标签:sys 可变参 pre use 资源 tab let writer mvc
Lucene是使用Query对象执行查询的, 由Query对象生成查询的语法. 如bookName:java, 表示搜索bookName域中包含java的文档数据.
| 子类对象 | 说明 |
|---|---|
| TermQuery | 不使用分析器, 对关键词做精确匹配搜索. 如:订单编号、身份证号 |
| NumericRangeQuery | 数字范围查询, 比如: 图书价格大于80, 小于100 |
| BooleanQuery | 布尔查询, 实现组合条件查询. 组合关系有: 1. MUST与MUST: 表示“与”, 即“交集” 2. MUST与MUST NOT: 包含前者, 排除后者 3. MUST NOT与MUST NOT: 没有意义 4. SHOULD与MUST: 表示MUST, SHOULD失去意义 5. SHOULD与MUST NOT: 等于MUST与MUST NOT 6. SHOULD与SHOULD表示“或”, 即“并集” |
/**
* 搜索索引(封装搜索方法)
*/
private void seracher(Query query) throws Exception {
// 打印查询语法
System.out.println("查询语法: " + query);
// 1.创建索引库目录位置对象(Directory), 指定索引库的位置
Directory directory = FSDirectory.open(new File("/Users/healchow/Documents/index"));
// 2.创建索引读取对象(IndexReader), 用于读取索引
IndexReader reader = DirectoryReader.open(directory);
// 3.创建索引搜索对象(IndexSearcher), 用于执行搜索
IndexSearcher searcher = new IndexSearcher(reader);
// 4. 使用IndexSearcher对象执行搜索, 返回搜索结果集TopDocs
// 参数一:使用的查询对象, 参数二:指定要返回的搜索结果排序后的前n个
TopDocs topDocs = searcher.search(query, 10);
// 5. 处理结果集
// 5.1 打印实际查询到的结果数量
System.out.println("实际查询到的结果数量: " + topDocs.totalHits);
// 5.2 获取搜索的结果数组
// ScoreDoc中有文档的id及其评分
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
System.out.println("= = = = = = = = = = = = = = = = = = =");
// 获取文档的id和评分
int docId = scoreDoc.doc;
float score = scoreDoc.score;
System.out.println("文档id= " + docId + " , 评分= " + score);
// 根据文档Id, 查询文档数据 -- 相当于关系数据库中根据主键Id查询数据
Document doc = searcher.doc(docId);
System.out.println("图书Id: " + doc.get("bookId"));
System.out.println("图书名称: " + doc.get("bookName"));
System.out.println("图书价格: " + doc.get("bookPrice"));
System.out.println("图书图片: " + doc.get("bookPic"));
System.out.println("图书描述: " + doc.get("bookDesc"));
}
// 6. 关闭资源
reader.close();
}/**
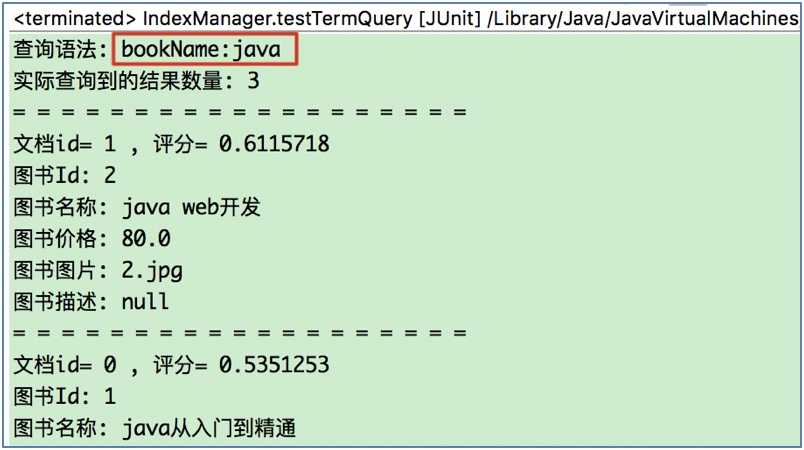
* 测试使用TermQuery: 需求: 查询图书名称中包含java的图书
*/
@Test
public void testTermQuery() throws Exception {
//1. 创建TermQuery对象
TermQuery termQuery = new TermQuery(new Term("bookName", "java"));
// 2.执行搜索
this.seracher(termQuery);
}
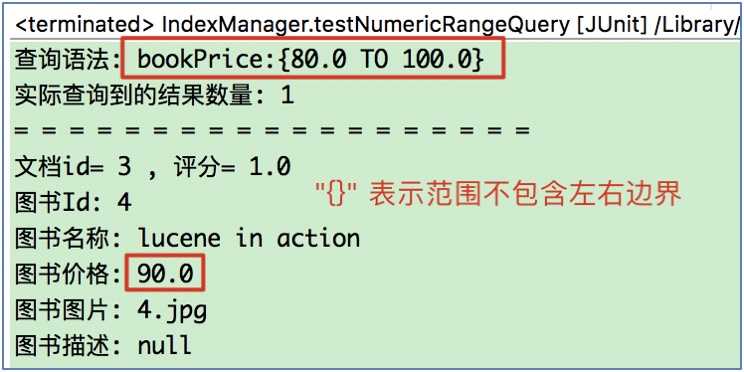
/**
* 测试使用NumericRangeQuery: 需求: 查询图书价格在80-100之间的图书
*/
@Test
public void testNumericRangeQuery() throws Exception{
// 1.创建NumericRangeQuery对象, 参数说明:
// field: 搜索的域; min: 范围最小值; max: 范围最大值
// minInclusive: 是否包含最小值(左边界); maxInclusive: 是否包含最大值(右边界)
NumericRangeQuery numQuery = NumericRangeQuery.newFloatRange("bookPrice", 80f, 100f, false, false);
// 2.执行搜索
this.seracher(numQuery);
}
// 测试包含80和100
NumericRangeQuery numQuery = NumericRangeQuery.newFloatRange("bookPrice", 80f, 100f, true, true);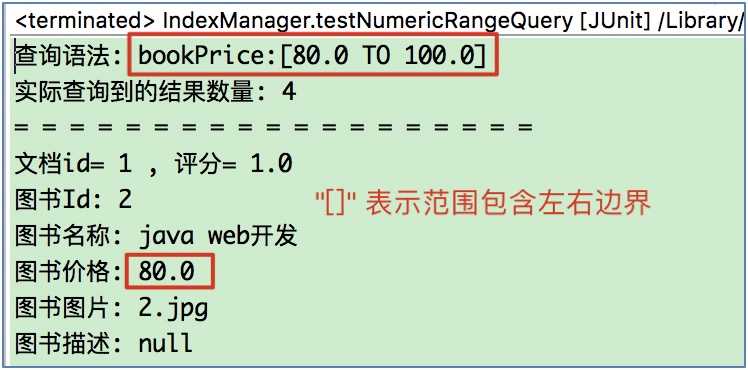
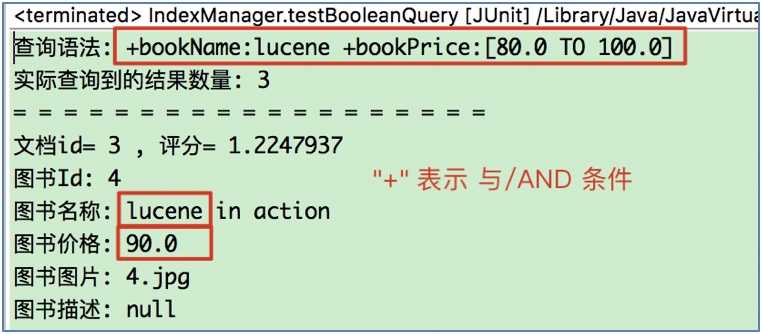
/**
* 测试使用BooleanQuery: 需求: 查询图书名称中包含Lucene, 且价格在80-100之间的图书
*/
@Test
public void testBooleanQuery() throws Exception {
// 1.创建查询条件
// 1.1.创建查询条件一
TermQuery query1 = new TermQuery(new Term("bookName", "lucene"));
// 1.2.创建查询条件二
NumericRangeQuery query2 = NumericRangeQuery.newFloatRange("bookPrice", 80f, 100f, true, true);
// 2.创建组合查询条件
BooleanQuery bq = new BooleanQuery();
// add方法: 添加组合的查询条件
// query参数: 查询条件对象
// occur参数: 组合条件
bq.add(query1, Occur.MUST);
bq.add(query2, Occur.MUST);
// 3.执行搜索
this.seracher(bq);
}查询语法中, "+"表示并且条件, "-"表示不包含后面的条件:
说明: 使用QueryParser对象解析查询表达式, 实例化Query对象.
| 条件表示符 | 符号说明 | 符号表示 |
|---|---|---|
| Occur.MUST | 搜索条件必须满足, 相当于AND | + |
| Occur.SHOULD | 搜索条件可选, 相当于OR | 空格 |
| Occur.MUST_NOT | 搜索条件不能满足, 相当于NOT非 | - |
需求: 查询图书名称中包含java, 并且图书名称中包含"Lucene"的图书.
/**
* 测试使用QueryParser: 需求: 查询图书名称中包含Lucene, 且包含java的图书
*/
@Test
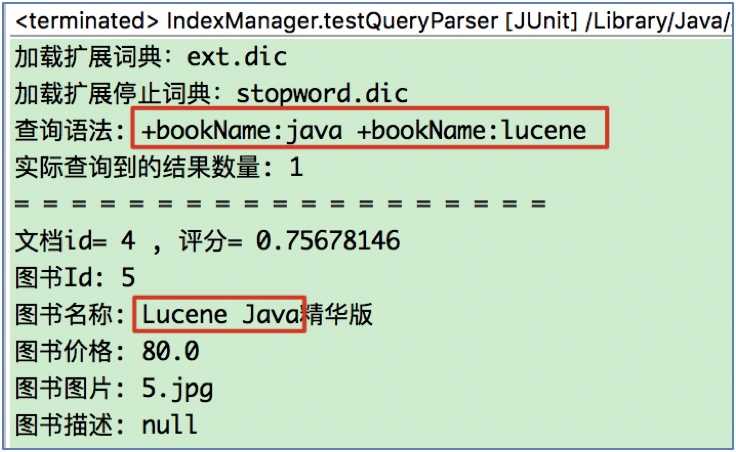
public void testQueryParser() throws Exception {
// 1.创建查询对象
// 1.1.创建分析器对象
Analyzer analyzer = new IKAnalyzer();
// 1.2.创建查询解析器对象
QueryParser qp = new QueryParser("bookName", analyzer);
// 1.3.使用QueryParser解析查询表达式
Query query = qp.parse("bookName:java AND bookName:lucene");
// 2.执行搜索
this.seracher(query);
}
注意: 使用QueryParser, 表达式中的组合关键字AND/OR/NOT必须要大写. 设置了默认搜索域后, 若查询的域没有改变, 则可不写.
数据保存在关系型数据库中, 需要实现增、删、改、查操作; 索引保存在索引库中, 也需要实现增、删、改、查操作.
参考 Lucene-入门程序及Java API的简单使用 中的内容:
/**
* 根据Term删除索引
*/
@Test
public void deleteIndexByTerm() throws IOException {
// 1.创建分析器对象(Analyzer), 用于分词
Analyzer analyzer = new IKAnalyzer();
// 2.创建索引配置对象(IndexWriterConfig), 用于配置Lucene
IndexWriterConfig iwc = new IndexWriterConfig(Version.LUCENE_4_10_4, analyzer);
// 3.创建索引库目录对象(Directory), 用于指定索引库的位置
Directory directory = FSDirectory.open(new File("/Users/healchow/Documents/index"));
// 4.创建索引写入对象(IndexWriter), 用于操作索引
IndexWriter writer = new IndexWriter(directory, iwc);
// 5.创建删除条件对象(Term)
// 删除图书名称域中, 包含"java"的索引
// delete from table where name="java"
// 参数一: 删除的域的名称, 参数二: 删除的条件值
Term term = new Term("bookName", "java");
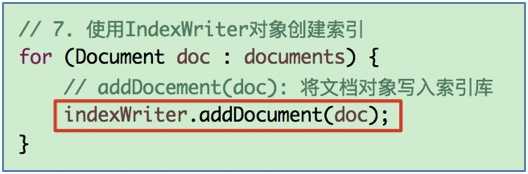
// 6.使用IndexWriter对象, 执行删除
// 可变参数, 能传多个term
writer.deleteDocuments(term);
// 7.释放资源
writer.close();
}根据Term执行删除操作(indexWriter.deleteDocuments(term))时, 要求对应的Field不能分词且只能是一个词, 且这个Field必须索引过, Lucene将先去搜索, 然后将所有满足条件的记录删除(伪删除, 做了".del"标记) -- 最好定义一个唯一标识来做删除操作.

是否删除索引, 需要分情况讨论: 我们知道, Lucene是以段(segment)来组织索引内容的, 通过Term执行删除操作(indexWriter.deleteDocuments(term))时, 若索引段中仍包含符合条件的文档对象的其他分词的索引, 就会保留整个索引数据(若采取更新操作, 则会降低性能), 如果没有, 则也将删除索引数据:
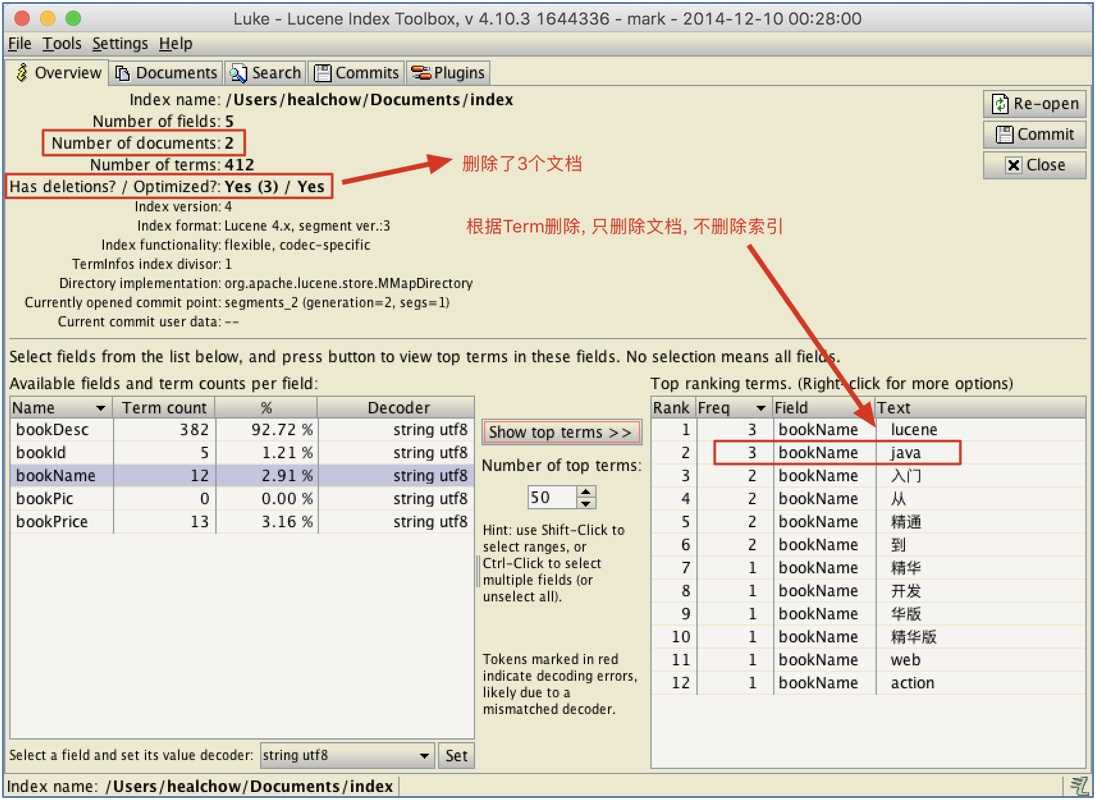
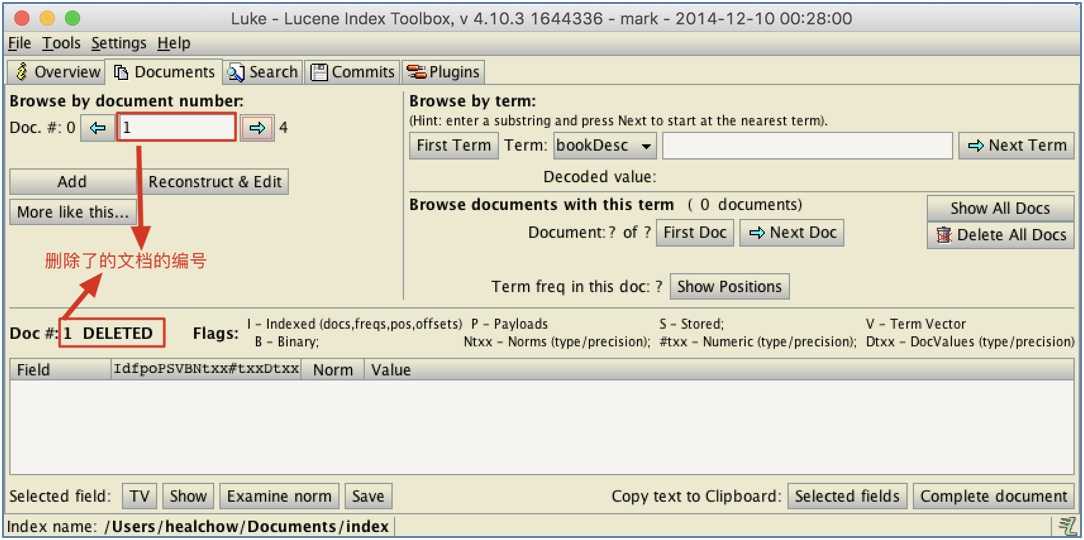
查看删除了的文档的编号:
/**
* 删除全部索引
*/
@Test
public void deleteAllIndex() throws IOException {
// 1.创建分析器对象(Analyzer), 用于分词
Analyzer analyzer = new IKAnalyzer();
// 2.创建索引配置对象(IndexWriterConfig), 用于配置Lucene
IndexWriterConfig iwc = new IndexWriterConfig(Version.LUCENE_4_10_4, analyzer);
// 3.创建索引库目录对象(Directory), 用于指定索引库的位置
Directory directory = FSDirectory.open(new File("/Users/healchow/Documents/index"));
// 4.创建索引写入对象(IndexWriter), 用于操作索引
IndexWriter writer = new IndexWriter(directory, iwc);
// 5.使用IndexWriter对象, 执行删除
writer.deleteAll();
// 6.释放资源
writer.close();
}删除后的索引结果:
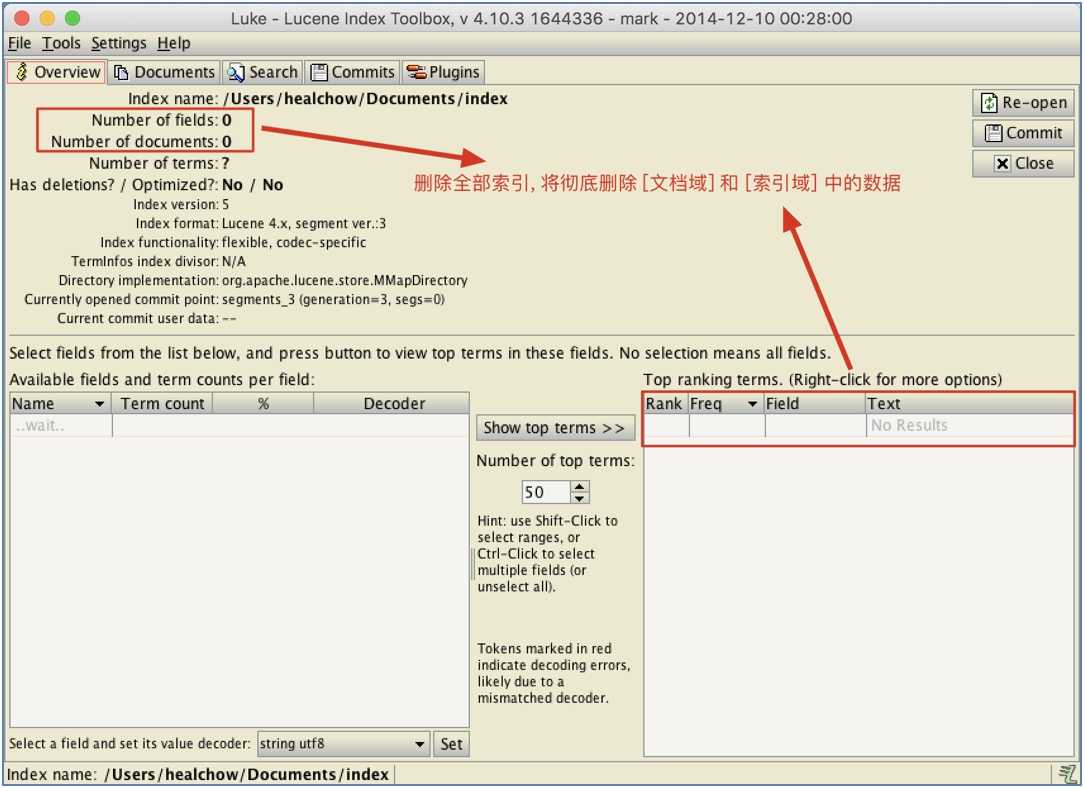
删除全部索引, 将文档域的数据, 索引域的数据都删除.
类似于关系型数据库的Truncate删除: 完全删除数据, 包括存储结构, 因而更快速.
Lucene是根据Term对象更新索引: 先根据Term执行查询, 查询到则执行更新, 查询不到则执行添加索引.
/**
* 更新索引
*/
@Test
public void updateIndexByTerm() throws IOException{
// 1.创建分析器对象(Analyzer), 用于分词
Analyzer analyzer = new IKAnalyzer();
// 2.创建索引配置对象(IndexWriterConfig), 用于配置Lucene
IndexWriterConfig iwc = new IndexWriterConfig(Version.LUCENE_4_10_4, analyzer);
// 3.创建索引库目录对象(Directory), 用于指定索引库的位置
Directory directory = FSDirectory.open(new File("/Users/healchow/Documents/index"));
// 4.创建索引写入对象(IndexWriter), 用于操作索引
IndexWriter writer = new IndexWriter(directory, iwc);
// 5.创建文档对象(Document)
Document doc = new Document();
doc.add(new TextField("id", "1234", Store.YES));
// doc.add(new TextField("name", "MyBatis and SpringMVC", Store.YES));
doc.add(new TextField("name", "MyBatis and Struts2", Store.YES));
// 6.创建Term对象
Term term = new Term("name", "SpringMVC");
// 7.使用IndexWriter对象, 执行更新
writer.updateDocument(term, doc);
// 8.释放资源
writer.close();
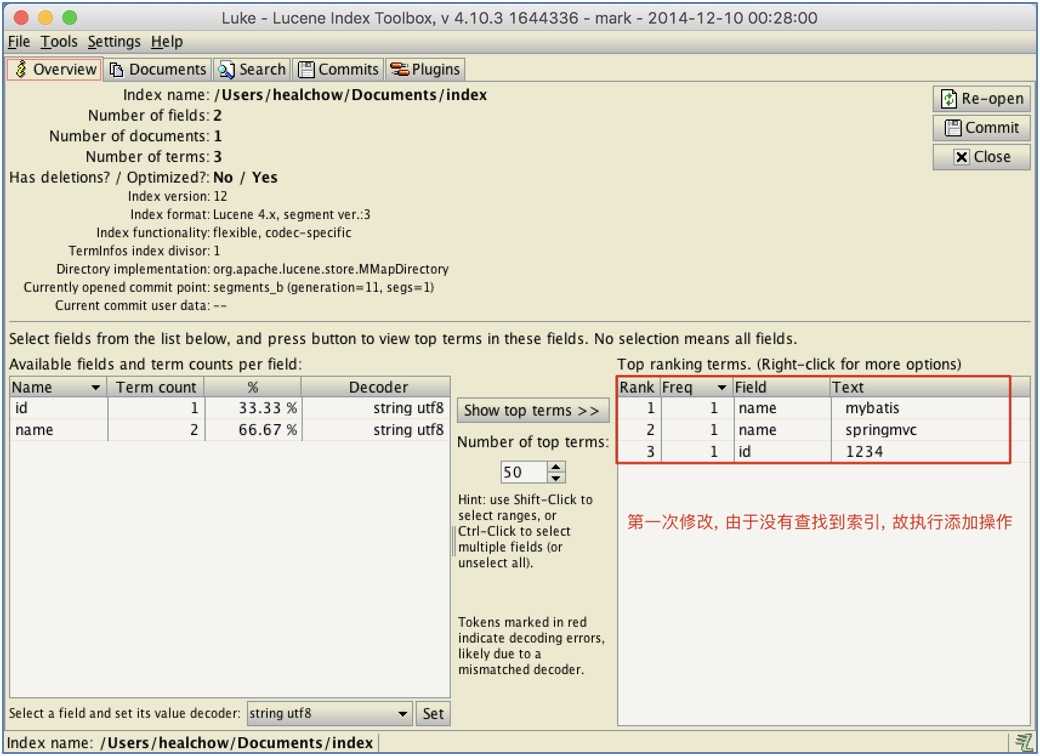
}第一次执行, 由于没有查找到对应的索引, 故执行添加功能, 结果如图(不区分大小写):
第二次执行时, 由于索引库中已有"name"="SpringMVC"的内容, 故执行更新操作: 将整个TextField的内容:"MyBatis and Struts2"添加到索引库中, 并与上次的结果合并, 结果如下图示:
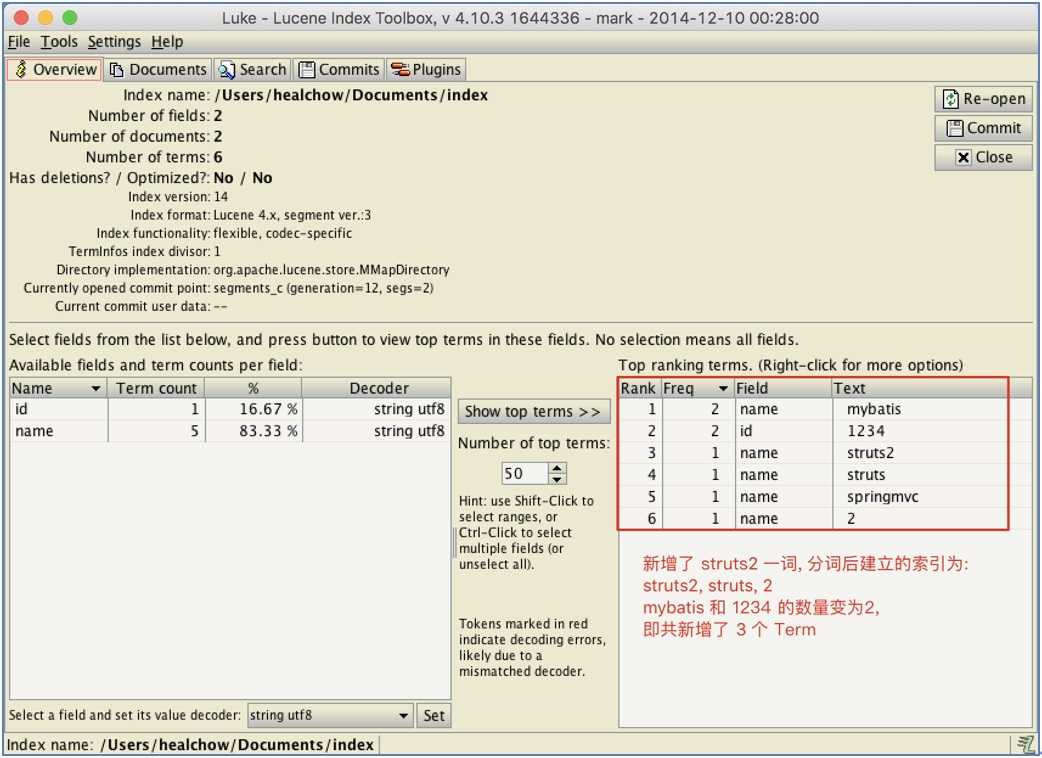
若第二次执行时更改了Term中name域的条件值(索引中没有对应的), 将继续执行添加功能: 将整个TextField中的内容添加到索引中.
版权声明
作者: ma_shoufeng(马瘦风)
出处: 博客园 马瘦风的博客
您的支持是对博主的极大鼓励, 感谢您的阅读.
本文版权归博主所有, 欢迎转载, 但未经博主同意必须保留此段声明, 且在文章页面明显位置给出原文链接, 否则博主保留追究法律责任的权利.
标签:sys 可变参 pre use 资源 tab let writer mvc
原文地址:https://www.cnblogs.com/shoufeng/p/9398964.html