标签:XML lag encoding utf-8 imp img validate ret findall
登录网站的时候,经常会遇到传token参数,token关联并不难,难的是找出服务器第一次返回token的值所在的位置,取出来后就可以动态关联了
1.先找到登录首页https://passport.lagou.com/login/login.html,输入账号和密码登录,抓包看详情
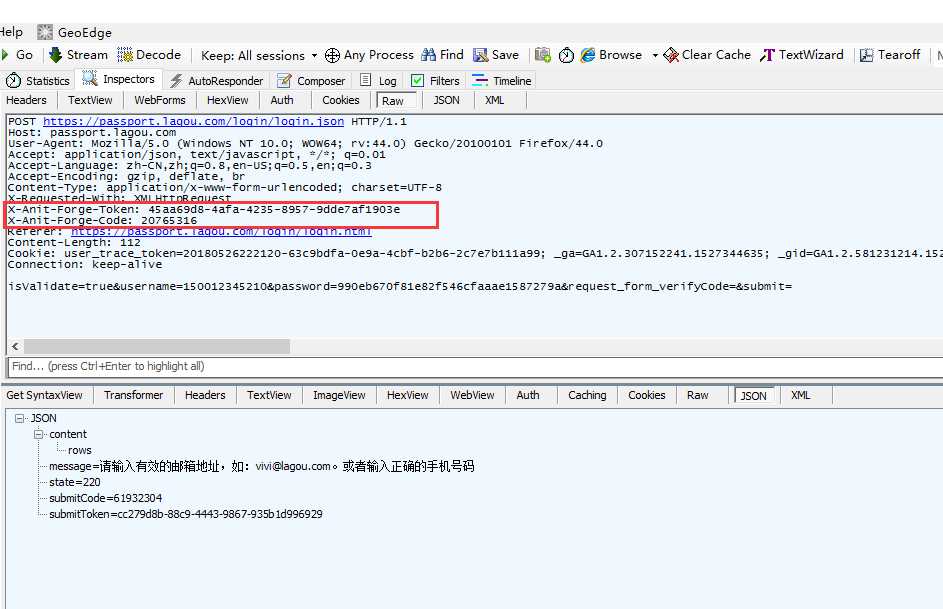
1.打开登录首页https://passport.lagou.com/login/login.html,直接按F5刷新(只做刷新动作,不输入账号和密码),然后从返回的页面找到token生成的位置
看注释内容:
</script>
<!-- 页面样式 --> <!-- 动态token,防御伪造请求,重复提交 -->
<script>
window.X_Anti_Forge_Token = ‘286fd3ae-ef82-4019-89c4-9408947a0e26‘;
window.X_Anti_Forge_Code = ‘74603111‘;
</script>
前端的代码,注释内容暴露了token位置,嘿嘿!
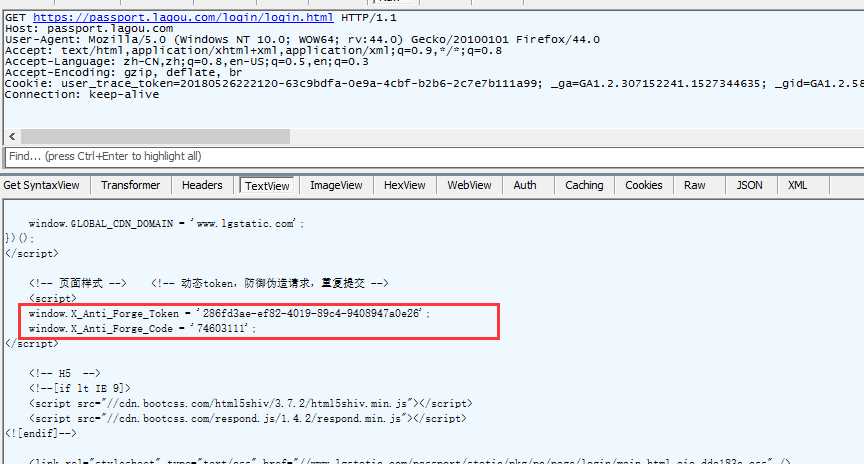
2.接下来从返回的html里面解析出token和code两个参数的值
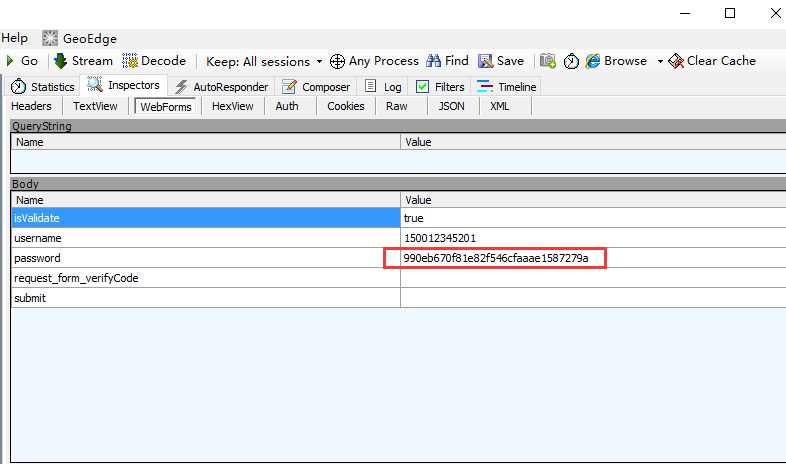
1.登陆的时候这里密码参数虽然加密了,但是是固定的加密方式,所以直接复制抓包的加密后字符串就行了
#coding:utf-8
import requests
from bs4 import BeautifulSoup
import re
def login(s,gtoken,user,psw):
‘‘‘
s=requests.session()
gtoken: getTokenCode返回值
user:账户
psw: 密码
‘‘‘
url2 = "https://passport.lagou.com/login/login.json"
h2={
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"X-Requested-With": "XMLHttpRequest",
"X-Anit-Forge-Token": gtoken[‘X-Anit-Forge-Token‘],
"X-Anit-Forge-Code": gtoken[‘X-Anit-Forge-Code‘],
"Referer": "https://passport.lagou.com/login/login.html"
}
s.headers.update(h2)
body={
"isValidate":"true",
"username":user, #传入user参数
"password":psw, #传入psw参数
"request_form_verifyCode":"",
"submit":""
}
r2 = s.post(url2, data=body,verify=False)
try:
print(r2.text)
return r2.json()
except:
print("登录异常信息为:%s" % r2.text)
return None
def getTokenCode(s):
url=‘https://passport.lagou.com/login/login.html‘
h={
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0"
}
#更新session的
s.headers.update(h)
data=s.get(url,verify=False)
soup=BeautifulSoup(data.content,"html.parser",from_encoding=‘uft-8‘)
tokenCode={}
try:
t=soup.find_all(‘script‘)[1].get_text() #找到我们需要的第2个script标签,并获取文本信息,返回一个字符串
print(t)
tokenCode[‘X-Anit-Forge-Token‘]=re.findall(r"Token = ‘(.+?)‘",t)[0]
tokenCode[‘X-Anit-Forge-Code‘]=re.findall(r"Code = ‘(.+?)‘",t)[0]
return tokenCode
except:
print("获取token和code失败")
tokenCode[‘X-Anit-Forge-Token‘]=""
tokenCode[‘X-Anit-Forge-Code‘]=""
return tokenCode
if __name__==‘__main__‘:
s=requests.session()
token = getTokenCode(s)
login(s,token,"XX","d4fb38a060abe164f6e2e1a71473329d")
python接口自动化-token参数关联登录(登录拉勾网)
标签:XML lag encoding utf-8 imp img validate ret findall
原文地址:https://www.cnblogs.com/xiaohuhu/p/9404513.html