标签:pat author imp code str cti ima findall 分享
一、爬取流程
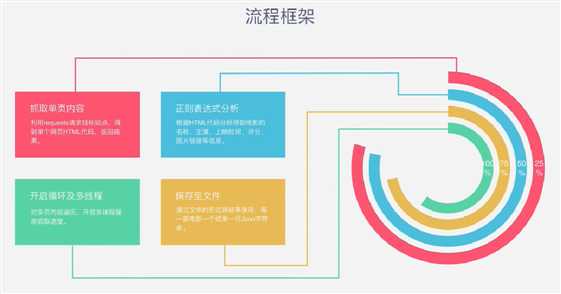
二、代码演示
#-*- coding: UTF-8 -*-
#_author:AlexCthon
#mail:alexcthon@163.com
#date:2018/8/3
import requests
from multiprocessing import Pool # 进程池,用来实现秒抓
from requests.exceptions import RequestException
import re
import json
def get_one_page(url):
try:
response = requests.get(url)
#print(response.text)
if(response.status_code == 200):
return response.text
return None
except RequestException:
return None
def parse_one_page(html):
pattern = re.compile(‘<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>‘,re.S)
items = re.findall(pattern,html)
for item in items:
yield{
‘index‘:item[0],
‘image‘:item[1],
‘title‘:item[2],
‘actor‘:item[3].strip()[3:],
‘time‘:item[4].strip()[5:],
‘score‘:item[5]+item[6]
}
def write_to_file(content):
with open(‘result.txt‘,‘a‘,encoding=‘utf-8‘)as f:
f.write(json.dumps(content,ensure_ascii=False) + ‘\n‘)
f.close()
def main(offset):
url = ‘http://maoyan.com/board/4?offset=‘+str(offset)
html = get_n=get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_file(item)
if __name__ == ‘__main__‘:
pool = Pool()
pool.map(main,[i*10 for i in range(10)])
python爬虫知识点总结(九)Requests+正则表达式爬取猫眼电影
标签:pat author imp code str cti ima findall 分享
原文地址:https://www.cnblogs.com/cthon/p/9416227.html