标签:格式化输出 列表 运算 下标 dig 判断 ict 可迭代对象 选择
一. 编码
1. 最早的计算机编码是ASCII. 美国人创建的. 包含了英文字母(大写字母, 小写字母). 数字, 标点等特殊字符!@#$%
128个码位 2**7 在此基础上加了一位 2**8
8位. 1个字节(byte)
2. GBK 国标码 16位. 2个字节(双字节字符)
3. unicode 万国码 32位, 4个字节
4. utf-8: 英文 8 bit 1个字节
欧洲文字 16bit 2个字节
中文 24bit 3个字节
8bit => 1 byte
1024 byte = > 1kb
1024 kb => 1mb
1024mb => 1gb
1024gb = > 1tb
二.python基本数据类型
1). 整数(int)
在python3中所有的整数都是int类型. 但在python2中如果数据量比较?. 会使?long类型.
在python3中不存在long类型
整数可以进行的操作:
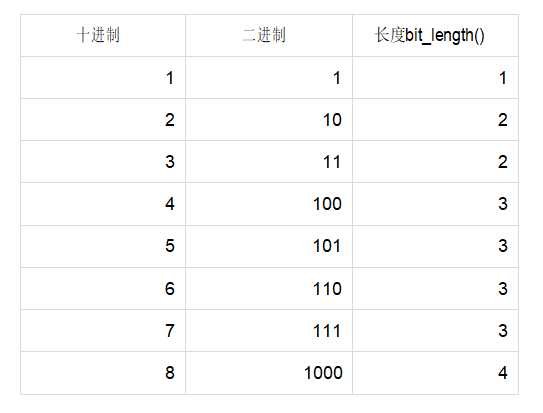
bit_length(). 计算整数在内存中占用的二进制码的长度
三. 布尔值(bool)
取值只有True, False. bool值没有操作.
转换问题:
str => int int(str)
int => str str(int)
int => bool bool(int). 0是False 非0是True
bool=>int int(bool) True是1, False是0
str => bool bool(str) 空字符串是False, 不空是True
bool => str str(bool) 把bool值转换成相应的"值"
四. 字符串(str)
把字符连成串. 在python中?‘, ", ‘‘‘, """引起来的内容被称为字符串.
4.1 切片和索引
1. 索引. 索引就是下标. 切记, 下标从0开始
2. 切片, 我们可以使?下标来截取部分字符串的内容
语法: str[start: end]
规则: 顾头不顾腚, 从start开始截取. 截取到end位置. 但不包括end
步?: 如果是整数, 则从左往右取. 如果是负数. 则从右往左取. 默认是1
切片语法:
str[start:end:step]
start: 起始位置
end: 结束位置
step:步?

s = "alex和wusir经常在一起搞基" s1 = s[5:10] print(s1) s2 = s[0:4] + s[5:10] print(s2) s3 = s[5:] # 默认到结尾 print(s3) s4 = s[:10] # 从头开始 print(s4) s5 = s[:] # 从头到尾都切出来 print(s5) s6 = s[-2:] # 从-2 切到结尾 默认从左往右切 print(s6) 步长 语法:s[起始位置: 结束位置: 步长] s = "我是梅西,我很慌" s1 = s[1:5:2] # 从1开始, 到5结束, 每2个取1个 print(s1) s2 = s[::3] print(s2) s3 = s[6:2:-1] # - 表示反着来. 每两个取1个 print(s3) s = "这个标点符号很蛋疼" # s1 = s[7::-2] # print(s1) s2 = s[-1:-6:-2] print(s2)
4.2 字符串的相关操作?法
切记, 字符串是不可变的对象, 所以任何操作对原字符串是不会有任何影响的
1. ??写转来转去
s = "alex and wusir and taibai"
s1 = s.capitalize() # 首字母大写
print(s) # 原字符串不变
print(s1)
s = "Alex is not a Good Man. "
print(s.upper())
print(s.lower())
在程序需要判断不区分大小写的时候. 肯定能用上
while True:
content = input("请喷:")
if content.upper() == ‘Q‘:
break
print("你喷了:", content)
s = "taiBai HenBai feicahngBai"
print(s.swapcase()) # 大小写转换
s = "al麻花藤ex and wu sir sir se"
print(s.title())
2. 切来切去
s = "麻花藤"
print(s.center(9, "*"))
username = input("用户名:").strip() # 去掉空格.
password = input("密码:").strip() # 去掉空格
if username == ‘alex‘ and password == ‘123‘:
print("登录成功")
else:
print("登录失败")
s = "*******呵a呵呵呵****************"
print(s.strip("*")) # strip去掉的是左右两端的内容. 中间的不管
s = "alex wusir alex sb taibai"
s1 = s.replace("alex", "晓雪") # 原字符串不变
print(s1)
# 去掉上述字符串中的所有空格
s2 = s.replace(" ", "")
print(s2)
s3 = s.replace("alex", "sb", 2)
print(s3)
s = "alex_wuse_taibai_bubai"
lst = s.split("_taibai_") # 刀是_ 切完的东西是列表. 列表装的是字符串
print(lst)
3. 格式化输出
s = "我叫{}, 我今年{}岁了, 我喜欢{}".format("sylar", 18, "周杰伦的老婆")
print(s)
可以指定位置
s = "我叫{1}, 我今年{0}岁了, 我喜欢{2}".format("sylar", 18, "周杰伦的老婆")
print(s)
s = "我叫{name}, 我今年{age}岁了, 我喜欢{mingxing}".format(name="sylar", mingxing="汪峰的老婆", age=18)
print(s)
你喜欢用哪个就用哪个
4. 查找
s = "汪峰的老婆不爱汪峰"
print(s.startswith("汪峰")) # 判断字符串是否以xxx开头
print(s.endswith("爱妃")) # 判断字符串是否以xxx结尾
print(s.count("国际章")) # 计算xxx在字符串中出现的次数
print(s.find("汪峰", 3)) # 计算xxx字符串在原字符串中出现的位置, 如果没出现返回 -1
print(s.index("国际章")) # index中的内容如果不存在. 直接报错
5. 条件判断
s = "abc123" print(s.isdigit()) # 判断字符串是否由数字组成 print(s.isalpha()) # 是否由字母组成 print(s.isalnum()) # 是否由字母和数字组成 s = "二千136万萬" print(s.isnumeric()) # 数字
6. 计算字符串的?度
s = "你今天喝酒了么" i = len(s) # print() input() len() python的内置函数 print(i) i = s.__len__() # 也可以求长度 len()函数执行的时候实际执行的就是它 print(i)
注意: len()是python的内置函数. 所以访问?式也不?样. 你就记着len()和print()?样就? 了
7. 迭代
我们可以使?for循环来便利(获取)字符串中的每?个字符
语法:
for 变量 in 可迭代对象:
pass
可迭代对象: 可以?个?个往外取值的对象
#把字符串从头到尾进行遍历
s = "晓雪老师.你好漂亮"
print(len(s)) # 长度是:8 索引到7
#1. 使用while循环来进行遍历
count = 0
while count < len(s):
print(s[count])
count = count + 1
#2. 用for循环来遍历字符串
#优势:简单
#劣势:没有索引
for c in s: # 把s中的每一个字符交给前面的c 循环
print(c)
#语法:
#for bianliang in 可迭代对象:
#循环体
课后作业:
一.有变量name = "aleX leNb" 完成如下操作:
name = "aleX leNb"
#1)移除 name 变量对应的值两边的空格,并输出处理结果
s = name.strip()
print(s)
#2)移除name变量左边的"al"并输出处理结果
s = name.lstrip("al")
print(s)
#3)移除name变量右?的"Nb",并输出处理结果
s = name.rstrip("Nb")
print(s)
#4)移除name变量开头的a"与最后的"b",并输出处理结果
s = name.lstrip("a").rstrip("b")
print(s)
#5)判断 name 变量是否以 "al" 开头,并输出结果
s = name.startswith("al")
print(s)
#6)判断name变量是否以"Nb"结尾,并输出结果
s = name.endswith("Nb")
print(s)
#7)将 name 变量对应的值中的 所有的"l" 替换为 "p",并输出结果
s = name.replace("l","p")
print(s)
#8)将name变量对应的值中的第?个"l"替换成"p",并输出结果
s = name.replace("l","p",1)
print(s)
#9)将 name 变量对应的值根据 所有的"l" 分割,并输出结果。
s = name.split("l")
print(s)
#10)将name变量对应的值根据第?个"l"分割,并输出结果。
s = name.split("l",1)
print(s)
#11)将 name 变量对应的值变?写,并输出结果
s = name.upper()
print(s)
#12)将 name 变量对应的值变?写,并输出结果
s = name.lower()
print(s)
#13)将name变量对应的值?字?"a"?写,并输出结果
s = name.replace("a","A")
print(s)
#14)判断name变量对应的值字?"l"出现?次,并输出结果
s = name.count("l")
print(s)
#15)如果判断name变量对应的值前四位"l"出现?次,并输出结果
s = name[0:3].count("l")
print(s)
#16)从name变量对应的值中找到"N"对应的索引(如果找不到则报错),并输出结果
s = name.index("N")
print(s)
#17)从name变量对应的值中找到"N"对应的索引(如果找不到则返回-1)输出结果
s = name.find("N")
print(s)
#18)从name变量对应的值中找到"X le"对应的索引,并输出结果
s = name.find("X le")
print(s)
#19)请输出 name 变量对应的值的第 2 个字符?
print(name[2])
#20)请输出 name 变量对应的值的前 3 个字符?
print(name[0:3])
#21)请输出 name 变量对应的值的后 2 个字符?
print(name[-2:])
#22)请输出 name 变量对应的值中 "e" 所在索引位置?
s = name.find("e")
print(s)
二..有字符串s = "123a4b5c"
s = "123a4b5c"
#1)通过对s切?形成新的字符串s1,s1 = "123"
s1 = s.strip("a4b5c")
print(s1)
#2)通过对s切?形成新的字符串s2,s2 = "a4b"
s2 = s.lstrip("123").rstrip("5c")
print(s2)
#3)通过对s切?形成新的字符串s3,s3 = "1345"
s3 = s[0::2].strip("")
print(s3)
#4)通过对s切?形成字符串s4,s4 = "2ab"
s4 = s[1:6:2].strip("")
print(s4)
#5)通过对s切?形成字符串s5,s5 = "c"
s5 = s.strip("123ab45")
print(s5)
#6)通过对s切?形成字符串s6,s6 = "ba2"
s6 = s[-3:-8:-2].strip("")
print(s6)
三.使?while和for循环分别打印字符串s="asdfer"中每个元素。
#1.while循环打印
s = "asdfer"
count = 0
while count <= len(s) - 1:
print(s[count])
count = count +1
#2.for循环打印
s = "asdfer"
for a in s :
print(a)
四.使?for循环对s="asdfer"进?循环,但是每次打印的内容都是"asdfer"。
s = "asdfer" for a in s : print(s)
五.使?for循环对s="abcdefg"进?循环,每次打印的内容是每个字符加上sb,例如:asb, bsb,csb,...gsb。
s = "abcdefg"
for a in s :
print(a + "sb")
六.使?for循环对s="321"进?循环,打印的内容依次是:"倒计时3秒","倒计时
2秒","倒计时1秒","出发!"。
s = "321"
for a in s :
print("倒计时%s秒" % (a))
else:
print("出发!")
七,实现?个整数加法计算器(两个数相加):
如:content = input("请输?内容:") ?户输?:5+9或5+ 9或5 + 9,然后进
?分割再进?计算。
content = input("请输?内容:").strip()
s = content.split("+")
s2 = int(s[0])+int(s[1])
print(s2)
八,升级题:实现?个整数加法计算器(多个数相加):
如:content = input("请输?内容:") ?户输?:5+9+6 +12+ 13,然后进?
分割再进?计算。
content = input("请输?内容:").strip()
lis = content.split("+")
a1 =len(lis)
count = 0
sum = 0
while count < a1:
sum = sum + int(lis[count])
count = count + 1
print(sum)
九,计算?户输?的内容中有?个整数(以个位数为单位)。
如:content = input("请输?内容:") # 如fhdal234slfh98769fjdla
content = input("请输?内容:").strip()
count = 0
b = 0
while count < len(content):
c = content[count]
if c.isdigit():
b += 1
count += 1
print("输入的有%s个整数" % (b))
十.写代码,完成下列需求:
?户可持续输?(?while循环),?户使?的情况:
输?A,则显示??路回家,然后在让?户进?步选择:
是选择公交?,还是步??
选择公交?,显示10分钟到家,并退出整个程序。
选择步?,显示20分钟到家,并退出整个程序。
输?B,则显示??路回家,并退出整个程序。
输?C,则显示绕道回家,然后在让?户进?步选择:
是选择游戏厅玩会,还是?吧?
选择游戏厅,则显示 ‘?个半?时到家,爸爸在家,拿棍等你。’并让其
重新输?A,B,C选项。
选择?吧,则显示‘两个?时到家,妈妈已做好了战?准备。’并让其重
新输?A,B,C选项。
while True:
s = input("请输入A,B,C中的某一个:").upper()
if s == "A":
print("走大路回家")
s1 = input("选择公交车还是步行:")
if s1 == "步行":
print("20分钟到家")
break
if s1 == "公交车":
print("10分钟到家")
break
if s == "B":
print("走小路回家")
break
if s == "C":
while True:
print("绕道回家")
s2 = input("选择去游戏厅还是去网吧:")
if s2 == "游戏厅":
print("?个半?时到家,爸爸在家,拿棍等你。")
break
if s2 == "网吧":
print("两个?时到家,妈妈已做好了战?准备。")
break
十一.写代码:计算 1 - 2 + 3 ... + 99 中除了88以外所有数的总和?
count = 1
sum = 0
while count < 100:
if count == 88:
count += 1
continue
if count % 2 == 0:
sum = sum - count
else:
sum = sum + count
count = count + 1
print(sum)
十二. (升级题)判断?句话是否是回?. 回?: 正着念和反着念是?样的. 例如, 上海
?来?来?海上(升级题)
s = input("请输入一句话")
if s[::-1] == s:
print("是回文")
else:
print("不是回文")
十三. 输??个字符串,要求判断在这个字符串中?写字?,?写字?,数字,
其它字符共出现了多少次,并输出出来
s = input("请输入一句话")
upper_num = 0
lower_num = 0
num = 0
other = 0
for a in s:
if a.isupper():
upper_num += 1
elif a.islower():
lower_num += 1
elif a.isdigit():
num += 1
else:
other += 1
print("大写字母有%s个,小学字母有%s个,数字有%s个,其他有%s个" % (upper_num,lower_num,num,other))
十四、制作趣味模板程序需求:等待?户输?名字、地点、爱好,根据?户的名
字和爱好进?任意现实 如:敬爱可亲的xxx,最喜欢在xxx地??xxx
name = input("请输入你的名字:")
address = input("请输入地点:")
hobby = input("请输入爱好:")
print("敬爱可亲的{name},最喜欢在{address}地方干{hobby}".format(name=name,address=address,hobby=hobby))
标签:格式化输出 列表 运算 下标 dig 判断 ict 可迭代对象 选择
原文地址:https://www.cnblogs.com/python119/p/9439952.html