标签:har 导致 only dbquery stat kill -9 tables append eve
01.数据的定义:文字、图像、地理位置信息(坐标、经纬度)等
02.数据库管理系统的定义:建立、存取和管理数据,保证数据安全和完整性的软件
03.常见的数据库管理系统:
关系型:MySQL、Oracle、SQL Server、Db2等
非关系型:MongoDB、Redis、HBase等
数据库管理系统使用情况排名https://db-engines.com/en/ranking
NoSQL=Not Only SQL,支持类似SQL的功能, 与Relational Database相辅相成
其适用于性能较高,不使用SQL意味着没有结构化的存储要求(SQL为结构化的查询语句),没有约束之后架构更加灵活
列存储:Hbase
键值(Key-Value)存储:Redis
图像存储:Neo4J
文档存储:MongoDB
高可扩展性、分布式计算、没有复杂的关系、低成本、架构灵活、半结构化数据
即最像关系型数据库的NoSQL
MongoDB与RDBMS的最大区别:
没有固定的行列组织数据结构,即无需将不同类的数据放入多张表中建立对应关系并分别存储其数据,而是直接放入一份文档进行存储
01. JSON
MongoDB使用JSON(JavaScript ObjectNotation)文档存储记录
JSON数据库语句可以容易被解析
Web应用大量使用
NAME-VALUE配对
02. BSON
二进制的JSON,JSON文档的二进制编码存储格式
BSON有JSON没有的Date和BinData
MongoDB中document以BSON形式存放
数据格式灵活-文档里嵌入文档

1 {
2 _id: ObjectID("1"),
3 username: “Silence”,
4 regDate: “10-10-2015”,
5 scores: {
6 math: "80",
7 english: "200"
8 }
9 }
MongoDB是开源产品,On GitHub,Licensed under the AGPL,起源&赞助by MongoDB公司,提供商业版licenses许可
01.功能
JSON文档模型、动态的数据模式、二级索引强大(特有)、查询功能、自动分片、水平扩展、自动复制、高可用、文本搜索、企业级安全、聚合框架MapReduce、大文件存储GridFS、地理位置索引
支持多种存储引擎:
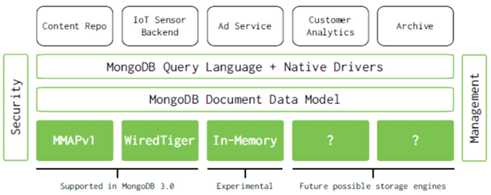
02.存储引擎比较
|
|
MySQL InnoDB |
MongoDB MAPI |
MongoDB WiredTiger |
|
事务 |
YES |
NO |
NO |
|
锁粒度 |
ROW-level行级锁 |
Collection-level |
Document-level |
|
Geospatial |
YES |
YES |
YES |
|
MVCC |
YES |
NO |
NO |
|
Replication |
YES |
YES |
YES |
|
外键 |
YES |
NO |
NO |
|
数据库集群 |
NO |
YES |
YES |
|
B-TREE索引 |
YES |
YES |
YES |
|
全文检索 |
YES |
YES |
YES |
|
数据压缩 |
YES |
NO |
YES |
|
存储限制 |
64TB |
NO |
NO |
|
表分区 |
YES |
YES(分片) |
YES(分片) |
03.数据库功能和性能分布图

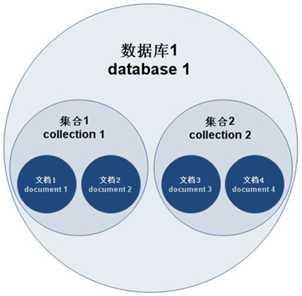
文档(document)、集合(collection)、数据库(database)
|
MongoDB |
VS |
RDBMS |
|
集合Collection |
-> |
表Table |
|
文档Document |
-> |
行Row |
|
数据库Database |
|
数据库Database |
|
索引值Index |
-> |
索引值Index |
|
嵌入式文件Embedded Document |
-> |
合并Join |
|
引用Reference |
-> |
外键Foreign Key |
|
分片Shard |
-> |
分区Partition |
1)网站数据:MongoDB 非常适合实时的插入,更新与查询,并具备网站实时数据存储所需的复制及高度伸缩性
2)缓存:由于性能很高,MongoDB 也适合作为信息基础设施的缓存层。在系统重启之后,由 MongoDB 搭建的持久化缓存层可以避免下层的数据源过载
3)大尺寸,低价值的数据:使用传统的关系型数据库存储一些数据时可能会比较昂贵,在此之前,很多时候程序员往往会选择传统的文件进行存储
4)高伸缩性的场景:MongoDB 非常适合由数十或数百台服务器组成的数据库。MongoDB的路线图中已经包含对 MapReduce 引擎的内置支持
5)用于对象及 JSON 数据的存储:MongoDB 的 BSON 数据格式非常适合文档化格式的存储及查询
1 我的数据量是有亿万级或者需要不断扩容
2 需要2000-3000以上的读写每秒
3 新应用,需求会变,数据模型无法确定
4 我需要整合多个外部数据源
5 我的系统需要99.999%高可用
6 我的系统需要大量的地理位置查询
7 我的系统需要提供最小的latency
8 我要管理的主要数据对象 <10
说明:以上条件满足一个可以考虑MongoDB,满足两个选择MongoDB不会后悔
官方下载地址www.mongodb.com
安装文档地址
docs.mongodb.com
mongoing.com
软件所支持的平台(X86_64)
在3.4版更改:MongoDB不再支持32位的x86平台
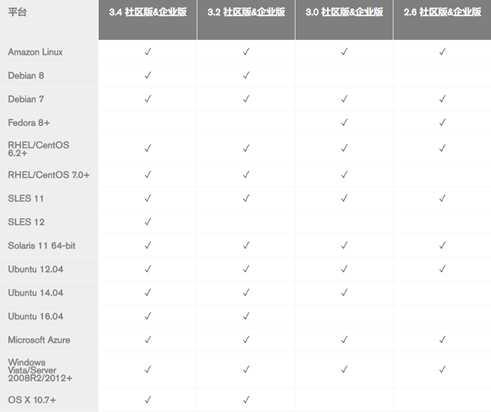
注意:切记在选择mongodb版本时要确认支持/兼容哪些操作系统及版本信息,如使用3.2版本需安装在CentOS6.2级以上操作系统
01.准备Redhat或Centos6.2以上系统
02.系统开发包完整
03.关闭iptables及Selinux
04.配置IP地址和hosts解析
05.关闭hugepage大页内存
06.创建所需用户mongod(非root用户)
07.创建所需目录,并授权
1 [root@mongodb ~]# cat /etc/redhat-release
2 CentOS release 6.9 (Final)
3
4 [root@mongodb ~]# uname -r
5 2.6.32-696.el6.x86_64
6
7 [root@mongodb ~]# uname -m
8 x86_64
1 /etc/init.d/iptables status
2 getenforce
3 ip a
4 echo "10.0.0.51 mongodb" >>/etc/hosts
5
6 /etc/init.d/mysqld stop #若存在mysql程序需提前关闭以防止程序冲突
关闭大页内存机制以提高性能
1 vim /etc/rc.local
2
3 #以root用户身份在最后一行添加如下代码,重启生效
4 if test -f /sys/kernel/mm/transparent_hugepage/enabled; then
5 echo never > /sys/kernel/mm/transparent_hugepage/enabled
6 fi
7 if test -f /sys/kernel/mm/transparent_hugepage/defrag; then
8 echo never > /sys/kernel/mm/transparent_hugepage/defrag
9 fi
系统关闭参照官方文档https://docs.mongodb.com/manual/tutorial/transparent-huge-pages/
01.创建所需用户和组
1 groupadd -g 800 mongod 2 useradd -u 801 -g mongod mongod 3 passwd mongod
02.创建mongodb所需目录结构
1 mkdir -p /application/mongodb/{bin,conf,log,data}
03.上传并解压软件到指定位置
1 cd /application/
2
3 rz#上传mongodb-linux-x86_64-3.2.8.tgz包
4
5 tar -zxvf mongodb-linux-x86_64-3.2.8.tgz
6 cd mongodb-linux-x86_64-3.2.8/bin/
7 cp -a * /application/mongodb/bin
04.设置目录结构权限
1 chown -R mongod:mongod /application/mongodb
05.设置用户环境变量
1 su - mongod
2
3 vim .bash_profile
4 export PATH=/application/mongodb/bin:$PATH
5
6 source .bash_profile
06.启动mongodb(无需初始化)
1 mongod --dbpath=/application/mongodb/data --logpath=/application/mongodb/log/mongodb.log --port=27017 --logappend --fork
说明:在启动mongodb要指定数据、日志路径及端口号(默认也可以)
06.1成功标识
about to fork child process, waiting until server is ready for connections.
forked process: 1294
child process started successfully, parent exiting
|
mongod参数 |
参数说明 |
|
--dbpath |
数据存放路径 |
|
--logpath |
日志文件路径 |
|
--logappend |
日志输出方式->以追加模式进行记录,默认覆盖记录 |
|
--port |
启用端口号 |
|
--fork |
以后台守护进程的方式启动 |
|
--auth |
是否需要验证权限登录(用户名和密码) |
|
--bind_ip |
限制访问的ip |
07.编辑配置文件->以读取配置文件的方式来启动数据库
1 vim /application/mongodb/conf/mongod.conf
2
3 dbpath=/application/mongodb/data
4 logptah=/application/mongodb/log/mongodb.log
5 port=27017
6 logappend=1
7 fork=1
08.指定配置文件启动/关闭mongod
1 mongod -f /application/mongodb/conf/mongod.conf #启动数据库
2 mongod -f /application/mongodb/conf/mongod.conf shutdown #关闭
09.登录mongodb
1 mongo
2
3 ###此时已登陆mongodb系统,以下为提示信息###
4 MongoDB shell version: 3.2.8
5 connecting to: test
6 >
说明:
01.初次登录时默认提示版本号信息及连接数据库test,但是在MongoDB中test数据库默认并不存在
02.对于3.2以上版本默认只有一个admin数据库,且无需提前创建,不存在的库也能够正常use
报错原因:rlimits设置过小,其设置几乎不能满足MongoDB运行所需的最小条件,会导致它运行缓慢甚至出现不可知的错误
解决思路:
01.查看当前的MongoDB进程信息
1 ps -ef | grep mongod
2
3 #结果如下
4 mongod 1982 1 0 11:47 ? 00:00:16 mongod --dbpath=/application/mongodb/data --logpath=/application/mongodb/log/mongodb.log --port=27017 --logappend --fork
5 root 2056 1566 0 12:21 pts/1 00:00:00 grep --color=auto mongod
02.查看mongod进程的系统限制
1 cat /proc/1982/limits
2
3 #结果如下
4 Limit Soft Limit(软限制->最小值) Hard Limit(硬限制->最大值) Units
5 Max processes 1024 64000 processes
6 Max open files 65535 65535 files
解决方法:
①方法一
1 vim /etc/security/limits.d/90-nproc.conf
2 * soft nproc 32000 #此为修改后结果,reboot重启生效
②方法二
1 vim /etc/security/limits.conf
2
3 # End of file
4 mongod soft nofile 64000
5 mongod hard nofile 64000
6 mongod soft nproc 32000
7 mongod hard nproc 32000
查看系统限制
1 ulimit -a
#也可利用ulimit [-ftvnmu]命令在shell命令行中直接进行设置
#但若要系统启动时在所有窗口生效,需将上面的ulimit添加到/etc/profile
1 systemLog:
2 destination: file
3 path: "/application/mongodb/log/mongod.log"
4 logAppend: true
5 storage:
6 journal:
7 enabled: true
8 dbPath: "/application/mongodb/data"
9 processManagement:
10 fork: true
11 net:
12 port: 27017
此时关闭mongodb重新启动即可
1 $ kill -2 PID #原理:-2表示向mongod进程发送SIGINT信号
2 或
3 $ kill -4 PID #原理:-4表示向mognod进程发送SIGTERM信号
1 use admin
2
3 admin> db.adminCommand({shutdown:1})
4 或
5 $ mongod -f mongodb.conf --shutdown
6 killing process with pid: 1621
注意:
01.mongod进程收到SIGINT或SIGTERM信号,会做一些处理
02.切忌使用kill -9
 mongod.conf
mongod.conf获取帮助
1 > help
help帮助信息查看当前db版本
1 > db.version()
2 3.2.8
查看当前使用db
1 > db
2 test
3 或
4 > db.getName()
5 test
查询所有数据库
1 > show dbs
2 local 0.000GB
切库
1 > use test
2 switched to db test
显示当前数据库状态
1 > db.stats()
2 {
3 "db" : "local",
4 "collections" : 1,
5 "objects" : 7,
6 "avgObjSize" : 1466,
7 "dataSize" : 10262,
8 "storageSize" : 36864,
9 "numExtents" : 0,
10 "indexes" : 1,
11 "indexSize" : 36864,
12 "ok" : 1
13 }
查看当前数据库的连接机器地址
1 > db.getMongo()
2 connection to 127.0.0.1
创建数据库
当使用use命令时系统会自动创建一个数据库,如果use之后没有创建任何集合,系统就会删除这个数据库
1 > use banana
2 switched to db banana
删除数据库
如果没有选择任何数据库,会删除默认的test数据库
1 > db.dropDatabase()
2 { "ok" : 1 }
3 > show dbs;
4 local 0.000GB
创建集合
方法1:
1 > use banana;
2 switched to db banana #相当于use banana ,不同的是(从mysql关系型数据库角度解释),在mongodb中banana允许未创建情况下use banana,在创建数据表后,即创建了banana,否则banana不会创建
3 > db.createCollection(‘a‘); #创建集合a,a相当于mysql中的数据表
4 { "ok" : 1 } # 提示创建成功
5 > db.createCollection(‘b‘);
6 { "ok" : 1 }
7 > show collections;
8 a
9 b
方法2:
1 > db.c.insert({username:"mongodb"}) #向c集合插入数据
2 WriteResult({ "nInserted" : 1 }) ->成功写入文档
3
4 > show collections
5 a
6 b
7 c
8 > db.c.find() #显示数据集合中所有数据,当前仅一条
9 { "_id" : ObjectId("5743c9a9bf72d9f7b524713d"), "username" : "mongodb" }
10 > db.log.find().pretty(); # 格式化打印结果
11 {
12 "_id" : ObjectId("5743c9a9bf72d9f7b524713d"),
13 "uid" : 0,
14 "name" : "mongodb",
15 "age" : 6,
16 "date" : ISODate("2018-01-03T08:37:00.214Z")
17 }
18
19 > db.c.drop() #删除c集合
20 true
21 > db.c.find() #c集合置空
批量插入数据
1 > for(i=0;i<10000;i++){ db.log.insert({"uid":i,"name":"mongodb","age":6,"date":new Date()}); } #批量插入10000个数据
2
3 #查询集合中的记录数
4 > db.log.find()
说明:默认每页显示20条记录,当显示不下的的情况下,可以用it迭代命令查询下一页数据
1 #设置每页显示数据的大小:每页显示50条记录
2 > DBQuery.shellBatchSize=50;
3 #查看第1条记录
4 > db.log.findOne()
5 #查询总的记录数
6 > db.log.count()
7 #删除集合中所有记录
8 > db.log.remove({})
9 #集合中数据的原始大小
10 > db.log.dataSize()
11 #集合中索引数据的原始大小
12 > db.log.totalIndexSize()
13 #集合中索引+数据压缩存储之后的大小
14 > db.log.totalSize()
15 #集合中数据压缩存储的大小
16 > db.log.storageSize()
标签:har 导致 only dbquery stat kill -9 tables append eve
原文地址:https://www.cnblogs.com/wuchangsoft/p/9404478.html