II. Applications
This part is written for general readers. At the same time, it will be of greater value for readers with some knowledge about RL.
Resources management in computer clusters
Designing algorithms to allocate limited resources to different tasks is challenging and requires human-generated heuristics. The paper “Resource Management with Deep Reinforcement Learning” [2] showed how to use RL to automatically learn to allocate and schedule computer resources to waiting jobs, with the objective to minimize the average job slowdown.
State space was formulated as the current resources allocation and the resources profile of jobs. For action space, they used a trick to allow the agent to choose more than one action at each time step. Reward was the sum of (-1/duration of the job) over all the jobs in the system. Then they combined REINFORCE algorithm and baseline value to calculate the policy gradients and find the best policy parameters that give the probability distribution of actions to minimize the objective. Click here to view the code on Github.
Traffic Light Control
In the paper “Reinforcement learning-based multi-agent system for network traffic signal control”[3], researchers tried to design a traffic light controller to solve the congestion problem. Tested only on simulated environment though, their methods showed superior results than traditional methods and shed a light on the potential uses of multi-agent RL in designing traffic system.
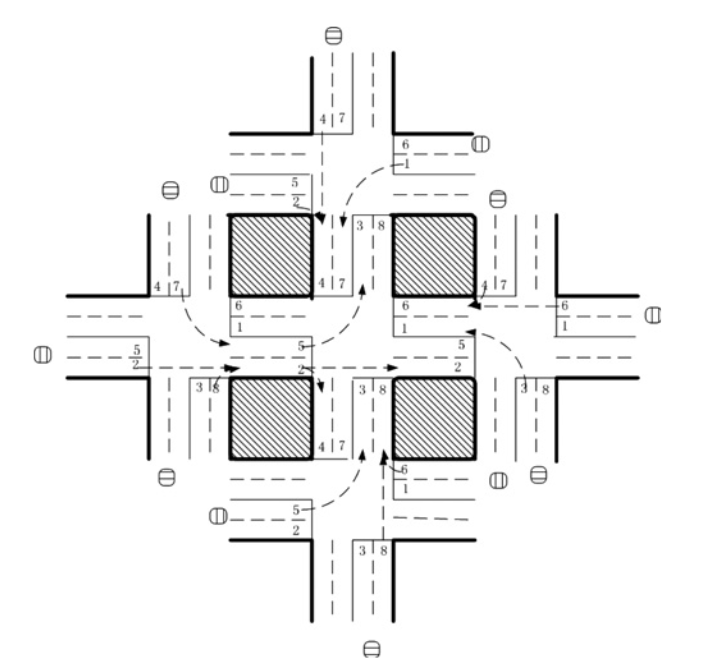
Five-intersection traffic network. Source.
Five agents were put in the five-intersection traffic network, with a RL agent at the central intersection to control traffic signaling. The state was defined as eight-dimensional vector with each element representing the relative traffic flow of each lane. Eight choices were available to the agent, each representing a phase combination, and the reward function was defined as reduction in delay compared with previous time step. The authors used DQN to learn the Q value of the {state, action} pairs.
Robotics
There are tremendous work on applying RL in Robotics. Readers are referred to [10] for a survey of RL in Robotics. In particular, [11] trained a robot to learn policies to map raw video images to robot’s actions. The RGB images were fed to a CNN and outputs were the motor torques. The RL component was the guided policy search to generate training data that came from its own state distribution.

Web System Configuration
There are more than 100 configurable parameters in a web system and the process of tuning the parameters requires a skilled operator and numerous trail-and-error tests. The paper “A Reinforcement Learning Approach to Online Web System Auto-configuration” [5] showed the first attempt in the domain on how to do autonomic reconfiguration of parameters in multi-tier web systems in VM-based dynamic environments.
The reconfiguration process can be formulated as a finite MDP. The state space was the system configuration, action space was {increase, decrease, keep} for each parameter, and reward was defined as the difference between the given targeted response time and measured response time. The authors used the model-free Q-learning algorithm to do the task.
Although the authors used some other technique like policy initialization to remedy the large state space and computational complexity of the problem instead of the potential combinations of RL and neural network, it is believed that the pioneering work has paved the way for future research in this area.
Chemistry
RL can also be applied in optimizing chemical reactions.[4] showed that their model outperformed a state-of-the-art algorithm and generalized to dissimilar underlying mechanisms in the paper “Optimizing Chemical Reactions with Deep Reinforcement Learning”.
Combined with LSTM to model the policy function, the RL agent optimized the chemical reaction with the Markov decision process (MDP) characterized by {S, A, P, R}, where S was the set of experimental conditions (like temperature, pH, etc), A was the set all possible actions that can change the experimental conditions, P was the transition probability from current experiment condition to the next condition, and R was the reward which is a function of the state.
The application is a great one to demonstrate how RL can reduce time-consuming and trial-and-error work in a relatively stable environment.
Personalized Recommendations
Previous work of news recommendations faced several challenges including the rapid changing dynamic of news, users get bored easily and Click Through Rate cannot reflect the retention rate of users. Guanjie et al. have applied RL in news recommendation system in a paper titled “DRN: A Deep Reinforcement Learning Framework for News Recommendation” to combat the problems [1].
In practice, they constructed four categories of features, namely A)user features and B)context features as the state features of the environment, and C)user-news features and D)news features as the action features. The four features were input to the Deep Q-Network(DQN) to calculate the Q-value. A list of news were chosen to recommend based on the Q-value, and the user’s click on the news was a part of the reward the RL agent received.
The authors also employed other techniques to address other challenging problems, including memory replay, survival models, Dueling Bandit Gradient Descent and so on. Please refer to the paper for details.
Bidding and Advertising
Researchers from Alibaba Group published a paper “Real-Time Bidding with Multi-Agent Reinforcement Learningin Display Advertising” [6] and claimed that their distributed cluster-based multi-agentbidding solution (DCMAB) has achieved promising results and thus they plan to conduct a live test in Taobao platform.
The details of the implementation are left to users to investigate. Generally speaking, Taobao ad platform is a place for merchants to place a bid in order to display ad to the customers. This could be a multi-agent problem because the merchants are bidding against each other and their actions are interrelated. In the paper, merchants and customers were clustered into different groups to reduce computational complexity. The state space of the agents indicated the cost-revenue status of the agents, action space was the bid (continuous), and reward was the revenue caused by the customer cluster.
The DCMAB algorithm. Source: https://arxiv.org/pdf/1802.09756.pdf
Other questions, including the impact of different reward settings (self-interested vs coordinate) on agents’ revenue were also studied in the paper.
Games
RL is so well-known these days because it is the mainstream algorithm used to solve different games and sometimes achieve super-human performance.
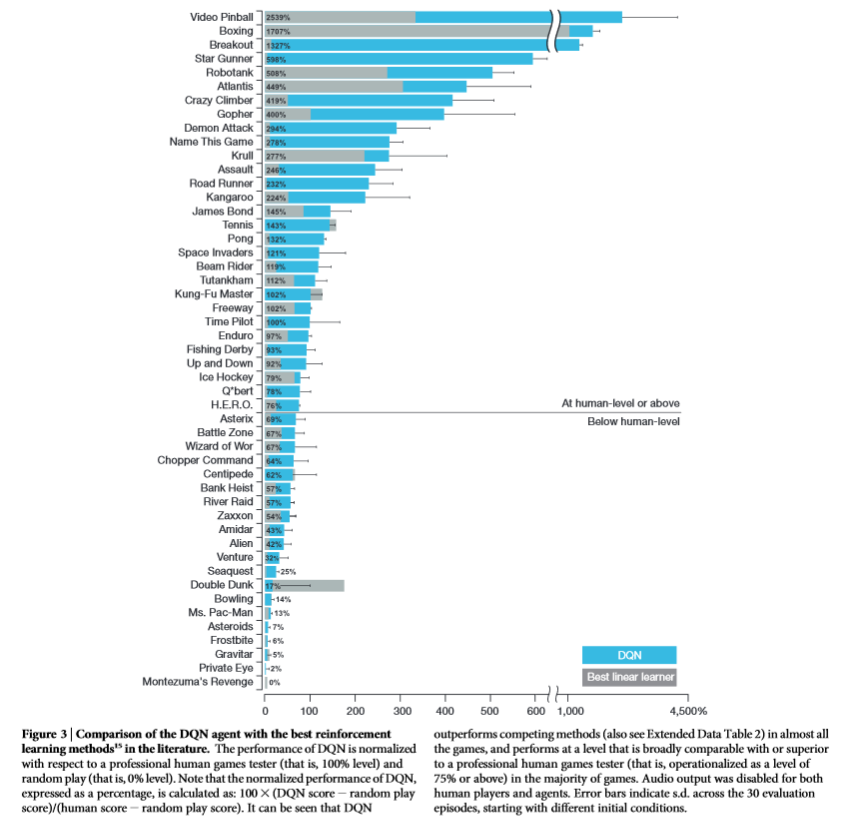
RL vs linear model vs Human. Click here for the source.
The most famous one must be AlphaGo[12] and AlphaGo Zero[13]. AlphaGo, trained with countless human games, already achieved super-human performance by using value network and Monte Carlo tree search (MCTS) in its policy network. Yet, the researchers later on thought back and tried a purer RL approach?—?train it from scratch. The researchers let the new agent, AlphaGo Zero, played with itself and finally beat AlphaGo 100–0.
Deep Learning
More and more attempts to combine RL and other deep learning architecture can be seen recently and they showed impressive results.
One of the most influential work in RL is the pioneering work of Deepmind to combine CNN with RL [7]. By doing so, the agent has the ability to “see” the environment through high-dimensional sensory and then learn to interact with it.
RL and RNN is another combinations people used to try new idea. RNN is a type of neural network that has “memories”. When combined with RL, RNN gives the agents’ ability to memorize things. For example, [8] combined LSTM with RL to create Deep Recurrent Q-Network(DRQN) to play Atari 2600 games. [4] also used RNN and RL to solve chemical reaction optimization problem.
Deepmind showed [9] how to use generative models and RL to generate programs. In the model, the adversarially trained agent used the signal as rewards to improve the actions, instead of propagating the gradients to the input space as in the GAN training.
Input vs Generated result. See source.