标签:acl 复数 str 最大值 重复记录 最大 平均值 分享图片 代码示例
视频课程:李兴华 Oracle从入门到精通
视频课程学习者:阳光罗诺
视频来源:51CTO学院
整体内容:
统计函数
在之前我们就学习过一个COUNT()函数,这个函数的主要作用是统计一张表之中的数据量的个数。和它功能与之类似的常用函数有五个:
范例:验证各个函数。
代码示例:
1 SELECT COUNT(*) 人数, AVG(sal)员工平均工资,SUM(sal)每月总支出,MAX(sal) 最高工资, MIN(sal)最低工资
2
3 FROM emp;

但是这些函数是允许和其他的函数嵌套的。
范例:统计出公司的平均雇佣年限。
代码示例:
1 SELECT AVG(MONTHS_BETWEEN(SYSDATE,hiredate)/12)
2 FROM emp;

范例:求出最早和最晚的雇佣日期(找到公司最早雇佣的雇员,以及公司最近雇佣的雇员日期)
代码示例:
1 SELECT MAX(hiredate) 最晚,MIN(hiredate) 最早 FROM emp;

以上的几个操作函数,在表中没有数据的时候,只有COUNT()函数会返回结果,其他的都是null。
范例:统计Bonus表
代码示例:
1 SELECT COUNT(*) 人数, AVG(sal)员工平均工资,SUM(sal)每月总支出,MAX(sal) 最高工资, MIN(sal)最低工资
2
3 FROM bonus;

在图中我们可以清楚的发现,此时只有COUNT()函数会返回最终的结果,即使没有数据也会返回0,而其他的统计函数结果都是null。
实际上针对于COUNT()函数有三种使用形式:【面试题】
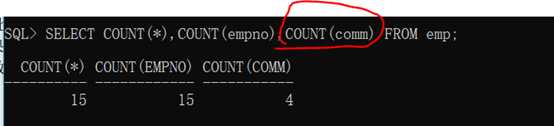
范例:统计查询一
代码示例:
1 SELECT COUNT(*),COUNT(empno),COUNT(comm) FROM emp;
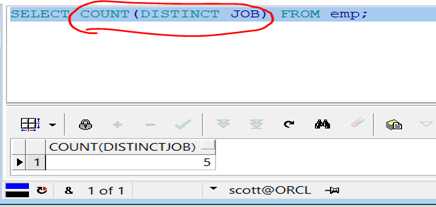
范例:查询二
代码示例:
1 SELECT COUNT(DISTINCT JOB) FROM emp;
分组统计
分组的前提是存在有重复,1但是允许单独一行记录进行分组。
如果要进行分组应该使用GROUP BY子句来完成,那么此时的语法结构形式如下:
语法结构:
|
【④选出所需要的数据列】SELECT [DISTINCT] * 分组列[别名],分组列[别名],分组列[别名]······ 【①确定数据来源(行和列的集合)】FROM 表名称 [别名],表名称 [别名],······ 【②筛选数据行】[WHERE 限定条件] 此时的条件可以是多个语法结构。 【③针对于筛选的行分组】[GROUP BY 分组字段,分组字段,······] 【⑤数据排序】[ORDER BY 排序字段 [ASC|DESC] 可以设置多个] |
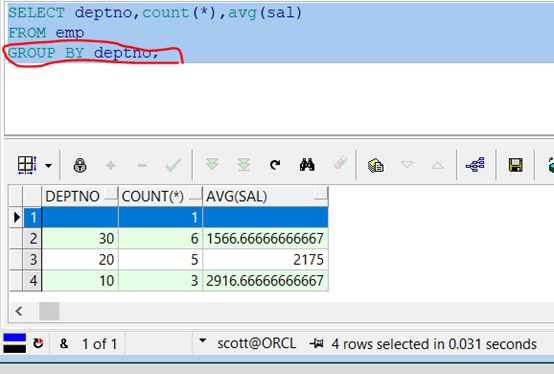
范例:根据部门编号分组,查询出每一个部门的编号、人数、平均工资。
代码示例:
1 SELECT deptno,count(*),avg(sal)
2
3 FROM emp
4
5 GROUP BY deptno;
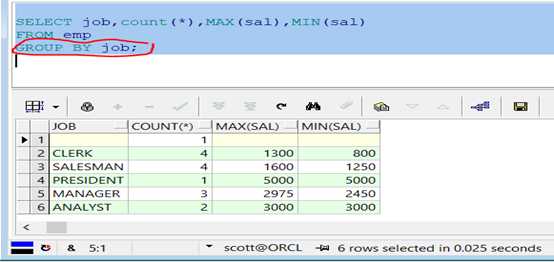
范例:根据职位分组,统计出每一个职位的人数,最低工资与最高工资。
代码示例:
1 SELECT job,count(*),MAX(sal),MIN(sal)
2
3 FROM emp
4
5 GROUP BY job;
查询结果如图:
在GROUP BY 子句中,之所以使用麻烦,是因为分组的时候有一些约定条件。
|
错误代码: |
正确代码: |
|
SELECT empno,COUNT(*) FROM emp; 错误提示: 第 1 行出现错误: ORA-00937: 不是单组分组函数 |
SELECT COUNT(*) FROM emp; |
|
错误代码: |
正确代码: |
|
SELECT ename,job,COUNT(*) FROM emp GROUP BY job; 错误提示: 第 1 行出现错误: ORA-00979: 不是 GROUP BY 表达式 |
SELECT job,COUNT(*) FROM emp GROUP BY job; |
|
错误代码: |
正确代码: |
|
SELECT deptno,MAX(AVG(sal)) FROM emp GROUP BY deptno; 错误提示: 第 1 行出现错误: ORA-00937: 不是单组分组函数 |
SELECT MAX(AVG(sal)) FROM emp GROUP BY deptno; |
多表查询与分析统计(重点)
对于GROUP BY子句而言,是在WHERE子句之后执行的,所以在使用时可以进行限定查询,也可以进行多表查询。
范例:查询出每个部门的名称、部门人数、平均工资。
第一步:查询出每一个部门的名称、雇员编号(COUNT(empno))、基本工资(AVG(sal))。
代码示例:
1 SELECT d.dname,e.empno,e.sal
2
3 FROM emp e,dept d
4
5 WHERE e.deptno=d.deptno;
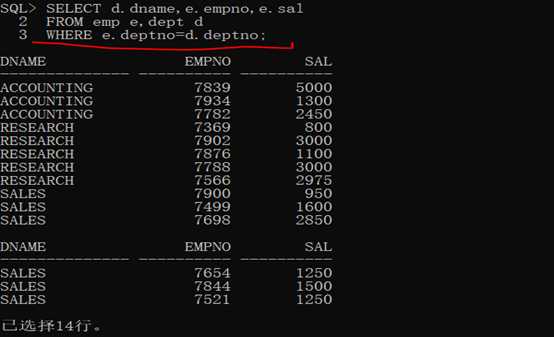
第二步:此时的查询结果中对于部门名称部分出现了重复的内容,按照分组来讲,只要是出现了数据的重复,那么就可以进行分组,只不过此时的分组是针对于临时表(查询结果),既然确定了dname上存在有重复记录,那么就直接针对于dname分组即可。
代码示例:
1 SELECT d.dname,COUNT(e.empno),AVG(e.sal)
2
3 FROM emp e,dept d
4
5 WHERE e.deptno=d.deptno
6
7 GROUP BY d.dname;
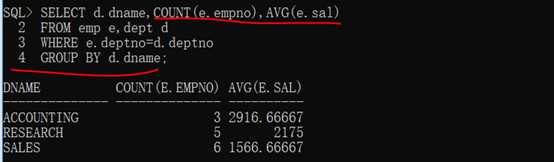
第三步:在dept表中存在有四个部门信息,而此时的要求也是统计所有的部门名称,如果发现数据不完整,立刻使用外连接。
代码示例:
1 SELECT d.dname,COUNT(e.empno),AVG(e.sal)
2
3 FROM emp e,dept d
4
5 WHERE e.deptno=d.deptno(+)
6
7 GROUP BY d.dname;
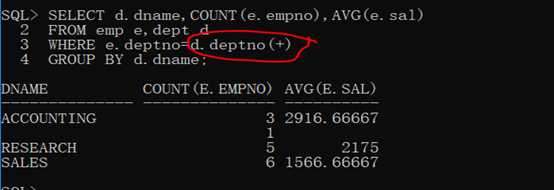
范例:查询每个部门的编号、名称、位置、部门人数、平均工资。
第一步:查询每一个部门的编号、名称、位置、雇员编号(COUNT())、工资(AVG(sal)).
代码示例:
1 SELECT d.deptno,d.dname,d.loc,e.empno,e.sal
2
3 FROM emp e,dept d
4
5 WHERE e.deptno(+)=d.deptno;
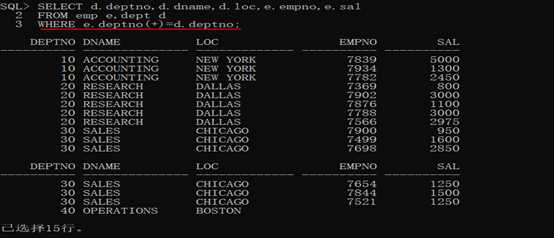
第二步:此时发现三个列(dept列)同时发生着重复,那么就可以进行多字段分组。
代码示例:
1 SELECT d.deptno,d.dname,d.loc,COUNT(e.empno),AVG(e.sal)
2
3 FROM emp e,dept d
4
5 WHERE e.deptno(+)=d.deptno
6
7 GROUP BY d.deptno,d.dname,d.loc;
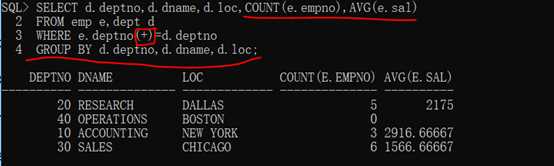
HAVING子句
现在要求查询出每个职位的名称,职位的平均工资,但是要求显示的职位的平均工资高于2000.
即:按照职位先进行分组,同时统计出每个职位的平均工资。随后要求只显示那些平均工资高于2000的职位信息,那么既然现在要针对于显示的数据进行筛选,自然就会首先想到WHERE子句,于是有了如下的代码:
范例:代码示例:
|
错误代码: |
|
SELECT job,AVG(sal) FROM emp WHERE AVG(sal) GROUP BY job; |
|
错误提示: 第 3 行出现错误: ORA-00934: 此处不允许使用分组函数 |
此时直接告诉用户,WHERE子句中不允许出现统计函数(分组函数)。因为GROUP BY子句在WHERE子句之后执行的。那么此时执行WHERE子句时还没有进行分组,那么就自然无法进行统计。此时我们就可以使用HAVING子句来完成。
SQL语法结构:
【⑤选出所需要的数据列】SELECT [DISTINCT] * 分组列[别名],分组列[别名],分组列[别名]······
【①确定数据来源(行和列的集合)】FROM 表名称 [别名],表名称 [别名],······
【②筛选数据行】[WHERE 限定条件] 此时的条件可以是多个语法结构。
【③针对于筛选的行分组】[GROUP BY 分组字段,分组字段,······]
【③针对于筛选的行分组】[HAVING 分组过滤]
【⑥数据排序】[ORDER BY 排序字段 [ASC|DESC] 可以设置多个]
范例:使用HAVING子句
代码示例:
1 SELECT job,AVG(sal)
2
3 FROM emp
4
5 GROUP BY job
6
7 HAVING AVG(sal)>2000;

HAVING实在GROUP BY分组之后才进行的筛选,在HAVING里面可以直接使用统计函数。
说明:关于WHERE与HAVING的区别?
分组案例:
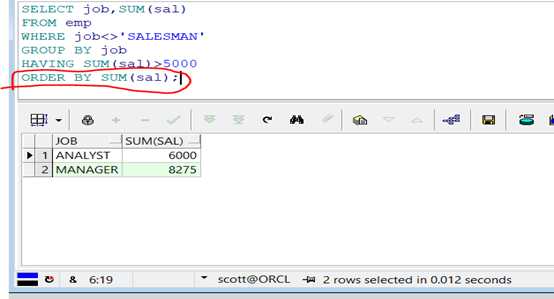
范例:显示所有销售人员的工作名称以及从事同一个工作的雇员的月工资的总和,并且要求满足从事同一工作的月工资的合计大于5000,显示的结果按照月工资合计的升序排列。
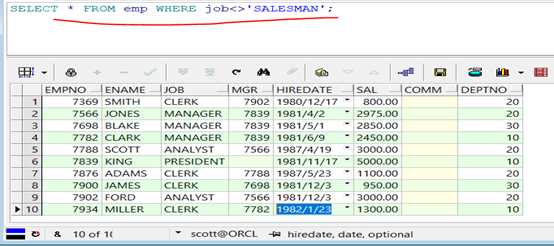
第一步:查询所有非销售人员的信息,WHERE子句即可实现限定查询。
代码示例:
1 SELECT * FROM emp WHERE job<>‘SALESMAN‘;
查询结果:
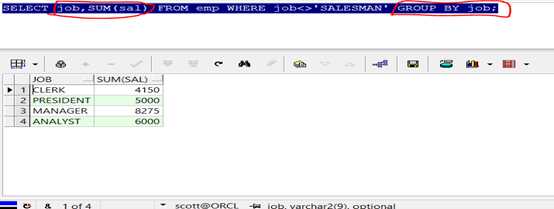
第二步:按照职位进行分组,而后求出月工资的总支出。
代码示例:
1 SELECT job,SUM(sal)
2 FROM emp
3 WHERE job<>‘SALESMAN‘
4 GROUP BY job;
查询结果:
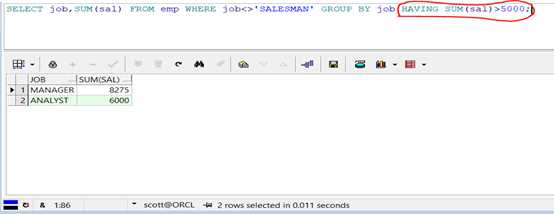
第三步:分组后的数据进行再次的筛选,使用HAVING子句。
代码示例:
1 SELECT job,SUM(sal)
2 FROM emp
3 WHERE job<>‘SALESMAN‘
4 GROUP BY job
5 HAVING SUM(sal)>5000;
查询结果:
第四步:按照月工资的合计升序排列。使用ORDER BY子句。
代码示例:
1 SELECT job,SUM(sal)
2
3 FROM emp
4
5 WHERE job<>‘SALESMAN‘
6
7 GROUP BY job
8
9 HAVING SUM(sal)>5000
10
11 ORDER BY SUM(sal);
查询结果:
范例:统计所有领取佣金和布领取佣金的人数、平均工资。
代码示例:
1 SELECT comm,AVG(sal)
2
3 FROM emp
4
5 GROUP BY comm;
查询结果:
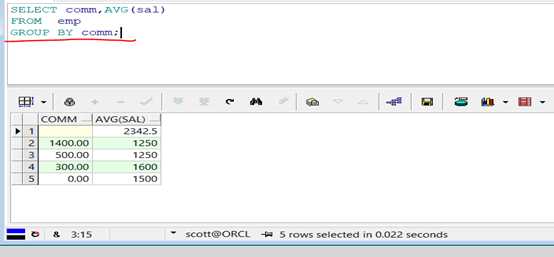
使用GROUP BY子句会把每一个种子值当作一个分组,所以此时不可能直接使用GROUP BY。
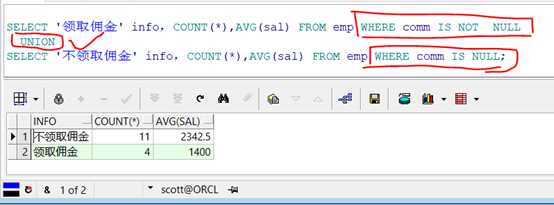
查询出所有领取佣金的雇员的人数、平均工资。————直接使用WHERE子句。不需要使用GROUP BY子句
代码示例:
1 SELECT ‘领取佣金‘ info,COUNT(*),AVG(sal) 2 FROM emp 3 WHERE comm IS NOT NULL;
查询结果:

查询出所有不领取佣金的雇员的人数、平均工资。————直接使用WHERE子句。不需要使用GROUP BY子句
代码示例:
1 SELECT ‘不领取佣金‘ info,COUNT(*),AVG(sal)
2 FROM emp
3 WHERE comm IS NULL;
查询结果:
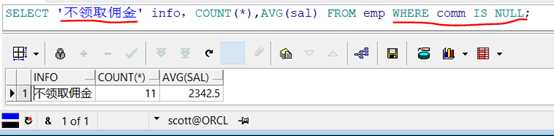
既然此时两个查询结果返回的结构完全相同,那么我们就直接连接即可。
标签:acl 复数 str 最大值 重复记录 最大 平均值 分享图片 代码示例
原文地址:https://www.cnblogs.com/launolife/p/9383104.html