标签:blog http ar strong 数据 sp div 2014 c
目前SQL Server 的索引结构如下:
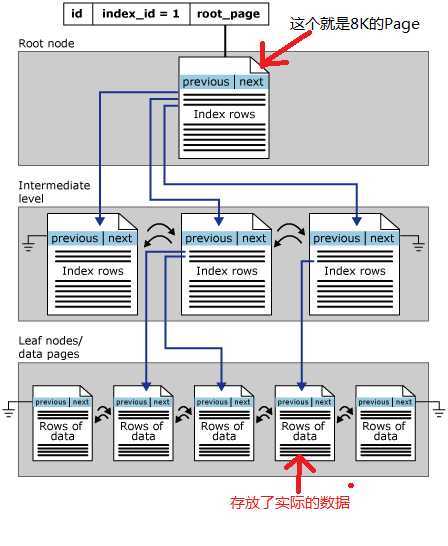
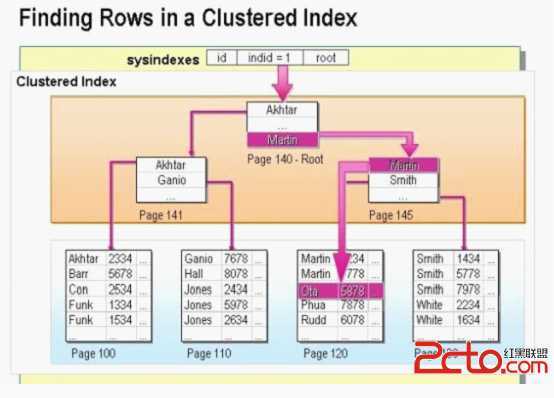
这个是聚集索引的存放形式:
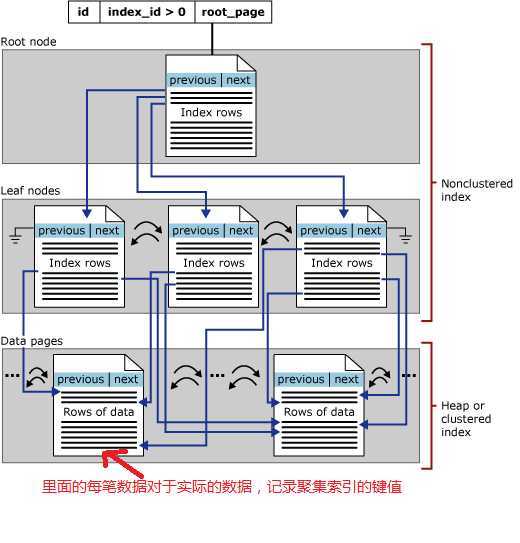
非聚集索引的方式如下:
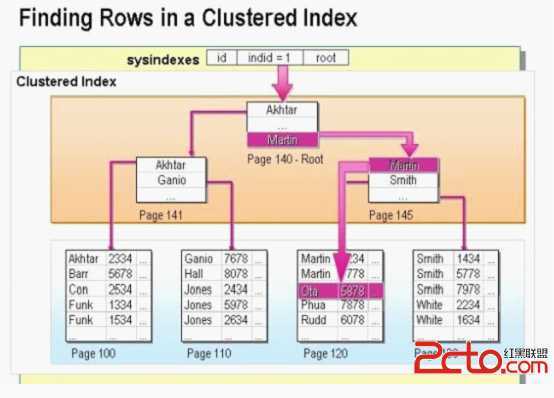
它们是以B+树的数据结构存放的。
相信大家都看过类似的图,但是没有直观的认识,下面举一个实际的例子来说明图的结构。
USE Test --1.创建表,指定主键(会自动创建聚集索引) CREATE TABLE Person ( Id int NOT NULL IDENTITY, Name varchar(10) NOT NULL, Sex varchar(2) NOT NULL, CONSTRAINT PK_Person PRIMARY KEY(Id) ); --2.创建非聚集索引 CREATE INDEX idx_Person_Sex ON Person(Sex);
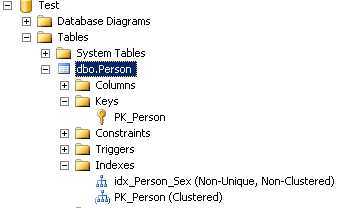
--3.插入1笔数据 Insert Person values(‘P0‘,‘M‘); --4.查看表有哪些页 DBCC ind ( Test, [dbo.Person], -1)
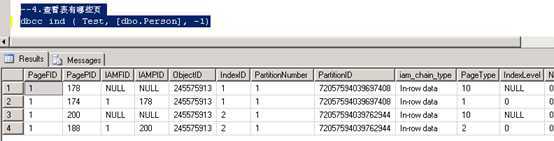
--5. 打开3604监控 DBCC TraceON(3604,-1) --6.查看聚集索引叶子节点页的数据 DBCC PAGE (Test,1,174, 1);

--7.插入1000条M和500条W记录 SET NOCOUNT ON; GO DECLARE @i int; SET @i = 1000; WHILE @i < 2000 BEGIN Insert Person values(‘P‘ + convert(varchar(10),@i),‘M‘); SET @i = @i + 1; END; DECLARE @i int; SET @i = 2000; WHILE @i < 2500 BEGIN Insert Person values(‘P‘ + convert(varchar(10),@i),‘W‘); SET @i = @i + 1; END; GO --8.查看表有哪些页 DBCC ind ( Test, [dbo.Person], -1)
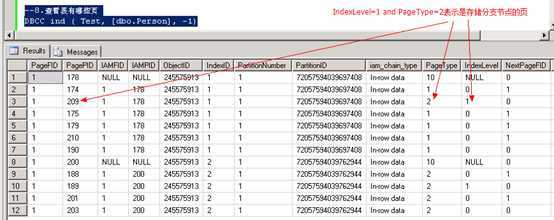
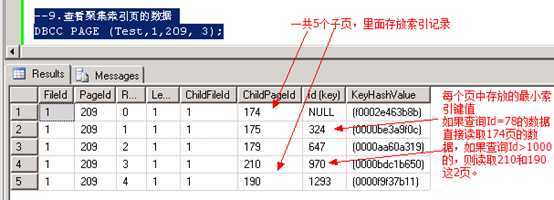
--9.查看聚集索引页的数据 DBCC PAGE (Test,1,209, 3);
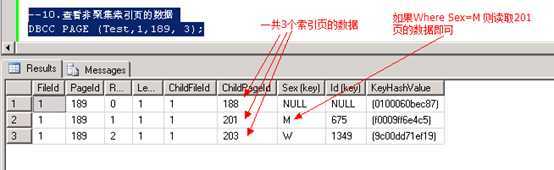
--10.查看非聚集索引页的数据 DBCC PAGE (Test,1,189, 3);
Index 的总结:
一个Index 可以有多个Page
Index 是以B+树结构存放的,其中分支节点的信息是存在一个Page中,而叶子节点存放在其他Page 。
标签:blog http ar strong 数据 sp div 2014 c
原文地址:http://www.cnblogs.com/m15921285681/p/4005545.html