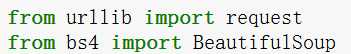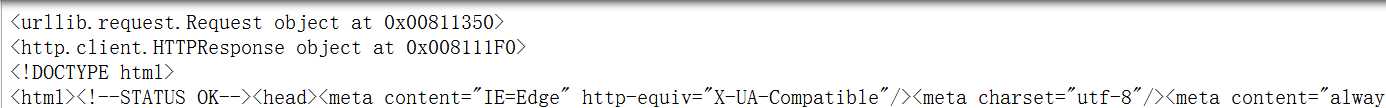标签:选择 自己 network xhr work htm 多个 python爬虫 构建
关于python爬虫多个库的选择反反复复,总是不知道选择哪个,通过试过多个晚上的选择
以上两个库足够爬虫,已反爬虫网站数据的爬取。先上代码:
url=‘**********************‘
python 爬虫新解
原文地址:https://www.cnblogs.com/yxxblog/p/9427907.html