标签:传统 直线 预处理 改进 过程 评估 最快 决策树 不同的
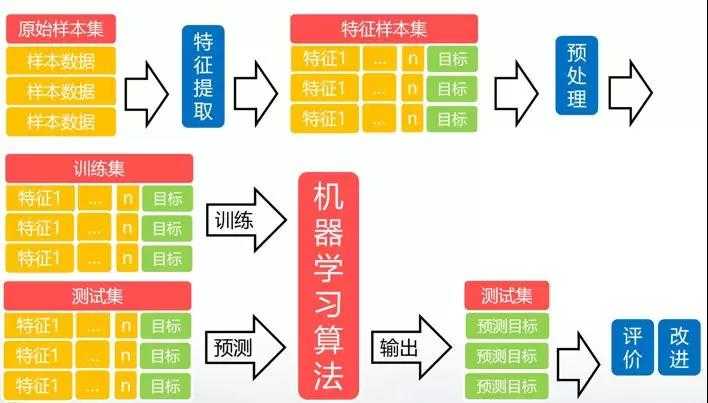
机器学习过程主要包括:数据的特征提取、数据预处理、训练模型、测试模型、模型评估改进等几部分
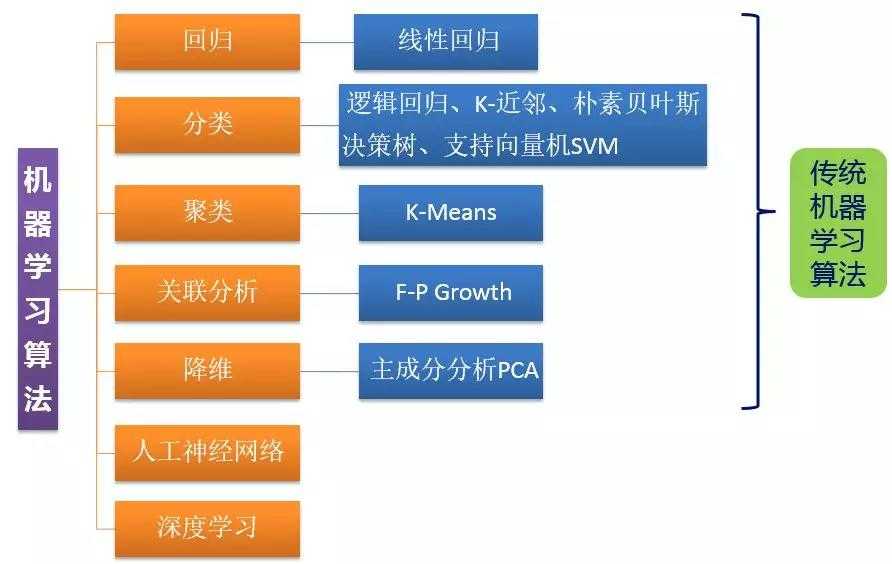
传统机器学习算法主要包括以下五类:
回归:建立一个回归方程来预测目标值,用于连续型分布预测
分类:给定大量带标签的数据,计算出未知标签样本的标签取值
聚类:将不带标签的数据根据距离聚集成不同的簇,每一簇数据有共同的特征
关联分析:计算出数据之间的频繁项集合
降维:原高维空间中的数据点映射到低维度的空间中
1 线性回归:找到一条直线预测目标值
2 逻辑回归:找到一条直线来分类数据
3 KNN:用距离度量最相近邻的分类标签
4 NB:选着后验概率最大的类为分类标签
5 决策树:构造一科熵值下降最快的分类树
决策树是一种树型结构,其中每个内部结点表示在一个属性上的测试,每个分支代表一个测试输出,每个叶结点代表一种类别。采用的是自顶向下的递归方法,选择信息增益最大的特征作为当前的分裂特征。
6 SVM:构造超平面,分类非线性数据
7 k-means:计算质心,聚类无标签数据
8 关联分析
9 PCA降维:减少数据维度,降低数据复杂度
标签:传统 直线 预处理 改进 过程 评估 最快 决策树 不同的
原文地址:https://www.cnblogs.com/ylHe/p/9367695.html