标签:错误 缓存 问题 cpu 调用 是你 color 修改 优化
先来看看这个关键字是什么意思:
volatile [?v?l?ta?l]
adj. 易变的,不稳定的;
从翻译上来看,volatile表示这个关键字是极易发生改变的。
volatile是java语言中,最轻量级的并发同步机制。这个关键字有如下两个作用:
1、任何对volatile变量的修改,java中的其他线程都可以感知到
2、volatile会禁止指令冲排序优化
在详细讲解volatile关键字之前,需要对java的内存模型有所理解,否则很难深入的认识到volatile的作用。java 内存可以像之前讲的那样,划分为堆、栈、方法区等等。但是从结合物理设备的角度来看,内存模型的布局设计如下:
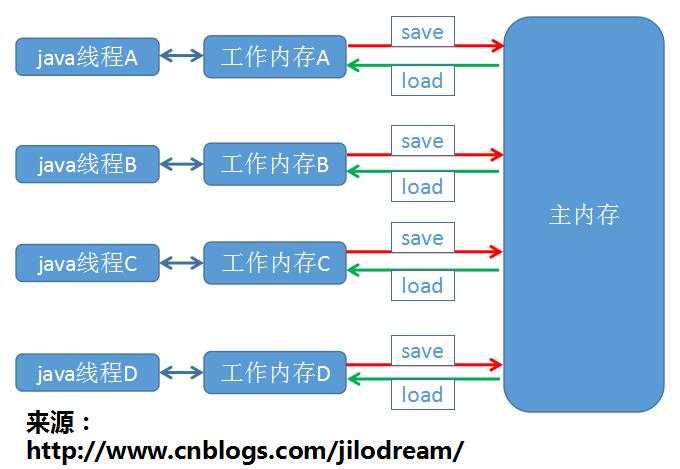
之所以这样设计内存模型,是因为:相对于cpu的处理速度来说,物理内存的IO操作耗时非常严重。这就造成了cpu线程快速计算结束后,需要浪费大量的时间来等待内存IO的操作。为了减少这种等待,java内存模型引入了工作内存的概念。工作内存主要是利用cpu或内存的寄存器、高速缓存等部分进行数据缓冲,减少cpu线程在内存IO期间的等待。
在java内存模型中,线程任何与数据有关的操作,都与并且只与工作内存相关。当线程需(防盗连接:本文首发自http://www.cnblogs.com/jilodream/ )要操作数据时,虚拟机会首先从主内存中读取数据,然后放置一份拷贝的数据到工作内存中。接着java线程读取工作内存中的拷贝数据,并操作得到一个全新的数据,然将将这个数据放回到工作内存中,覆盖原有的值。
这样做可以充分利用物理硬件的优势:
(1)主内存,存储区域大,但是速度不行,适于存储,不适于快速读写
(2)工作内存、存储空间小,但是速度快,适于快速读写,不适于存储
同时还避免了Java线程读写主内存中数据同步问题。因为主内存对于各个Java线程都是可见的。如果java线程并发操作,就会导致主内存中的数据需要进行同步保护,否则就会出现错误的语义。
但是这样做仍然会有一个问题:工作内存中的数据是拷贝数据。在Java线程操作的过程中,主内存中的数据可能已经发生改变,Java线程相当于是在用过时的值在计算和回写。这个问题就是数据称之为“同步”的含义所在,也是锁要处理的可见性的问题(以后有文章我会专门讲这个问题)。
如何解决这个问题呢?
只能是通过“锁”的形式来处理。volatile关键字的作用之一,就是形成这样一个“锁”:
如果一个变量被定义了volatile,那么每次Java线程在写入这个变量时,都会加入一个“lock addl $Ox0"的操作指令。这样会形成一个“内存屏障”,当cpu将这条指令写入到主内存时,会告诉其他存有这份指令的工作内存加一个标识。表示这个变量已经发生了变化,当前工作内存中存储的拷贝数据已经过时(这个过程被称之为内核CacheInvalidate)。当其他线程需要使用该变量来操作时,系统会因为这个标识判定当前工作内存中的数据已经过时。从而主动刷新主内存中的值到自己下边的工作内存中。由于在整个过程中,系统已经在线程操作数据之前,提前刷新了变量的值,所以线程无法看到已经过时的数据的。因此从表现上来看,可以认为是不存在数据不一致的问题。
这里需要专门强调下long、double型。对于内存模型中定义的指令来说,操作的数据都是32位的。如果数据是64位,那么就需要两次指令操作。对于虚拟机中64位数据类型:double、long型,就会因为需要两次操作的时间差,导致其他线程拿到的是一种修改的中间值。
但是volatile的内存屏障专门对这里进行了处理,以保证这种中间值不会出现在其他cpu的工作内存中。同时目前商业的虚拟机已经都对这个问题专门进行了处理:对64位数据的读写也采用原子操作。为的就是防止long double这两个常用类型,由于没有增加volatile关键字,而导致在工作内存中出现奇怪的值。
volatile的另外一个作用是禁止指令重排序的优化
cpu线程在执行指令的过程中,为了保证速度更快,指令之间的顺序往往是通过优化重排序以后的顺序。为了保证重排序的指令不会有任何的歧义而仅仅是在速度上有所提升,系统会保证指令优化以后执行的结果是一致的。也就是你所获得的结果与没优化获得到的结果是一样的,不存在差异。但是由于指令顺序发生了变化,所以系统是无法保证这个过程中,其他的线程获取到的数据是能正确代表当前状态的。这里最经典的就是单例模式下,实例初始化的问题。请参见文章:设计模式之单例模式 的第3个方法。
由于指令重排,系统会在变量没有初始化结束前,就已经给instance变量(防盗连接:本文首发自http://www.cnblogs.com/jilodream/ )赋予地址。这时候其他线程获取到的变量就是有问题的:instance!=null,但是里边的值却没有初始化完成。这里就需要使用volatile关键字禁止指令重排序:只有在实例初始化完毕后,才赋予变量instance引用。
另外一个常见的例子是:
线程B在刷新线程A的处理结果时,可能由于线程A还没有对变量初始化完毕,却提前刷新了变量,导致了线程B所获取到的变量的状态是错误的。
因此在定义多线程可见变量时,前边一定要加volatile关键字,保证该变量不会被因为指令顺序被优化,而导致其他线程获取到的值是无意义的。
关于Java语言的有序性在《深入理解Java虚拟机》中有一句话,总结的非常好:如果在本线程内观察,所有的操作都是有序的。如果在一个其它线程观察本线程,则所有的操作都是无序的。
前边是指,无论虚拟机怎么优化指令,当前线程在执行的语义和结果上都应该是一致的。(“线程内表现为串行的语义"Within-Thread-As-If-Serial-Semantics)。后边是指指令会发生重排,其它线程中获取到的值,不能代表什么。
其实volatile的这两个作用是互相关联的:正是由于volatile需要保证变量的可见性,因此不能将系统无序的中间指令结果反映到主内存中,让其它线程拿去使用可见,所以需要禁止掉指令重排序。保证拿到的结果是反映出当前的执行状态的。(这里涉及到一个happens-before原则的概念,我会在后边的文章中介绍)
volatile存在的问题
说了volatile的两个作用,volatile也有自身的不足。那就是volatile不能保证原子性:
举个前文讲过的例子,volatile变量值被修改以后,会直接刷新到主内存中,并且其他线程能感知到。但是其他线程继续使用这个变量进行计算时,却不能保证其一直是最新的值。举个经典例子
1 volatile int a=0; 2 int add() 3 { 4 a++; 5 }
两个线程t1,t2先后执行add)方法,变量a发生了自增。但是a变量的最终结果可能是1也可能是2。这取决于t2读取变量a的值是在第一个线程刷新a到主内存之前,还是主内存之后。
a++操作最终在执行时,会执行三条指令:
1、从主内存中读取a值
2、a=a+1
3、写入a的值到主内存中
当t1执行完第二步时,假如此时t2也读取了a的值,则:主内存a=0;t1工作内存为a=1;t2工作内存为a=0;接下来t1执行回写a操作,但是t2由于已经读取了a的值在工作内存中,因此t2在执行了a++操作后,仍然会回写a=1到主内存中,这时尽管t1回写后,生成内存屏障,但是t2已经读取完毕,不会在自增阶段再主动刷新。(防盗连接:本文首发自http://www.cnblogs.com/jilodream/ )否则如果需要执行连续的多条指令,每次都要主动刷新变量,一旦发生变化就重头开始,这显然是不可能的。这种情况就需要程序员通过代码自己来保证没有问题。
这里我们可以发现a变量不会因为volatile关键字,而使得自身的指令在外界看来是原子的。
因此volatile的使用存在如下限制场景:
1、volatile可以写入,但是写入的值不应该依赖旧值
2、在确认某个状态的不变性时,不能将volatile变量作为因子。
这两点在《java并发编程实战》、《深入理解java虚拟机》中都有提到类似的语义。第一点比较容易理解。第二点比较抽象,这里解释一下:就是说volatile适合于判断是否已经改变了,而不适合判断是否还没改变,因为volatile变量发生改变,则一定发生了变化,volatile没有发生变化,则不能说明一定没有发生变化。
如前文,a如果仍然等于0.此时不能认为:1、add方法没有被调用过2、整体没有被改变过。
标签:错误 缓存 问题 cpu 调用 是你 color 修改 优化
原文地址:https://www.cnblogs.com/jilodream/p/9452391.html