标签:切割 highlight 查找 报错 特殊用法 http 工具 ima 数组
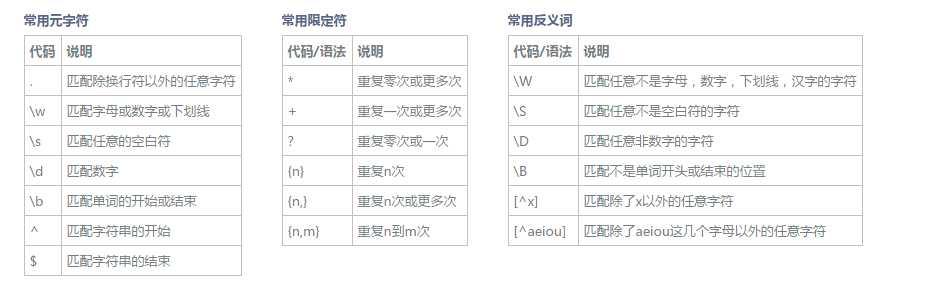
在量词的后面跟了一个 ? 取消贪婪匹配 非贪婪(惰性)模式 最常用 .*?x 匹配任意字符直到找到一个x
import re
ret=re.findall(‘\d+‘,‘fsf4131s4fsg74dsf‘) # 匹配字符串中所有需要的内容
print(ret) #参数:正则表达式,字符串 ,返回一个装有所有匹配上的结果的列表 若没有则是一个空列表
#结果:[‘4131‘, ‘4‘, ‘74‘]
ret2=re.search(‘\d+‘,‘fng231523jsk6313‘) #匹配字符串中第一个需要的内容
print(ret2) #参数:正则表达式,字符串,若匹配正确则返回匹配结果的对象用group查看,若没有则返回None
print(ret2.group())
#结果:
# <_sre.SRE_Match object; span=(3, 9), match=‘231523‘>
# 231523
ret3=re.match(‘\d+‘,‘3fsfs‘) #匹配字符串中开头的内容
print(ret3) #参数:正则表达式,字符串,若匹配正确则返回匹配结果的对象用group查看,若没有则返回None
print(ret3.group())
#结果:
# <_sre.SRE_Match object; span=(0, 1), match=‘3‘>
# 3
ret4=re.split(‘\d+‘,‘3fsfs565df6s5dg6gd2‘) #按需要对字符串进行切割
print(ret4) #参数:正则表达式,字符串 返回切割剩下的值组成的一个列表,当被切割的值处于开头和结尾时,会在列表中留下一个空字符
ret4.remove(‘‘)
ret4.remove(‘‘)
print(ret4)
res=re.split(‘(\d+)‘,‘fsfs5df6s5dg6gd‘) #,可以对正则表达式进行分组(优先显示) 将被切割值显示出来,
print(res)
#结果:
# [‘‘, ‘fsfs‘, ‘df‘, ‘s‘, ‘dg‘, ‘gd‘, ‘‘]
# [‘‘, ‘fsfs‘, ‘df‘, ‘s‘, ‘dg‘, ‘gd‘]
# [‘fsfs‘, ‘5‘, ‘df‘, ‘6‘, ‘s‘, ‘5‘, ‘dg‘, ‘6‘, ‘gd‘]
ret5=re.sub(‘\d+‘,‘B‘,‘afssggsdg45sg45s4g5s‘,3) #按需要对字符串进行替换 默认符合要求的全部替换,可以设置替换次数
print(ret5) #参数:正则表达式,替换后的内容,字符串 返回替换后的字符串
#结果:afssggsdgBsgBsBg5s
ret6=re.subn(‘\d+‘,‘B‘,‘fsd4gg5h4gzx323s‘,3) #按需要对字符串进行替换 默认符合要求的全部替换,可以设置替换次数
print(ret6) #参数:正则表达式,替换后的内容,字符串 返回一个由替换后的字符串和替换次数组成的元组
#结果:(‘fsdBggBhBgzx323s‘, 3)
res=re.compile(‘-[1-9]\d*[.\d]*|-0\.\d*[1-9]\d*‘) #对正则表达式进行编译,需要用到的时候可以配合其他方法使用
ret7=res.findall(‘-205fsf-21sd-2.5g6gg5g‘)
print(ret7)
#结果:[‘-205‘, ‘-21‘, ‘-2.5‘]
ret8=re.finditer(‘\d+‘,‘f56s5f3s‘) # 用法与findall类似,但返回值是一个生成器 ,对生成器迭代得到匹配到的结果的对象 再用group取值
for i in ret8:
print(i)
print(i.group())
#结果:
# <_sre.SRE_Match object; span=(1, 3), match=‘56‘>
# 56
# <_sre.SRE_Match object; span=(4, 5), match=‘5‘>
# 5
# <_sre.SRE_Match object; span=(6, 7), match=‘3‘>
# 3
findall 会优先显示分组中的内容,要想取消分组优先,(?:正则表达式)
split 遇到分组 会保留分组内被切掉的内容
search 如果search中有分组的话,通过group(n)就能够拿到group中的匹配的内容
import re ret = re.findall(‘-0\.\d+|-[1-9]\d*(\.\d+)?‘,‘-1asdada-200‘) print(ret) #结果:[‘‘, ‘‘] ret = re.findall(‘-0\.\d+|-[1-9]\d*(?:\.\d+)?‘,‘-1asdada-200‘) print(ret) #结果 [‘-1‘, ‘-200‘] ret = re.findall(‘www.baidu.com|www.oldboy.com‘,‘www.oldboy.com‘) print(ret) #结果:[‘www.oldboy.com‘] ret = re.findall(‘www.(baidu|oldboy).com‘,‘www.oldboy.com‘) print(ret) #结果:[‘oldboy‘] ret = re.findall(‘www.(?:baidu|oldboy).com‘,‘www.oldboy.com‘) print(ret) #结果:[‘www.oldboy.com‘] ret = re.split(‘\d+‘,‘alex83egon20taibai40‘) print(ret) #结果:[‘alex‘, ‘egon‘, ‘taibai‘, ‘‘] ret = re.split(‘(\d+)‘,‘alex83egon20taibai40‘) print(ret) #结果:[‘alex‘, ‘83‘, ‘egon‘, ‘20‘, ‘taibai‘, ‘40‘, ‘‘] ret = re.search(‘\d+(.\d+.\d+)(.\d+)?‘,‘1.2.3.4-2*(60+(-40.35/5)-(-4*3))‘) print(ret.group(0)) #结果:1.2.3.4 此处group参数 0 可以省略 print(ret.group(1)) #结果:.2.3 print(ret.group(2)) #结果:.4
(?P<name>正则表达式) 表示给分组起名字
(?P=name)表示使用这个分组,这里匹配到的内容应该和分组中的内容完全相同
import re
ret = re.search("<(?P<name>\w+)>(?P<content>\w+)</(?P=name)>","<h1>hello</h1>")
print(ret.group(‘name‘)) #结果 :h1
print(ret.group(‘content‘)) #结果 :hello
print(ret.group()) #结果 :<h1>hello</h1>
import re ret = re.search(r"<(\w+)>\w+</(\w+)><\1>\w+</\2>","<h1>hello</h1><h1>hello</h1>") print(ret.group(1)) #结果: h1 \1 \2 对应前面第几个分组,里面的的内容必须跟对应分组的内容一样,否则会报错 print(ret.group()) #结果 :<h1>hello</h1>
工具网址:http://tool.chinaz.com/regex/?qq-pf-to=pcqq.group
标签:切割 highlight 查找 报错 特殊用法 http 工具 ima 数组
原文地址:https://www.cnblogs.com/luxiangyu111/p/9438090.html