标签:内存 float for is和== let 世界 code gb2312 字节码
一、is 和 ==
1.1== 比较,比较的是==两边数据的值
1 a = ‘alex‘ 2 b = ‘alex‘ 3 print(a == b) # True 4 5 n = 10 6 n1 = 10 7 print(n == n1) #True 8 9 li1 = [1,2,3] 10 li2 = [1,2,3] 11 print(li1 == li2)# True
1.1.1id()或取数据的存储地址
1 a = ‘alex‘ 2 print(id(a)) # 36942544 内存地址 3 4 n = 10 5 print(id(n)) #1408197120 6 7 li = [1,2,3] 8 print(id(li)) #38922760
is 比较,比较的是is两边数据的地址
1 #字符串 2 a = ‘alex‘ 3 b = ‘alex‘ 4 print(a is b) #True 5 #数字 6 n = 10 7 n1 = 10 8 print(n is n1) #True
1.2小数据池
1.2.1数字的小数据池范围 -5 ~ 256 (包括 -5 和256)
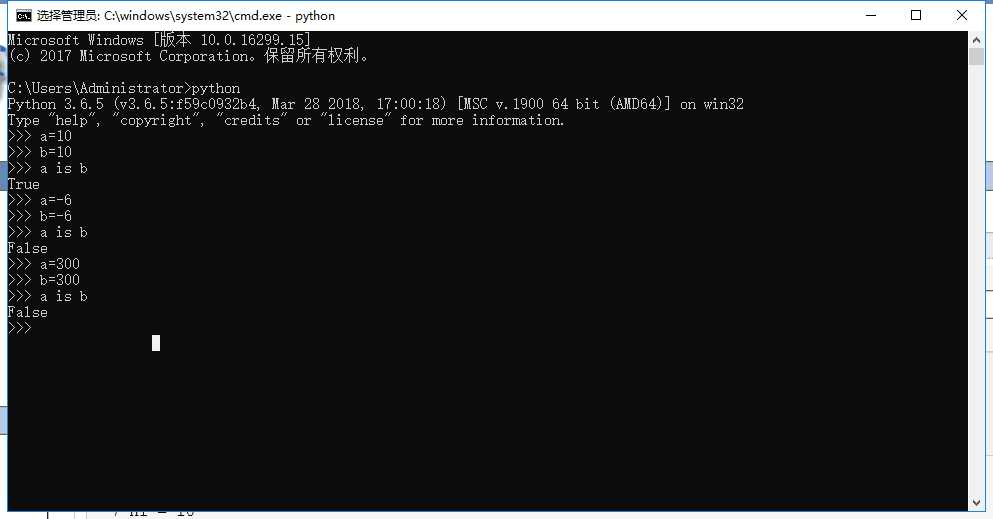
1.2.2字符串的的小数据池范围
单个字符*20,数据存储的地址不同
字符串中如果有特殊字符,数据存储的地址不同
1 a = ‘alex@‘ 2 a1 = ‘alex@‘ 3 print(a is a1) # Fales 4 5 n = 5//2 6 n1 = 2 7 print(n is n1) #True 8 9 a = ‘a‘*21 10 b = ‘a‘*21 11 print(a is b) # False 12 13 a = ‘aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa‘ 14 b = ‘aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa‘ 15 print(a is b)
二、编码和解码
首先了解一下几种常见的编码方式:
ASCII 码:用来表示英文,它使用1个字节表示,其中第一位规定为0,其他7位存储数据,一共可以表示128个字符。
GBK/GB2312/GB18030:表示汉字。GBK/GB2312表示简体中文,GB18030表示繁体中文,用16位表示一个字符。
Unicode编码:包含世界上所有的字符,是一个字符集用,32位表示一个字符。
UTF-8:是Unicode字符的实现方式之一,它使用1-4个字符表示一个符号,根据不同的符号而变化字节长度。
英文 8位
欧洲文字 16位
中文 24位
2.1编码
encode(编码方式) 括号内是指定要编码成什么样的编码类型,获得编码后对应的字节
1 s = ‘alex‘ 2 s1 = ‘饿了么‘ 3 print(s.encode(‘utf-8‘)) # b‘alex‘ 4 print(s1.encode(‘utf-8‘)) #b‘\xe9\xa5\xbf\xe4\xba\x86\xe4\xb9\x88‘
decode(编码方式)将编码后的字节码解码成相对应的明文
1 s = ‘alex‘ 2 s1 = ‘饿了么‘ 3 print(s.encode(‘utf-8‘)) # b‘alex‘ 4 print(s1.encode(‘utf-8‘)) #b‘\xe9\xa5\xbf\xe4\xba\x86\xe4\xb9\x88‘ 5 6 s2 = s1.encode(‘utf-8‘) #b‘\xe9\xa5\xbf\xe4\xba\x86\xe4\xb9\x88‘ 7 s3 = s2.decode(‘utf-8‘) #饿了么
标签:内存 float for is和== let 世界 code gb2312 字节码
原文地址:https://www.cnblogs.com/baijinshuo/p/9409273.html