标签:缓冲 存在 重要 变化 线程 传递 操作系统 new 管理者
前言“天下武功,唯快不破”,火云邪神告诉了你体术中追求的境界;相对论也告诉大家当你的移动速度逐渐超过光速甚至再快更快,你就很容易去到诗和远方,游火星,逛土星,浪迹天涯;当单核计算机从出现到一代代地提升性能,运算力也在更快更强。甚至就是奥运会都追求“更快、更高、更强”,似乎“快”对人们有着与生俱来的诱惑。那么“快节奏和从前慢一生只够爱一个人”,你又有着怎样的思考呢,抱歉~这里暂不讨论。其实啊,人们不断压榨计算工具的运算力和老板不停压榨员工的体力一样也都是有快感的。既然是压榨,总有一天可能几近榨不出油水,咋办?
这不,单核CPU的主频不可能无限制的增长,Intel老板给跪了。再想提升性能,于是CPU进入多核时代,多个处理器协同工作。什么,协同工作?小学自习课最能咋呼的是你,中学最不服管的也是你,其实很多时候不是追求的一加一大于二,而是一加一不小于一,人越多越乱,事越多越烦,一个道理,增加CPU数量可不是简单的一加一,变量越多,带来的不确定性也就越多,天赋异禀的人更适合做管理者,当然具备足够完善和周密的算法的操作系统才能协同好计算机。
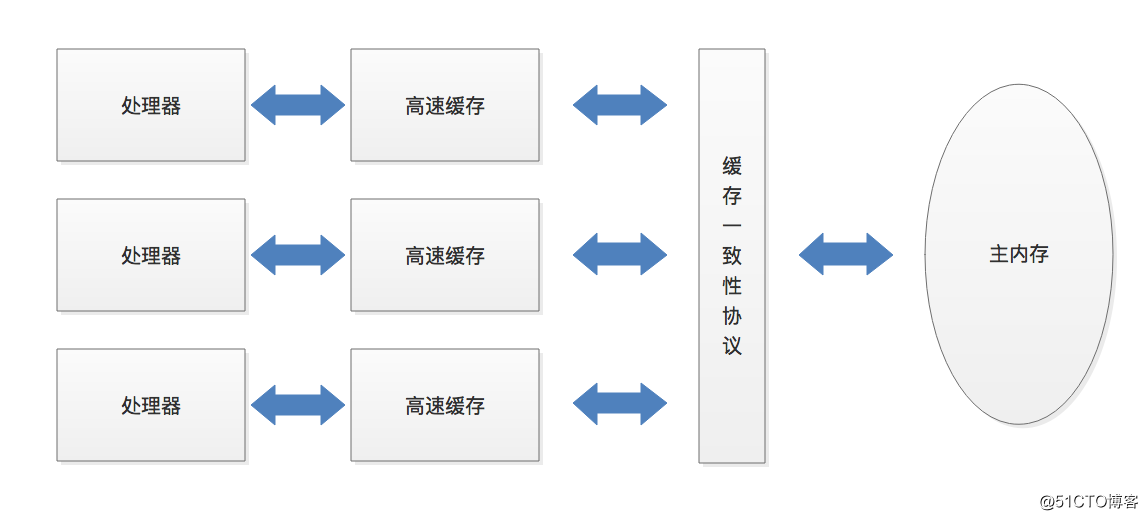
多任务处理在现代计算机操作系统中几乎是一项必备的功能。许多情况下,让计算机同时去做几件事情,不仅是因为计算机的运算能力强大了,还有一个很重要的原因是计算机的运算速度与它的存储和通信子系统速度的差距太大。计算机的存储设备与处理器的运算速度有几个数量级的差距,所以现代计算机都不得不加入一层读写速度尽可能接近处理器运算速度的高速缓存来作为内存与处理器之间的缓冲,这种解决思想呢就是缓冲技术。
基于高速缓存的存储交互很好地解决了处理器与内存的速度矛盾,但是也为计算机系统带来了更高的复杂度,引入了新的问题:缓存一致性。在多处理器系统中,每个处理器都有自己的高速缓存,而又共享同一主内存。
有着相同目标,在不改变程序执行结果的前提下,尽可能提高并行度。
处理器不会改变存在数据依赖关系的两个操作的执行顺序。
处理器保证单线程程序的重排序不改变执行结果。
越是追求性能的处理器,内存模型设计得越弱,束缚少,尽可能多的优化来提高性能。
编译器不会改变存在数据依赖关系的两个操作的执行顺序。
除了增加高速缓存之外,为了使得处理器内部的运算单元能尽量被充分利用,处理器可能会对输入代码进行乱序执行优化,处理器会在计算之后将乱序执行的结构重组。
如果两个操作访问同一个变量,且这两个操作中有一个为写操作,那么这两个操作之间存在数据依赖性。
1)写这个变量后,再读这个变量;
2)写这个变量后,再写这个变量;
3)读这个变量后,再写这个变量;
上面3种情况,只要重排两个操作的执行顺序,执行结果就会被改变。
语义是:不管编译器和处理器为了提高并行度怎么重排序,单线程程序的执行结果不能被改变。
happens-before要求禁止的重排序分为两类:
1)会改变程序执行结果的重排序。
JMM处理策略要求编译器和处理器必须禁止这种重排序。
2)不会改变程序执行结果的重排序。
JMM处理策略允许编译器和处理器这种重排序。
规则定义:
1)程序顺序规则:一个线程中的每个操作,happens-before该线程的任意后续操作。
2)监视器锁规则:对一个锁的解锁,happens-before于随后对这个锁的加锁。
3)volatile变量规则:对一个volatile域的写,happens-before于任意后续对这个volatile域的读。
4)传递性:如果A happens-before B,且B happens-before C,那么A happens-before C。
5)start()规则:如果线程A执行操作ThreadB.start()启动线程B,那么A线程的ThreadB.start()操作happens-before于线程B中的任意操作。
6)join()规则:如果线程A执行操作Thread.join()并成功返回,那么线程B中的任意操作happens-before于线程A从Thread.join()操作成功返回。
1)as-if-serial语义保证单线程内程序的执行结果不被改变;happens-before关系保证正确同步的多线程程序的执行结果不被改变。
2)as-if-serial语义创造单线程程序幻境:单线程程序是按程序的顺序来执行的;happens-before关系创造多线程程序幻境:正确同步的多线程程序是按happens-before关指定的顺序来执行的。
Java内存模型规范对数据竞争的定义:
在一个线程中写一个变量,在另一个线程读同一个变量,而且写和读没有通过同步来排序。
JMM允许编译器和处理器只要不改变程序执行结果,包括单线程程序和正确同步的多线程程序,怎么优化都行。
常见的处理器内存模型比JMM要弱,Java编译器在生成字节码时,会在执行指令序列的适当位置插入内存屏障来限制处理器的重排序。各种处理器内存模型的强弱不同,JMM在不同处理器中插入的内存屏障的数量和种类也不相同。
1)lock(锁定):作用于主内存的变量,把一个变量标识为一条线程独占的状态。
2)unlock(解锁):作用于主内存的变量,把一个处于锁定状态的变量释放出来,解锁后的变量才可以被其他线程锁定。
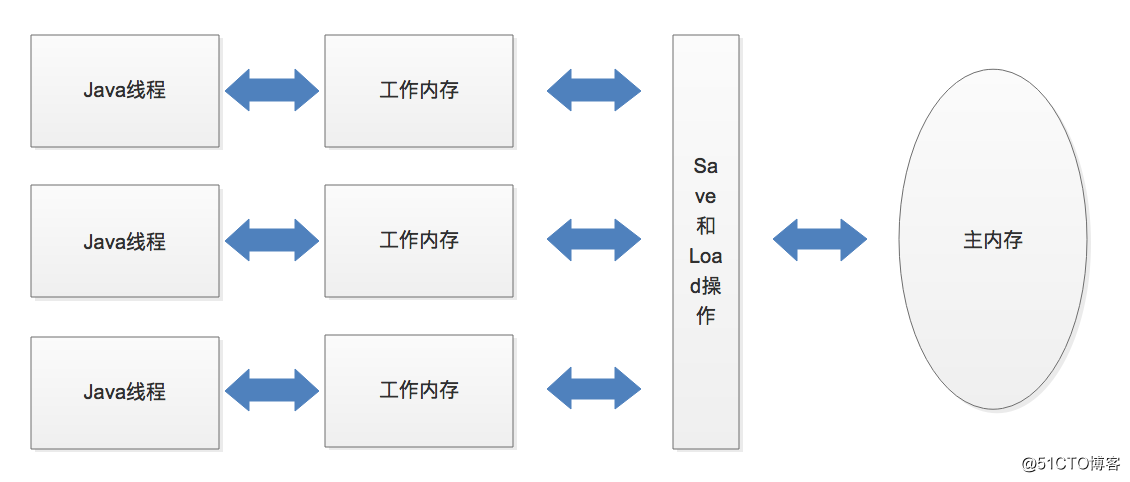
3)read(读取):作用于主内存的变量,把一个变量的值从主内存传输到线程的工作内存中,以便随后的load操作使用。
4)load(载入):作用于工作内存的变量,把read操作从主内存中得到的变量值放入工作内存的变量副本中。
5)use(使用):作用于工作内存的变量,把工作内存中一个变量的值传递给执行引擎,每当虚拟机遇到一个需要使用到的变量的值的字节码指令时将会执行这个操作。
6)assign(赋值):作用于工作内存的变量,把一个从执行引擎收到的值赋给工作内存的变量,每当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作。
7)store(存储):作用于工作内存的变量,把工作内存中一个变量的值传送到主内存中,以便随后的write操作使用。
8)write(写入):作用于主内存的变量,把store操作冲工作内存中得到的变量的值放入主内存的变量中。
1)不允许read和load、store和write操作之一单独出现,即不允许一个变量从主内存读取了但工作内存不接受,或者从工作内存发起回写了但主内存不接受的情况出现。
2)不允许一个线程丢弃它的最近的assign操作,即变量在工作内存中改变了之后必须把该变化同步回主内存。
3)不允许一个线程无原因地(没有发生过任何assign操作)把数据从线程的工作内存同步回主内存中。
4)一个新的变量只能在主内存中“诞生”,不允许在工作内存中直接使用一个未被初始化的变量,换句话说,对一个变量实施use、store操作之前,必须先执行过了assign和load操作。
5)一个变量在同一时刻只允许一条线程对其进行lock操作,但lock操作可以被同一条线程重复执行多次,多次执行lock后,只有执行相同次数的unlock操作,变量才会被解锁。
6)如果对一个变量执行lock操作,那将会清空工作内存中此变量的值,在执行引擎使用这个变量前,需要重新执行load或assign操作初始化变量的值。
7)如果一个变量事先没有被lock操作锁定,那就不允许对它执行unlock操作,也不允许去unlock一个被其他线程锁定的变量。
8)对一个变量执行unlock操作之前,必须先把此变量同步回主内存中。
语义:
线程A释放一个锁,实质上是线程A向接下来将要获取这个锁的某个线程发出了(线程A对共享变量所做修改的)消息。
线程B获取一个锁,实质上是线程B接收了之前某个线程发出的(在释放这个锁之前对共享变量所做修改的)消息。
线程A释放锁,随后线程B获取这个锁,这个过程实质上是线程A通过主内存向线程B发送消息。
实现:
见AQS等。
语义:
线程A写一个volatile变量,实质上是线程A向接下来将要读这个volatile变量的某个线程发出了(其对共享变量所做修改的)消息。
线程B读一个volatile变量,实质上是线程B接收了之前某个线程发出的(在写这个volatile变量之前对共享变量所做修改的)消息。
线程A写一个volatile变量,随后线程B读这个volatile变量,这个过程实质上是线程A通过主内存向线程B发送消息。
JMM实现:
表现:
对于final域,编译器和处理器要遵守两个重排序规则:
编译器final语义具体实现:
public class FinalExample {
int i;
final int j;
static FinalExample obj;
public FinalExample(){
i = 1;
j = 2;
// final域 StoreStore屏障 在这里
// 确保构造函数return前 final域 j=2 完成
}
public static void write(){
obj = new FinalExample();
}
public static void reader(){
FinalExample object = obj;
int a = object.i;
// final域 LoadLoad屏障 在这里
// 确保初次读对象包含的final域前 读对象引用完成
int b = object.j;
}
}参考文献《深入理解Java 虚拟机》、《Java并发编程的艺术》
标签:缓冲 存在 重要 变化 线程 传递 操作系统 new 管理者
原文地址:http://blog.51cto.com/damon188/2155472