标签:src 磁盘 1.3 oid config 重载 lse 开放 字符串
Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在Java开发环境里Lucene是一个成熟的免费开源工具。就其本身而言,Lucene是当前以及最近几年最受欢迎的免费Java信息检索程序库。人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆。
Lucene是Apache提供的一个开源的全文检索引擎工具包, 其本质就是一个工具包, 而非一个完整的搜索引擎, 但是我们可以通过Lucene来构建一个搜索引擎,比如solr和elasticsearch都是基于Lucene的搜索引擎。
第一步:导入相关的jar包
<dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-core</artifactId> <version>4.10.2</version> </dependency> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-queries</artifactId> <version>4.10.2</version> </dependency> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-test-framework</artifactId> <version>4.10.2</version> </dependency> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-analyzers-common</artifactId> <version>4.10.2</version> </dependency> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-queryparser</artifactId> <version>4.10.2</version> </dependency> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-highlighter</artifactId> <version>4.10.2</version> </dependency>
第二步:书写写入索引的代码
简单案例:
public class LuceneIndex { public static void main(String[] args) throws IOException { //1 创建indexwriter对象 //1.1 创建索引库 FSDirectory directory = FSDirectory.open(new File("H:\\test")); //1.2 创建写入器配置对象 参数1 版本号, 参数2 分词器 IndexWriterConfig config = new IndexWriterConfig(Version.LATEST, new StandardAnalyzer()); //1.3 创建indexwriter对象 IndexWriter indexWriter = new IndexWriter(directory, config); //2 写入文档 //2.1 创建文档对象(lucene的document对象) Document document = new Document(); //2.2 添加文档属性(字段) new xxxField(字段名,字段值,是否保存) document.add(new IntField("id", 1, Field.Store.YES)); document.add(new StringField("title", "Lucene介绍", Field.Store.YES)); document.add(new TextField("content", "Lucene是一个全文检索的工具包", Field.Store.YES)); //2.3 写入文档 indexWriter.addDocument(document); //3 提交数据 indexWriter.commit(); //释放资源 indexWriter.close(); } }
下载一个lukeall-xxxx(版本信息).jar, cmd运行这个工具jar包:
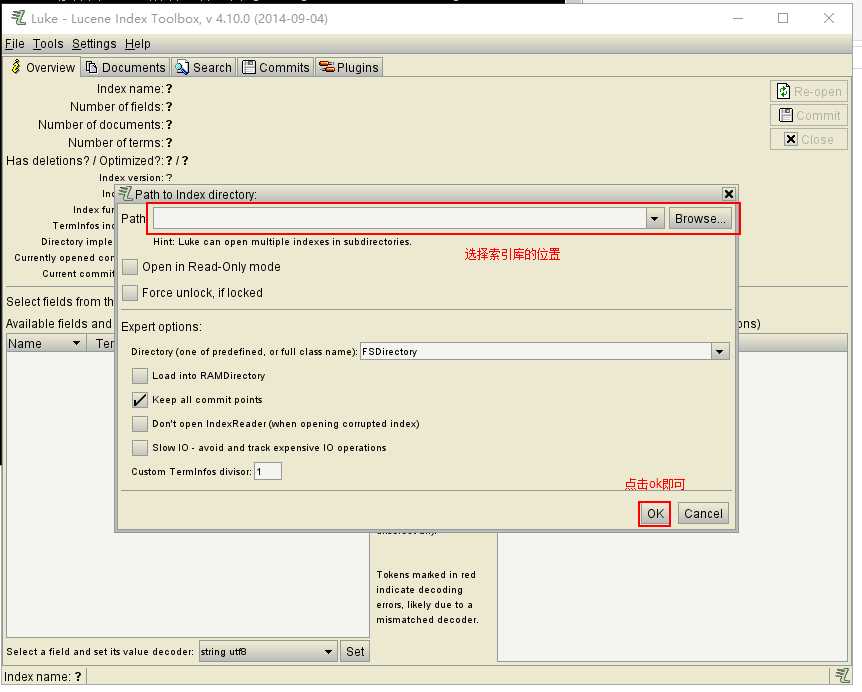
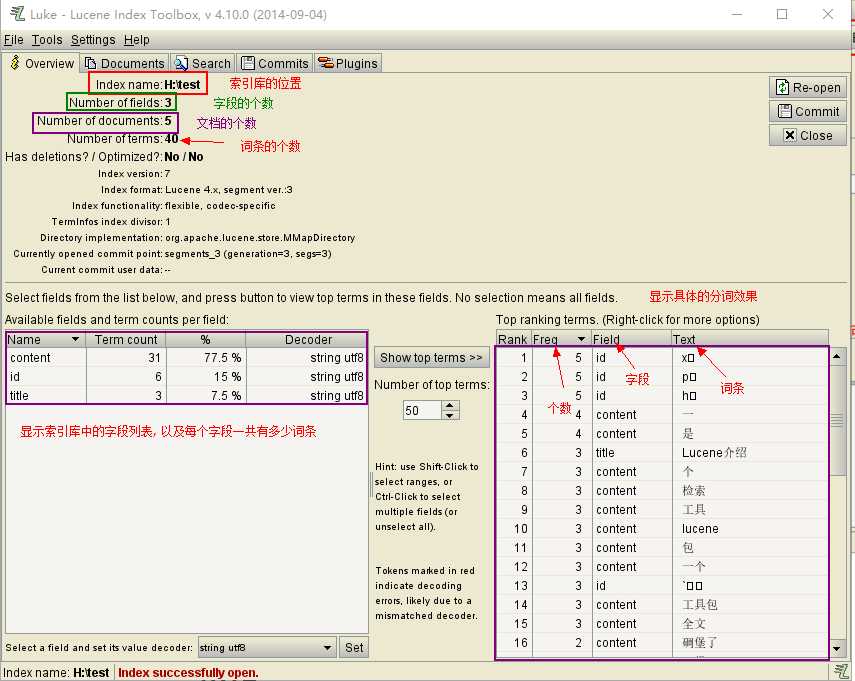
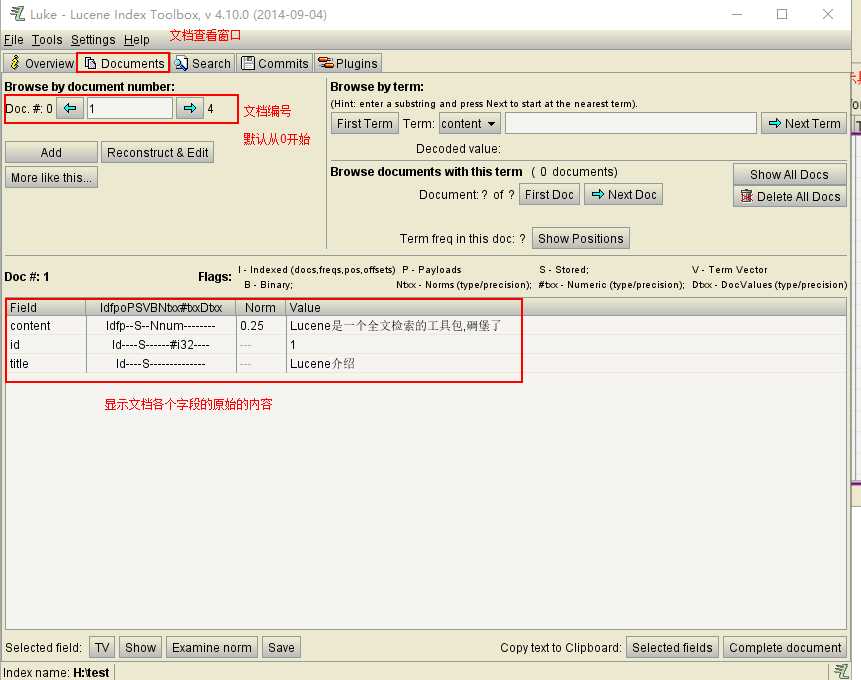
? 用于对文档中的数据进行分词, 其分词的效果取决于分词器的选择, Lucene中根据各个国家制定了各种语言的分词器,对中文有一个ChineseAnalyzer 但是其分词的效果, 是将中文进行一个一个字的分开
针对中文分词一般只能使用第三方的分词词,比如IKAnalyzer
首先要引入jar包:
<!-- 引入IK分词器 --> <dependency> <groupId>com.janeluo</groupId> <artifactId>ikanalyzer</artifactId> <version>2012_u6</version> </dependency>
代码部分只需要修改我们上面案例的分词器对象即可:
//1.2 创建写入器配置对象 参数1 版本号, 参数2 分词器 IndexWriterConfig config = new IndexWriterConfig(Version.LATEST, new IKAnalyzer());
ik分词器在2012年更新后, 就在没有更新, 其原因就取决于其强大的扩展功能,以保证ik能够持续使用
ik支持对自定义词库, 其可以定义两个扩展的词典
1) 扩展词典(新创建词功能):有些词IK分词器不识别 例如:“剑来”,“剑九黄”
2) 停用词典(停用某些词功能)有些词不需要建立索引 例如:“哦”,“啊”,“的”
如何使用:
在resources内创建者三个文件,在ext.dic中设置需要进行分词的内容即可, 在stopword中设置不被分词的内容即可,xml文件内容格式如下:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict">ext.dic;</entry> <!--用户可以在这里配置自己的扩展停止词字典--> <entry key="ext_stopwords">stopword.dic;</entry> </properties>
其他两个词典内容格式:
剑来
剑九黄
剑开天门
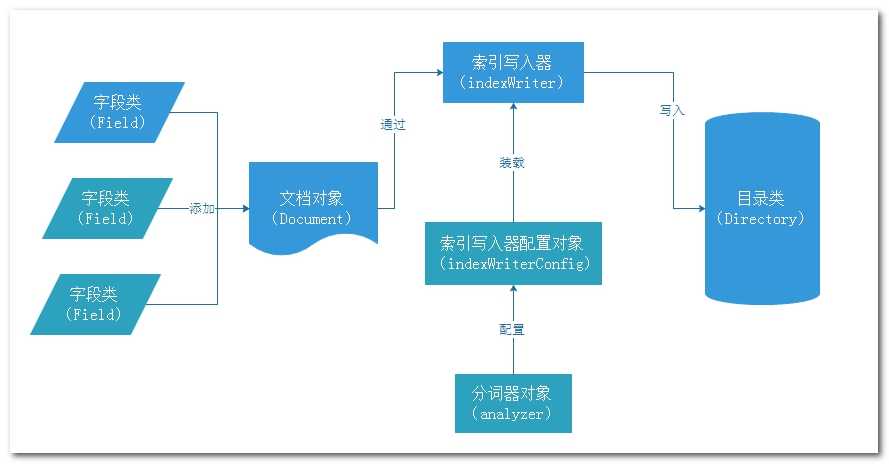
其主要的作用, 添加索引, 修改索引和删除索引
创建此对象的时候, 需要传入Directory和indexWriterConfig对象
Directory: 目录类, 用来指定索引库的目录
常用的实现类:
FSDirectory: 用来指定文件系统的目录, 将索引信息保存到磁盘上
优点: 索引可以进行长期保存, 安全系数高
缺点: 读取略慢
RAMDriectory: 内存目录, 将索引库信息存放到内存中
优点: 读取速度快
缺点: 不安全, 无法长期保存, 关机后就消失了
IndexWriterConfig: 索引写入器的配置类
创建此对象, 需要传递Lucene的版本和分词器
作用:
作用1 : 指定Lucene的版本和需要使用的分词器
作用2: 设置Lucene的打开索引库的方式: setOpenMode();
//参数值: APPEND CREATE CREATE_OR_APPEND /** * APPEND: 表示追加, 如果索引库存在, 就会向索引库中追加数据, 如果索引库不存在, 直接报错 * * CREATE: 表示创建, 不管索引库有没有, 每一次都是重新创建一个新的索引库 * * CREATE_OR_APPEND: 如果索引库有, 就会追加, 如果没有 就会创建索引库 默认值也是 CREATE_OR_APPEND */ config.setOpenMode(IndexWriterConfig.OpenMode.CREATE_OR_APPEND);
? 在Lucene中, 每一条数据以文档的形式进行存储, 文档中也有其对应的属性和值, Lucene中一个文档类似数据库的一个表, 表中的字段类似于文档中的字段,只不过这个文档只能保存一条数据
? Document看做是一个文件, 文件的属性就是文档的属性, 文件对应属性的值就是文档的属性的值 content
一个文档中可以有多个字段, 每一个字段就是一个field对象,不同的文档可以有不同的属性
字段也有其对应数据类型, 故Field类也提供了各种数据类型的实现类
| Field类 | 数据类型 | Analyzed是否分析 | Indexed是否索引 | Stored是否存储 | 说明 |
|---|---|---|---|---|---|
| StringField(FieldName, FieldValue,Store.YES)) | 字符串 | N | Y | Y或N | 这个Field用来构建一个字符串Field,但是不会进行分析,会将整个串存储在索引中,比如(订单号,姓名等)是否存储在文档中用Store.YES或Store.NO决定 |
| LongField(FieldName, FieldValue,Store.YES) | Long型 | Y | Y | Y或N | 这个Field用来构建一个Long数字型Field,进行分析和索引,比如(价格)是否存储在文档中用Store.YES或Store.NO决定 |
| StoredField(FieldName, FieldValue) | 重载方法,支持多种类型 | N | N | Y | 这个Field用来构建不同类型Field不分析,不索引,但要Field存储在文档中 |
| TextField(FieldName, FieldValue, Store.NO)或TextField(FieldName, reader) | 字符串或流 | Y | Y | Y或N | 如果是一个Reader, lucene猜测内容比较多,会采用Unstored的策略. |
/** * 更新索引 * 本质先删除再添加 * 先删除所有满足条件的文档,再创建文档 * 因此,更新索引通常要根据唯一字段 */ @Test public void testUpdate() throws Exception { // 创建更改后的文档对象 Document document = new Document(); document.add(new StringField("id", "3", Field.Store.YES)); document.add(new TextField("title", "更改后的titlek", Field.Store.YES)); // 索引库对象 Directory directory = FSDirectory.open(new File("H:\\test")); // 索引写入器配置对象 IndexWriterConfig conf = new IndexWriterConfig(Version.LATEST, new IKAnalyzer()); // 索引写入器对象 IndexWriter indexWriter = new IndexWriter(directory, conf); // 执行更新操作 参数1 要更改的对象, 参数2 更改后的对象 indexWriter.updateDocument(new Term("id", "1"), document); // 提交 indexWriter.commit(); // 关闭 indexWriter.close(); } // 删除索引 @Test public void testDelete() throws Exception { // 创建目录对象 Directory directory = FSDirectory.open(new File("H:\\test")); // 创建索引写入器配置对象 IndexWriterConfig conf = new IndexWriterConfig(Version.LATEST, new IKAnalyzer()); // 创建索引写入器对象 IndexWriter indexWriter = new IndexWriter(directory, conf); // 执行删除操作(根据词条),要求id字段必须是字符串类型 indexWriter.deleteDocuments(new Term("id", "5")); // 根据查询条件删除 // indexWriter.deleteDocuments(NumericRangeQuery.newLongRange("id", 2l, 4l, true, false)); // 删除所有 //indexWriter.deleteAll(); // 提交 indexWriter.commit(); // 关闭 indexWriter.close(); }
标签:src 磁盘 1.3 oid config 重载 lse 开放 字符串
原文地址:https://www.cnblogs.com/Alex-zqzy/p/9435623.html