标签:找到你 play tin opened 基于 实现 class 缺点 传参
一. 简单工厂
简单工厂模式(Simple Factory Pattern):是通过专门定义一个类来负责创建其他类的实例,被创建的实例通常都具有共同的父类.
简单工厂的用处不大,主要就是一个if...else语句
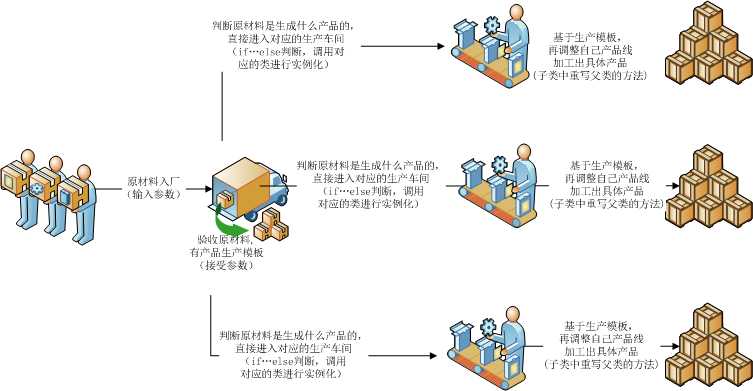
结合一个具体的例子,把上面的图再对应一下
# 1. 定义一个工厂,对应图中的接受参数 class BigCat(object): # 接受参数(接受原材料) def __init__(self, money): self.money = money # 工厂基本的生产模板 def pay(self): print("收到大猫金融支付金额{0}".format(self.money)) # 2. 定义不同的产品生产线 class WeChat(object): def __init__(self, money): self.money = money def pay(self): print("收到微信支付金额{0}".format(self.money)) class ZhiFuBao(object): def __init__(self, money): self.money = money def pay(self): print("收到支付宝支付金额{0}".format(self.money)) # 3. 输入参数(原材料入场) channel = input("请选择支付方式:") money = input("请输入消费金额:") # 简单工厂,if...else判断就行了 # 4. 根据接收的不同原材料,判断是生产什么产品的,然后进行对应产品线的具体生产 # 如果是要微信支付 if channel == ‘WeChat‘: WeChat(money).pay() # Wechat()实例化,生产微信对应的产品 elif channel == ‘ZhiFuBao‘: ZhiFuBao(money).pay() else: BigCat(money).pay()

class Fruit: def __init__(self,name,weight): self.name = name self.weight = weight def product(self): print("这是{},重量是{}吨,用来生产混合果汁的".format(self.name, self.weight)) class Apple(Fruit): def __init__(self,name,weight): super(Apple, self).__init__(name,weight) def product(self): print("这是{},重量是{}吨,用来生产{}罐头的".format(self.name, self.weight, self.name)) class Peer(Fruit): def __init__(self,name,weight): super(Peer, self).__init__(name, weight) def product(self): print("这是{},重量是{}吨,用来生产{}罐头的".format(self.name, self.weight, self.name)) if __name__ == "__main__": name = input("请输入原材料:") weight = input("请输入原材料的重量: ") if name == ‘Apple‘: Apple(name, weight).product() elif name == "Peer": Peer(name, weight).product() else: Fruit(name, weight).product()
二.工厂方法
工厂方法模式(Factory Method Pattern):定义一个用于创建对象的接口,让子类决定实例化哪一个类,工厂方法使一个类的实例化延时到其子类. 工厂方法模式克服了简单工厂模式违背开放-封闭原则的缺点,又保持了封装对象创建过程的优点
场景:雷锋工厂,不关心执行者,只关心执行结果
工厂方法的实现要点:
1. 先要定义每一个产品的具体生产细节(定义每一个产品的类)
2. 再给需要的每一个产品都创建一个生产工厂,提供一个统一的创建方法,然后该创建方法返回具体的产品
3. 这个过程就是把每个产品的生产细节在工厂方法里给包装了一个,外部使用者调用的时候是看不到具体的实现细节的。
工厂方法的使用:
1. 要使用哪个工厂方法,就from...import...,导入具体的工厂方法
2. 然后调用该工厂,获取具体的产品(方法)
3. 有了具体的产品(方法)就可以执行具体的逻辑了
工厂方法传参数会有个小的注意点需要小心,有两种处理方式可以灵活使用:
1. 在定义每个产品类的时候不要在构造方法里接受参数,直接在具体的类方法里接受参数,对应的也使用的时候,也只在调用具体的方法的时候传参
2. 在每个产品类的构造方法里传参,
工厂方法与简单工厂的比较:
1. 不需要給使用者暴露具体的产品的生产过程细节,能封装很多细节,只给使用者提供了一个接口,更解耦;而简单工厂则都暴露给了使用者
2. 如果有新增,简单工厂就需要添加一个if;而工厂方法虽然也需要添加,但是使用者需要使用的时候只需要import对应的工厂方法就可以了,不用的话就无所谓了
3. 工厂方法最大的优点就是把对象的获取和对象的创建给隔离开了,根本不关心对象是怎么创建的
举例:
有个大猫金融、支付宝、微信三种支付渠道,实现一个工厂方法并使用工厂方法
1. 实现工厂方法,文件名:factorymethodpractice.py
# 1. 先定义不同的支付方式(对应工厂里具体的产品),及每个产品具体的生产细节 class BigCat(): # 关于传参的处理方式一: 有构造函数 def __init__(self,money): self.money = money def pay(self): print("收到大猫金融的支付金额{0}".format(self.money)) class WeChat(): # 关于传参的处理方式二:直接就没有构造函数,只在具体的方法里接受参数 def pay(self, money): print("收到微信支付的金额{0}".format(money)) class ZhiFuBao(): def __init__(self, money): self.money = money def pay(self): print("收到支付宝支付的金额{0}".format(self.money)) # 2. 为每个支付方式(每个产品)定义特定的工厂,每个工厂都有具体的工厂方法函数,负责返回 # 具体的工厂方法函数,其实就是对每个产品具体的生产细节进行了包装,让外部使用者只能用,却不知道具体的生产过程细节 # 3. 对外只提供这些特定的工厂(接口) class BigCatFactory(): # 关于传参的处理方式一: # 因为BigCat()类是需要传参的,return其实就是先调用BigCat()类,将BigCat()执行结果返回,所以也需要传参 # 因此,可以在create的时候就传递参数 def create(self,money): return BigCat(money) class WeChatFactory(): # 关于传参的处理方式二: # WeChat()没有构造函数,初始化的时候不接收参数,所以对外提供的接口不需要传参 # 只有在调用WeChat下面具体的pay()方法时才需要传递参数 def create(self): return WeChat() class ZhiFuBaoFactory(): def create(self, money): return ZhiFuBao(money)
2. 使用工厂方法: usefactorymethod.py
# 1. 先获取工厂 from factorymethodpractice import BigCatFactory # 获取工厂 factory = BigCatFactory() # 2. 调工厂去创建具体的产品 # 关于传参的处理方式一:在调用create的时候就给create传递参数 payment = factory.create(100) # # 3. 有了具体的产品,就可以去执行具体产品里具体的逻辑了 payment.pay() ‘‘‘ ------------------------- ‘‘‘ from factorymethodpractice import WeChatFactory factory = WeChatFactory() payment = factory.create() # 关于传参的处理方式二:只在调用具体方法的时候给需要传参的方法才传递参数 payment.pay(200)
再举个例子说明工厂方法及两种参数不同的处理方式
# 接口文件 fruitfactorypractice.py # 定义Apple产品类,实现具体的生产细节 class Apple(): # 参数处理方式一:有构造方法 def __init__(self,name): self.name = name def appleguantou(self): print("{}罐头生产出来了".format(self.name)) # 定义生产Apple的工厂方法 class AppleFactory(): # create的时候就需要传递参数,因为Apple在实例化的时候就需要用到参数 def create(self, name): return Apple(name) ### ++++++++++++++++++++++++++### # 定义Pear产品类,实现具体的生产细节 class Pear(object): # 参数的处理方式二:没有构造方法 def pearguantou(self,name): print("{}罐头生产出来了".format(name)) # 定义生产Pear的工厂方法 class PearFactory(object): # 参数的处理方式二:create的时候不需要传递参数,只有在调用到需要用参数的方法pearguantou的时候才传递参数 def create(self): return Pear()
# 调用文件,使用工厂方法 文件名:usefactorymethod.py from fruitfactorypractice import AppleFactory factory = AppleFactory() proment = factory.create(‘??‘) proment.appleguantou() from fruitfactorypractice import PearFactory factory = PearFactory() proment = factory.create() proment.pearguantou("雪梨")
三. 抽象工厂
抽象工厂模式(Abstract Factory Pattern):提供一个创建一系列相关或相互依赖对象的接口,而无需指定它们的类
抽象工厂最大的有点是:代码量少了很多,通过反射的方法就可以找出函数,比如在单元测试框架里,抽象方法是大量使用到的。
在抽象工厂就是利用反射机制实现的,反射是非常重要的,会大量使用到
什么是反射?
反射就是通过字符串的形式,导入模块;通过字符串的形式,去模块寻找指定函数,并执行。利用字符串的形式去对象(模块)中操作(查找/获取/删除/添加)成员,一种基于字符串的事件驱动!
上面的概念指出了使用反射需要掌握的知识点:
(1)通过字符串的形式,导入模块——>要用到:__import__()
(2)通过字符串的形式,去模块寻找指定函数并执行 ——> 用要到:getattr()
(3)利用字符串的形式去对象(模块)中操作(查找/获取/删除/添加)成员——>要用到:setattr(),hasattr(),delattr()
下面就来基于反射的概念学习每个知识点:
1. __import__()
__import__()可以实现以字符串的形式动态导入模块的目的
# 通常情况下面,导入模块是通过下面的两种方式实现: # 以上面的代码文件示例 # 1. import fruitfactorypractice # 2. from fruitfactorypractice import AppleFactory 这两种常规方式导入模块,其实内部的逻辑执行的都是__import__("fruitfactorypractice") 的方法,所以也可以直接使用__import__()导入模块
有这样的需求,动态输入一个模块名(当然输入的就是字符串了),可以随时访问到导入模块中的方法或者变量,怎么做呢?
就要用到__import__()方法
# 实现动态输入模块名 module = input("请输入你要导入的模块名: ") # 接受动态输入的模块名并导入模块 mod = __import__(module) # 查看导入的模块里都有什么 # print(dir(mod)) # [‘Apple‘, ‘AppleFactory‘, ‘Pear‘, ‘PearFactory‘, ‘__builtins__‘, ‘__cached__‘, ‘__doc__‘, ‘__file__‘, ‘__loader__‘, ‘__name__‘, ‘__package__‘, ‘__spec__‘] # 调用模块下面的方法执行 promont = mod.AppleFactory().create("苹果") promont.appleguantou()
执行结果:

上面实现了动态输入模块名,从而能够输入模块名并且执行里面的函数。但是有一个缺点,那就是执行的函数被固定了。能不能改进一下,动态输入函数名,动态输入参数并且来执行呢?当然可以,且看
2. __getattr__()
作用:
(1) 从导入模块中(第一个参数mod)找到你需要调用的函数(第二个参数class_),
(2)然后返回一个该函数的引用<class ‘fruitfactorypractice.PearFactory‘>,没有找到就烦会None
# 输入字符串形式的模块名,函数名,参数名等 module = input("请输入你要导入的模块名: ") class_ = input("请选择类型: ") fruit_name = input("请选择水果: ") # 1.实现通过字符串的形式,导入模块 mod = __import__(module) # 2.通过字符串的形式,去模块寻找指定函数 ‘‘‘ 作用:从导入模块中(第一个参数mod)找到你需要调用的函数(第二个参数class_), 然后返回一个该函数的引用<class ‘fruitfactorypractice.PearFactory‘>,没有找到就烦会None ‘‘‘ obj = getattr(mod, class_, None) print(obj) # 执行函数 if class_ == "AppleFactory": # 生产苹果罐头 obj().create(fruit_name).appleguantou() elif class_ == "PearFactory": # 生产雪梨罐头 obj().create().pearguantou(fruit_name) else: print("不生产{}这种罐头".format(fruit_name))


上面我们就实现了,动态导入一个模块,并且动态输入函数名然后执行相应功能。
还存在一点点小问题:那就是模块名有可能不是在本级目录中存放着。有可能是如下图存放方式:

那么这种方式我们该如何搞定呢?看下面代码:
dd = __import__("lib.text.commons") #这样仅仅导入了lib模块 dd = __import__("lib.text.commons",fromlist = True) #改用这种方式就能导入成功 # 等价于import config inp_func = input("请输入要执行的函数:") f = getattr(dd,inp_func) f()
2. hasattr(object, name)
判断对象object是否包含名为name的特性(hasattr是通过调用getattr(ojbect, name)是否抛出异常来实现的)
object:表示对象,可以是类名,也可以是实例名
name: 属性名,是个字符串形式的
# 示例代码 class Test(): def __init__(self, name, price): self.name = name self.price = price def unit(self): pass test = Test(‘彩票‘,666)
print(hasattr(test, ‘name‘)) print(hasattr(test, ‘prce‘)) print(hasattr(test, ‘unit‘)) # True # False # True
3. delattr(object, name) 与setattr()相关的一组函数。参数是由一个对象(记住python中一切皆是对象)和一个字符串组成的。string参数必须是对象属性名之一。该函数删除该obj的一个由string指定的属性。delattr(x, ‘foobar‘)=del x.foobar
object:表示对象,可以是类名,也可以是实例名
name: 属性名,是个字符串形式的
# 先删除属性 delattr(test, ‘name‘) # 再通过hasattr()查看该属性是否还存在 print(hasattr(test,‘name‘)) # False # 注意: # 这不是真的删除,而是只在内存里操作
4. setattr(object, name, value)
这是相对应的getattr()。参数是一个对象,一个字符串和一个任意值。字符串可能会列出一个现有的属性或一个新的属性。
这个函数将值赋给属性的。该对象允许它提供。例如,setattr(x,“foobar”,123)相当于x.foobar = 123。
# 修改name属性的值 setattr(test,‘name‘,‘励志人生‘) print(test.name)
注:getattr,hasattr,setattr,delattr对模块的修改都在内存中进行,并不会影响文件中真实内容。
四. 单例模式 -- 背下来
单例模式(Singleton Pattern)是一种常用的软件设计模式,该模式的主要目的是确保某一个类只有一个实例存在。当你希望在整个系统中,某个类只能创建一个实例时,单例对象就能派上用场。
常见的配置文件,数据库连接等都会用到单例模式
https://www.cnblogs.com/huchong/p/8244279.html 参考示例
实现单例模式有很多种方法
(1)基于__new__方法实现(推荐使用,方便)---要背下来
原理:我们知道,当实例化一个对象时,是先执行了类的__new__方法(我们没写时,默认调用object.__new__)实例化对象;然后再执行类的__init__方法,对这个对象进行初始化,所有我们可以基于这个,改造__new__()方法,实现单例模式.
class Singleton(): def __new__(cls, *args, **kwargs): # 在 new之前判断一下,如果已经存在"_instance",就直接返回cls._instance # 如果不存在,就创建一个 if not hasattr(cls, ‘_instance‘): print("还没有实例,即将创建一个实例") cls._instance = super(Singleton, cls).__init__(cls, ) return cls._instance # 实例化第一个实例,执行了if内的语句 single1 = Singleton() # 还没有实例,即将创建一个实例 # 实例化第二个实例,没有执行if内的语句,因为已经存在一个实例了 single2 = Singleton() # 通过id,内存地址验证,两个实例就是同一个对象 print(id(single1)) print(id(single2)) # 4334057560 # 4334057560
继承单例
# 一个类继承于Singleton,如果也想让Apple只能创建一个实例,那只能在Apple类中__new__ class Apple(Singleton): def __new__(cls, *args, **kwargs): super(Apple, cls).__new__(cls) apple1 = Apple() apple2 = Apple() print(id(apple1)) print(id(apple2)) # 4326180952 # 4326180952
(2) 使用装饰器 实现单例模式---很多面试可能会问,要背下来
基于闭包实现
# 函数套函数,是闭包 ‘‘‘ 原理: 1. 有个字典 2. 以类名为key,以对象为value,存到这个字典里 3. 如果不存在就创建;如果存在就直接返回 ‘‘‘ def singleton(cls, *args, **kw): instances = {} def get_instance(): if cls not in instances: # 以类为key,以类的对象为值,存储起来 instances[cls] = cls(*args, **kw) return instances[cls] return get_instance # 修饰器是写函数名的,不能加();如果加()就是调用运行 @singleton class Apple(object): pass apple1 = Apple() apple2 = Apple() apple3 = Apple() print(id(apple1)) print(id(apple2)) print(id(apple3)) # 4381172848 # 4381172848 # 4381172848
练习:
用类实现栈和队列的留个方法(代码)
先来了解下什么是栈和队列?
栈(stack):是一种只能通过访问其一端来实现数据存储与检索的线性数据结构,具有后进先出(last in first out,LIFO)的特征
队列(queue): 也是元素按照顺序排列,但是元素的进出顺序具有 先进先出 的特征
栈和队列都有六个方法
|
方法 |
含义 |
|
push(element) |
将数据存入栈 |
|
pop |
将数据取出栈,从栈里面移出去了 |
|
empty |
判断栈是否空 |
|
full |
判断栈是否满 |
|
find(element) |
查找元素返回位置(下标) |
|
peek |
返回栈顶的元素,但是不从栈里移出去 |
第四十篇 Python之设计模式总结-简单工厂、工厂方法、抽象工厂、单例模式
标签:找到你 play tin opened 基于 实现 class 缺点 传参
原文地址:https://www.cnblogs.com/victorm/p/9411258.html
