn
server rabbitmq1 192.168.91.141:5672 check port 5672 inter 2s rise 1 fall 2 maxconn 1000
server rabbitmq2 192.168.91.142:5672 check port 5672 inter 2s rise 1 fall 2 maxconn 1000
server rabbitmq3 192.168.91.143:5672 check port 5672 inter 2s rise 1 fall 2 maxconn 1000
#######Redis配置#################
listen redis
bind 0.0.0.0:6379
mode tcp
balance leastconn
server redis1 192.168.91.141:6379 check port 6379 inter 2s rise 1 fall 2 maxconn 1000
server redis2 192.168.91.142:6379 check port 6379 inter 2s rise 1 fall 2 maxconn 1000
server redis3 192.168.91.143:6379 check port 6379 inter 2s rise 1 fall 2 maxconn 1000
nginx 代理管理页面
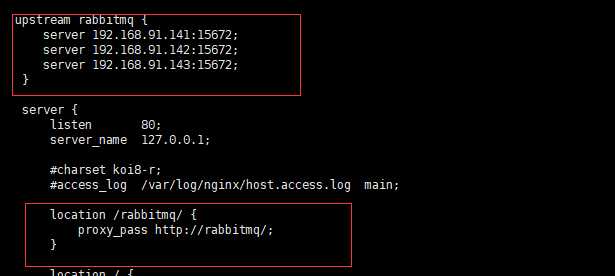
使用glusterfs 作为 kubernetes PersistentVolume PersistentVolumeClaim 持久化仓库,高可用Rabbitmq,高可用mysql,高可用redis
标签:lib 部分 sch 连接 sele 存储 failure shang gluster
原文地址:https://www.cnblogs.com/sweetchildomine/p/9343745.html