标签:规则 16进制 字母 day image 数字 证明 英文 内容
(一) is,==,id
(二) 代码块的含义
(三) 小数据池
(四) python编码之二
(一)代码块
python程序是有代码块组成的,块是一个python程序的文本,是作为一个单元的执行。
代码块:一个模块,一个函数,一个文件都是一个代码块。但是,在交互环境(终端环境)中,每输入的一个命令,每一行都是一个代码块。

而且在一个文件中的两个函数,也分别是不同的代码块:

(二) ==,id(),is
‘==’:用于判断两个对象的内容是否相等
#一个“ = ” 表示赋值表达式 name = ‘he‘ #“==” 表示数值内容的相同 print(‘he‘ == ‘he‘) >>> True name = ‘he‘ name1 = ‘alex‘ print(name == name1) >>>False
id() : 返回对象在内存当中的内存地址
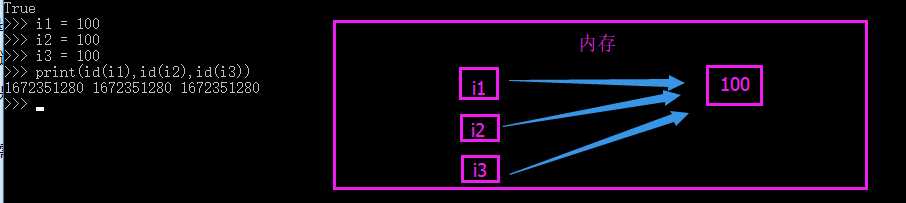
1.在内存中,id都是唯一的
2.如果两个变量指向的值的id相同,就证明他们在内存中是同一个。
name = ‘he‘ name1 = ‘he‘ print(id(name)) >>> 2101255303664 print(id(name1)) >>> 2101255303664
is : 判断两个值是否id(内存地址)相同
name = ‘he‘ name1 = ‘he‘ print(name1 is name) >>> True
# 结论:如果is为True,说明内存地址相同,那么值一定相同;如果值相同,内存地址未必相同。
(三)小数据池(缓存机制,驻留机制)
小数据池:又称为小整数缓存机制,驻留机制。
小数据池的前提:小数据池的数据类型只针对“整数,字符串,bool值”
概念:
小数据池是Python对内存做的一个优化,将-5~256的整数,以及一定规则的字符串,提前在内存中创建
了池,池里固定的放了这些数据。
优点:1. 节省内存
2. 提高性能和效率
int : -5~256的整数,如果多个变量同时指向这个范围内的整数,那么它们在内存中将指向同一个内存地址。
str:什么才是一定规则的字符串呢??
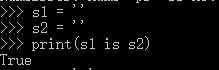
(1)当字符串的长度为0或者1时,默认采用小数据池驻留机制。
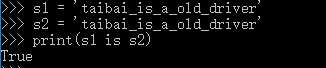
(2)当字符串的长度大于1时,如果只由英文字母,数字,下划线组成,默认采用小数据池驻留机制。
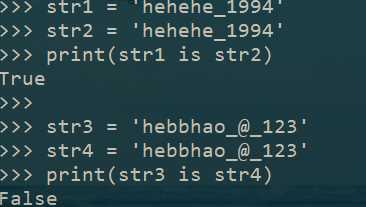
(3)用“*”得到的字符串,可以分为两种情况:
3.1 乘数为1,默认驻留

3.2 乘数为2,但字符串总长度小于20时,默认驻留
bool类型:bool值就是True,False,无论你创建多少个变量指向True,False,那么他在内存中只存在一个。
### 代码块与小数据池之间的关系 ####
# pycharm 通过运行文件的方式执行下列代码: i1 = 1000 i2 = 1000 print(i1 is i2) # 结果为True
通过交互方式中执行下面代码: >>> i1 = 1000 >>> i2 = 1000 >>> print(i1 is i2) False
为什么在pycharm与交互环境中,输出的结果会不同呢???这就牵涉到了代码块与小数据池之间的关系。
Python在同一个代码块中,初始化对象时,会把变量以及对应的值放置到内存的一个字典中(类似:dic={‘name‘ =‘he‘对应的内存地址}),如果下面代码再遇到对象的初始化赋值时,如果有相同的值,会去字典中寻找,然后直接复用,指向同一个内存地址。
Python在不同代码块中,初始化对象时,会遵循小数据池的原则。
参考上面关于代码块的概念,因为pycharm中一个py文件为一个代码块,而在交互文件中,不同的两行为不同的代码块,所以会出现上面的差异。
(四)python编码之二
编码之初的内容,看回之前的博客内容。
###########################################################################################
从之前的内容,我们可以得出以下结论:
(1)编码之间是不能相互识别的。
(2)因为unicode太过于浪费资源,所以在网络传输,本地存储,都必须不能够以unicode作为编码格式。
###########################################################################################
前提须知:
在python3.x版本中,字符串的编码为unicode,其他均为utf-8.
但是这样又存在了问题,那么字符串作为网络传输,本地存储的数据类型,编码类型为unicode,是不允许的。。那要怎么办?
于是此时,引出了有一个python中的基本数据类型bytes。bytes类型好比与str类型的双胞胎兄弟,str类型所有的方法,bytes类型都可以使用。
### bytes类型与str类型的区别?###
对于英文:
str:
表现形式: s1 = ‘hehehe‘
编码类型: unicode
bytes:
表现形式: b1 = b‘hehehe‘
编码类型: 非unicode
对于中文:
str:
表现形式: s1 = ‘呵呵呵‘
编码类型: unicode
bytes:
表现形式: b1 = b‘\xe5\x91\xb5\xe5\x91\xb5\xe5\x91\xb5‘
表现类型:非unicode
结论:
#为什么需要同时拥有str与bytes? 因为中文在bytes中的显示方式是16进制,不便于阅读。所以需要同时存在str与bytes #str类型和bytes类型如何使用? 在本地存储/网络socekt传输时,用bytes类型,因为字符串编码为unicode。其他用str类型
### bytes类型与str类型的转换?###
‘‘‘str与bytes的转换‘‘‘
str ----> bytes encode()编码
s1 = ‘alex‘
b1 = s1.encode(‘utf-8‘)
print(b1,type(b1))
#bytes ---->str decode()解码 b1 = b‘\xe5\x91\xb5\xe5\x91\xb5\xe5\x91\xb5‘ s1 = b1.decode(‘utf-8‘) print(s1) >>> 呵呵呵
标签:规则 16进制 字母 day image 数字 证明 英文 内容
原文地址:https://www.cnblogs.com/hebbhao/p/9449391.html