标签:长度参数 udp协议 数据报 enc 面向 输出 可靠 结构 lse
远程执行命令
先来学习一个新模块 , 一会用到的..
新模块: subprocess 执行系统命令 r = subprocess.Popen(‘ls‘,shell=True,stdout=subprocess.PIPE, stderr=subprocess.PIPE) subprocess.Popen(a,b,c,d) a: 要执行的系统命令(str) b: shell = True 表示确定我当前执行的命令为系统命令 c: 表示正确信息的输出管道 d: 表示错误信息的输出管道
下边直接上代码,一看就懂. TCP的

import socket import subprocess sk = socket.socket() sk.bind((‘127.0.0.1‘,9090)) sk.listen() conn,addr = sk.accept() while 1: cmd = conn.recv(1024).decode(‘utf-8‘) res = subprocess.Popen(cmd,shell=True,stdout=subprocess.PIPE, stderr=subprocess.PIPE) std_out = res.stdout.read()# 读取正确的返回信息 std_err = res.stderr.read()# 读取错误的返回信息 if std_out: conn.send(std_out) else: conn.send(std_err) conn.close() sk.close()
import socket sk = socket.socket() sk.connect_ex((‘127.0.0.1‘,9090)) while 1: cmd = input(‘请输入一个命令>>>‘) sk.send(cmd.encode(‘utf-8‘)) print(sk.recv(204800000).decode(‘gbk‘)) sk.close()
就是引用了一个模块的功能,其他的还是简单的收发功能.
res=subprocess.Popen(cmd.decode(‘utf-8‘), shell=True, stderr=subprocess.PIPE, stdout=subprocess.PIPE) 的结果的编码是以当前所在的系统为准的,如果是windows,那么res.stdout.read()读出的就是GBK编码的,在接收端需要用GBK解码 且只能从管道里读一次结果 注意
--------------------粘包---------------------------
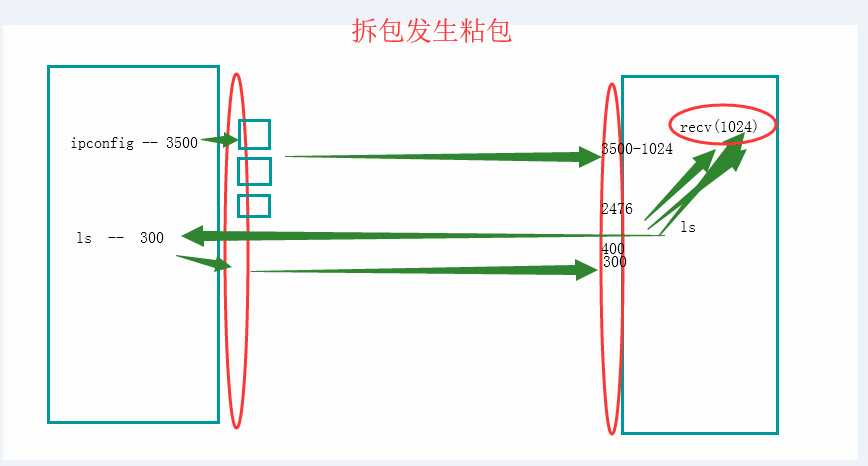
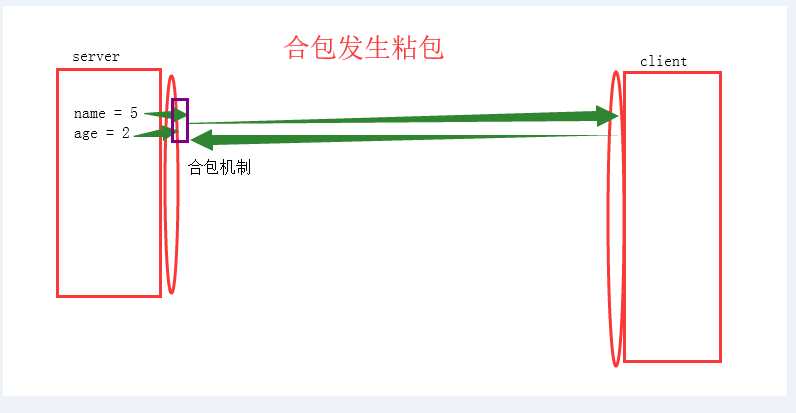
UDP不会发生黏包--------
UDP(user datagram protocol,用户数据报协议)是无连接的,面向消息的,提供高效率服务。
不会使用块的合并优化算法,, 由于UDP支持的是一对多的模式,所以接收端的skbuff(套接字缓冲区)采用了链式结构来记录每一个到达的UDP包,
在每个UDP包中就有了消息头(消息来源地址,端口等信息),这样,对于接收端来说,就容易进行区分处理了。
即面向消息的通信是有消息保护边界的。
对于空消息:tcp是基于数据流的,于是收发的消息不能为空,这就需要在客户端和服务端都添加空消息的处理机制,防止程序卡住,
而udp是基于数据报的,即便是你输入的是空内容(直接回车),也可以被发送,udp协议会帮你封装上消息头发送过去。
不可靠不黏包的udp协议:udp的recvfrom是阻塞的,一个recvfrom(x)必须对唯一一个sendinto(y),收完了x个字节的数据就算完成,若是y;x数据就丢失,
这意味着udp根本不会粘包,但是会丢数据,不可靠。
补充说明:
用UDP协议发送时,用sendto函数最大能发送数据的长度为:65535- IP头(20) – UDP头(8)=65507字节。
用sendto函数发送数据时,如果发送数据长度大于该值,则函数会返回错误。(丢弃这个包,不进行发送)
用TCP协议发送时,由于TCP是数据流协议,因此不存在包大小的限制(暂不考虑缓冲区的大小),这是指在用send函数时,数据长度参数不受限制。
而实际上,所指定的这段数据并不一定会一次性发送出去,如果这段数据比较长,会被分段发送,如果比较短,可能会等待和下一次数据一起发送。
黏包现象只发生在tcp协议中:
1.从表面上看,黏包问题主要是因为发送方和接收方的缓存机制、tcp协议面向流通信的特点。
2.实际上,主要还是因为接收方不知道消息之间的界限,不知道一次性提取多少字节的数据所造成的
解决方案------------
我们可以借助一个模块,这个模块可以把要发送的数据长度转换成固定长度的字节。这样客户端每次接收消息之前只要先接受这个固定长度字节的内容看一看接下来要接收的信息大小,那么最终接受的数据只要达到这个值就停止,就能刚好不多不少的接收完整的数据了。

文件上传解决粘包 的代码: 利用字典先传过去文件大小即可....
import socket import json import struct sk = socket.socket() sk.bind((‘127.0.0.1‘,9090)) sk.listen() conn,addr = sk.accept() dic_size = conn.recv(4)# 先接受4字节长度的一个bytes, 代表字典的大小 dic_size = struct.unpack(‘i‘,dic_size)[0]# 将这个特殊的bytes转变成原数字 dic_str = conn.recv(dic_size).decode(‘utf-8‘)# 根据字典大小去获取字典,以免和底下获取文件内容发生粘包 dic = json.loads(dic_str)# 反序列化 得到字典 opt filename filesize if dic[‘opt‘] == ‘upload‘: ‘‘‘接收文件‘‘‘ filename = ‘1‘+dic[‘filename‘]# 将文件名字修改,防止重名 with open(filename,‘wb‘) as f: while dic[‘filesize‘]: content = conn.recv(1024) f.write(content) dic[‘filesize‘] -= len(content) elif dic[‘opt‘] == ‘download‘: ‘‘‘给客户端传输文件‘‘‘ conn.close() sk.close()
import socket import os import json import struct sk = socket.socket() sk.connect((‘127.0.0.1‘,9090)) l = [‘upload‘,‘download‘] for i,v in enumerate(l): print(i+1,v) dic = {‘opt‘:None,‘filename‘:None,‘filesize‘:None} while 1: opt = input("请输入功能选项>>>")# 客户要执行的操作选项 if opt == ‘1‘: ‘‘‘upload‘‘‘ file_dir = input(‘请输入文件路径>>>‘)# ‘E:/sylar/python_workspace/day34/作业/时间同步机制_client.py‘ file_name = os.path.basename(file_dir)# 获取文件名字 file_size = os.path.getsize(file_dir)# 获取文件大小 dic[‘opt‘] = l[int(opt)-1] dic[‘filename‘] = file_name dic[‘filesize‘] = file_size dic_str = json.dumps(dic)# 将字典序列化成一个字符串形式的字典 dic_size = len(dic_str)# 获取字典的大小 ds = struct.pack(‘i‘,dic_size)# 把一个小于21.3E的一个数字转变成一个4字节长度的bytes sk.send(ds + dic_str.encode(‘utf-8‘))# 发送给服务器 with open(file_dir,‘rb‘) as f: while file_size: content = f.read(1024)# 文件内容 sk.send(content) file_size -= len(content) elif opt == ‘2‘: ‘‘‘download‘‘‘ pass else: print(‘有误‘) sk.close()

收发概括

标签:长度参数 udp协议 数据报 enc 面向 输出 可靠 结构 lse
原文地址:https://www.cnblogs.com/dalaoban/p/9346698.html
