标签:目的 链表 eal __user 运行 for copy 实现 传递
用户进程栈的初始化在进程刚开始运行的时候,需要知道运行的环境和用户传递给进程的参数,因此Linux在用户进程运行前,将系统的环境变量和用户给的参数保存到用户虚拟地址空间的栈中,从栈基地址处开始存放。若排除栈基地址随机化的影响,在Linux64bit系统上用户栈的基地址是固定的:
在x86_64一般设置为0x0000_7FFF_FFFF_F000:
#define STACK_TOP_MAX TASK_SIZE_MAX
#define TASK_SIZE_MAX ((1UL << __VIRTUAL_MASK_SHIFT) - PAGE_SIZE)
#define __VIRTUAL_MASK_SHIFT 47在ARM64上是可以配置的,可以通过配置CONFIG_ARM64_VA_BITS的值决定栈的基地址:
#define STACK_TOP_MAX TASK_SIZE_64
#define TASK_SIZE_64 (UL(1) << VA_BITS)
#define VA_BITS (CONFIG_ARM64_VA_BITS)为了防止利用缓冲区溢出,Linux会对栈的基地址做随机化处理,在开启地址空间布局随机化(Address Space Layout Randomization,ASLR)后, 栈的基地址不是一个固定值。
在介绍Linux如何初始化用户程序栈之前有必要介绍一下虚拟内存区域(Virtual Memory Area, VMA)(还有一篇不错的中文博客), 因为栈也是通过vma管理的,在初始化栈之前会初始化一个用于管理栈的vma,在Linux上,vma用struct vm_area_struct描述,它描述的是一段连续的、具有相同访问属性的虚存空间,该虚存空间的大小为物理内存页面的整数倍, vm_area_struct 中比较重要的成员是vm_start和vm_end,它们分别保存了该虚存空间的首地址和末地址后第一个字节的地址,以字节为单位,所以虚存空间范围可以用[vm_start, vm_end)表示。
由于不同虚拟内存区域的属性不一样,所以一个进程的虚存空间需要多个vm_area_struct结构来描述。在vm_area_struct结构的数目较少的时候,各个vm_area_struct按照升序排序,以单链表的形式组织数据(通过vm_next指针指向下一个vm_area_struct结构)。但是当vm_area_struct结构的数据较多的时候,仍然采用链表组织的化,势必会影响到它的搜索速度。针对这个问题,Linux还使用了红黑树组织vm_area_struct,以提高其搜索速度。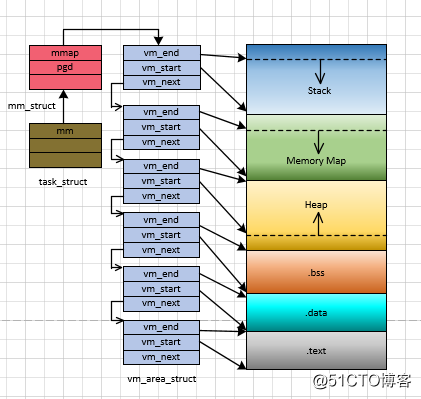
Linux 对栈的初始化在系统调用execve中完成,其主要目的有两个:
将传递给main()函数的参数压栈
用户栈的建立是伴随着可执行文件的加载建立的,Linux内核中使用linux_binprm管理加载的可执行文件,其定义如下:
struct linux_binprm {
char buf[BINPRM_BUF_SIZE];/*文件的头128字节,文件头*/
struct vm_area_struct *vma;/*用于存储环境变量和参数的空间*/
unsigned long vma_pages;/*vma中page的个数*/
struct mm_struct *mm;
unsigned long p; /* current top of mem,vma管理的内存的顶端 */
unsigned int recursion_depth; /* only for search_binary_handler() */
struct file * file;
struct cred *cred; /* new credentials */
int unsafe; /* how unsafe this exec is (mask of LSM_UNSAFE_*) */
unsigned int per_clear; /* bits to clear in current->personality */
int argc, envc; /*参数的数目和环境变量的数目*/
const char * filename; /* Name of binary as seen by procps */
const char * interp; /* Name of the binary really executed. Most
of the time same as filename, but could be different for binfmt_{misc,script} */
unsigned interp_flags;
unsigned interp_data;
unsigned long loader, exec;
struct rlimit rlim_stack; /* Saved RLIMIT_STACK used during exec. */
} __randomize_layout;SYSCALL_DEFINE3(execve,
const char __user *, filename, //可执行文件
const char __user *const __user *, argv,//命令行的参数
const char __user *const __user *, envp)//环境变量
{
return do_execve(getname(filename), argv, envp);
}int do_execve(struct filename *filename,
const char __user *const __user *__argv,
const char __user *const __user *__envp)
{
struct user_arg_ptr argv = { .ptr.native = __argv };
struct user_arg_ptr envp = { .ptr.native = __envp };
return do_execveat_common(AT_FDCWD, filename, argv, envp, 0);
}static int do_execveat_common(int fd, struct filename *filename,
struct user_arg_ptr argv,
struct user_arg_ptr envp,
int flags)
{
char *pathbuf = NULL;
struct linux_binprm *bprm;
struct file *file;
struct files_struct *displaced;
int retval;
bprm = kzalloc(sizeof(*bprm), GFP_KERNEL);
bprm->interp = bprm->filename;
retval = bprm_mm_init(bprm); //建立栈的vma
bprm->argc = count(argv, MAX_ARG_STRINGS);//传给main()函数的argc
if ((retval = bprm->argc) < 0)
goto out;
bprm->envc = count(envp, MAX_ARG_STRINGS); //envc
if ((retval = bprm->envc) < 0)
goto out;
retval = prepare_binprm(bprm);
if (retval < 0)
goto out;
retval = copy_strings_kernel(1, &bprm->filename, bprm);//复制文件名到vma
if (retval < 0)
goto out;
bprm->exec = bprm->p;
retval = copy_strings(bprm->envc, envp, bprm);//复制环境变量到vma
if (retval < 0)
goto out;
retval = copy_strings(bprm->argc, argv, bprm);//复制参数到vma
if (retval < 0)
goto out;
would_dump(bprm, bprm->file);
retval = exec_binprm(bprm); //执行可执行文件
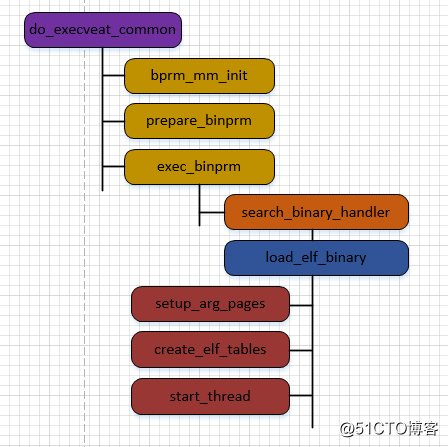
}通过对Linux代码的研究,用户进程栈的不是一步完成的,大致可以分为三步,一是需要linux建立一个vma用于管理用户栈,vma的建立主要是在bprm_mm_init中完成的,vma->vm_end设置为STACK_TOP_MAX,这时并没有栈随机化的参与,大小为一个PAGE_SIZE。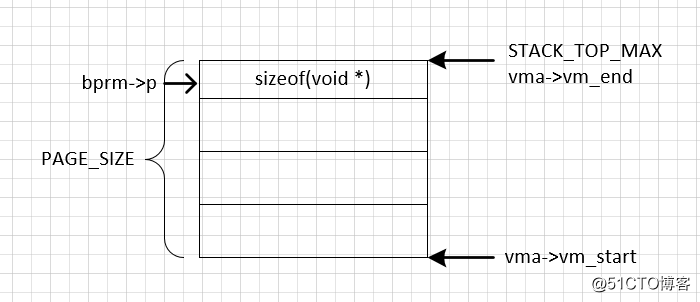
接着通过以下三个函数的调用分别把文件名,环境变量、参数复制到栈vma中,
retval = copy_strings_kernel(1, &bprm->filename, bprm);
if (retval < 0)
goto out;
bprm->exec = bprm->p;
retval = copy_strings(bprm->envc, envp, bprm);
if (retval < 0)
goto out;
retval = copy_strings(bprm->argc, argv, bprm);
if (retval < 0)
goto out;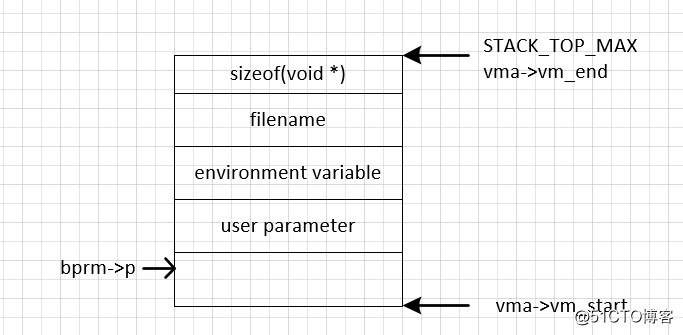
第三步主要是在exec_binprm->search_binary_handler->load_elf_binary->setup_arg_pages中完成的。这一步会对栈的基地址做随机化,并把已经建立起来vma栈复制到基地址随机化后的栈。
第四步 在函数create_elf_tables中完成,则是分别把argc,指向参数的指针,指向环境变量的指针,elf_info压栈。
比较重要的一步是start_thread(regs, elf_entry, bprm->p);启动用户进程,regs是当前CPU中寄存器的值,elf_entry是用户程序的进入点, bprm->p是用户程序的栈指针,根据这3个参数就可以运行一个新的用户进程了。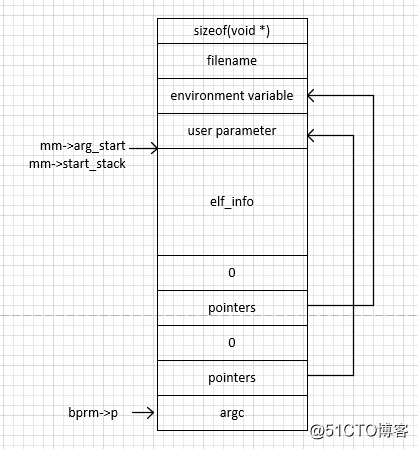
start_thread的实现是体系结构相关的,在x86-64上:
static void
start_thread_common(struct pt_regs *regs, unsigned long new_ip,
unsigned long new_sp,
unsigned int _cs, unsigned int _ss, unsigned int _ds)
{
WARN_ON_ONCE(regs != current_pt_regs());
if (static_cpu_has(X86_BUG_NULL_SEG)) {
/* Loading zero below won‘t clear the base. */
loadsegment(fs, __USER_DS);
load_gs_index(__USER_DS);
}
loadsegment(fs, 0);
loadsegment(es, _ds);
loadsegment(ds, _ds);
load_gs_index(0);
regs->ip = new_ip;
regs->sp = new_sp;
regs->cs = _cs;
regs->ss = _ss;
regs->flags = X86_EFLAGS_IF;
force_iret();
}
void
start_thread(struct pt_regs *regs, unsigned long new_ip, unsigned long new_sp)
{
start_thread_common(regs, new_ip, new_sp,
__USER_CS, __USER_DS, 0);
}在ARM64上:
static inline void start_thread_common(struct pt_regs *regs, unsigned long pc)
{
memset(regs, 0, sizeof(*regs));
forget_syscall(regs);
regs->pc = pc;
}
static inline void start_thread(struct pt_regs *regs, unsigned long pc,
unsigned long sp)
{
start_thread_common(regs, pc);
regs->pstate = PSR_MODE_EL0t;
regs->sp = sp;
}
不管是ARM64还是X86-64,都是将新的PC和SP复制给当前的current,然后一路路返回到do_execveat_common,从系统调用中断返回,因为current进程的pc和sp都已经被改变了,会从新的程序入口点elf_entry开始执行,栈也会从bprm->p开始,进程的全新的起点就开始了。新的起点一般不是我们常写的main函数,而是__start,__start就是elf_entry,其会执行一些初始化工作,最后才调用到main()函数。
X86-64和ARM64用户栈的结构 (2) ---进程用户栈的初始化
标签:目的 链表 eal __user 运行 for copy 实现 传递
原文地址:http://blog.51cto.com/iamokay/2155955