标签:src tin img pytho open image mozilla www hide

#!/usr/bin/evn python3 import requests import re class crawler(object): #发起请求 def request(self,page): headers = { ‘Host‘: ‘www.xiaohuar.com‘, ‘Cookie‘:‘__51cke__ =;Hm_lvt_0dfa94cc970f5368ddbe743609970944 = 1533890508;bdshare_firstime = 1533890520508;Hm_lpvt_0dfa94cc970f5368ddbe743609970944 = 1533891345;__tins__17172513 = % 7B % 22sid % 22 % 3A % 201533890507945 % 2C % 20 % 22vd % 22 % 3A % 208 % 2C % 20 % 22expires % 22 % 3A % 201533893209290 % 7 D;__51laig__ = 8‘, ‘user-agent‘:‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.79 Safari/537.36‘ } html = requests.get(‘http://www.xiaohuar.com/list-1-%d.html‘ %page,headers=headers) print("正在爬.........") print(html.url) now = re.sub(r‘src="‘,‘src="http://www.xiaohuar.com‘,html.text) return now # 正则匹配 def getImages(self,html): img = re.compile(r‘(<img.+?src=".+?" />)‘); url = re.findall(img, html) return url crawler = crawler() html = crawler.request(1) # print(html) a = crawler.getImages(html) for i in a: print(i)
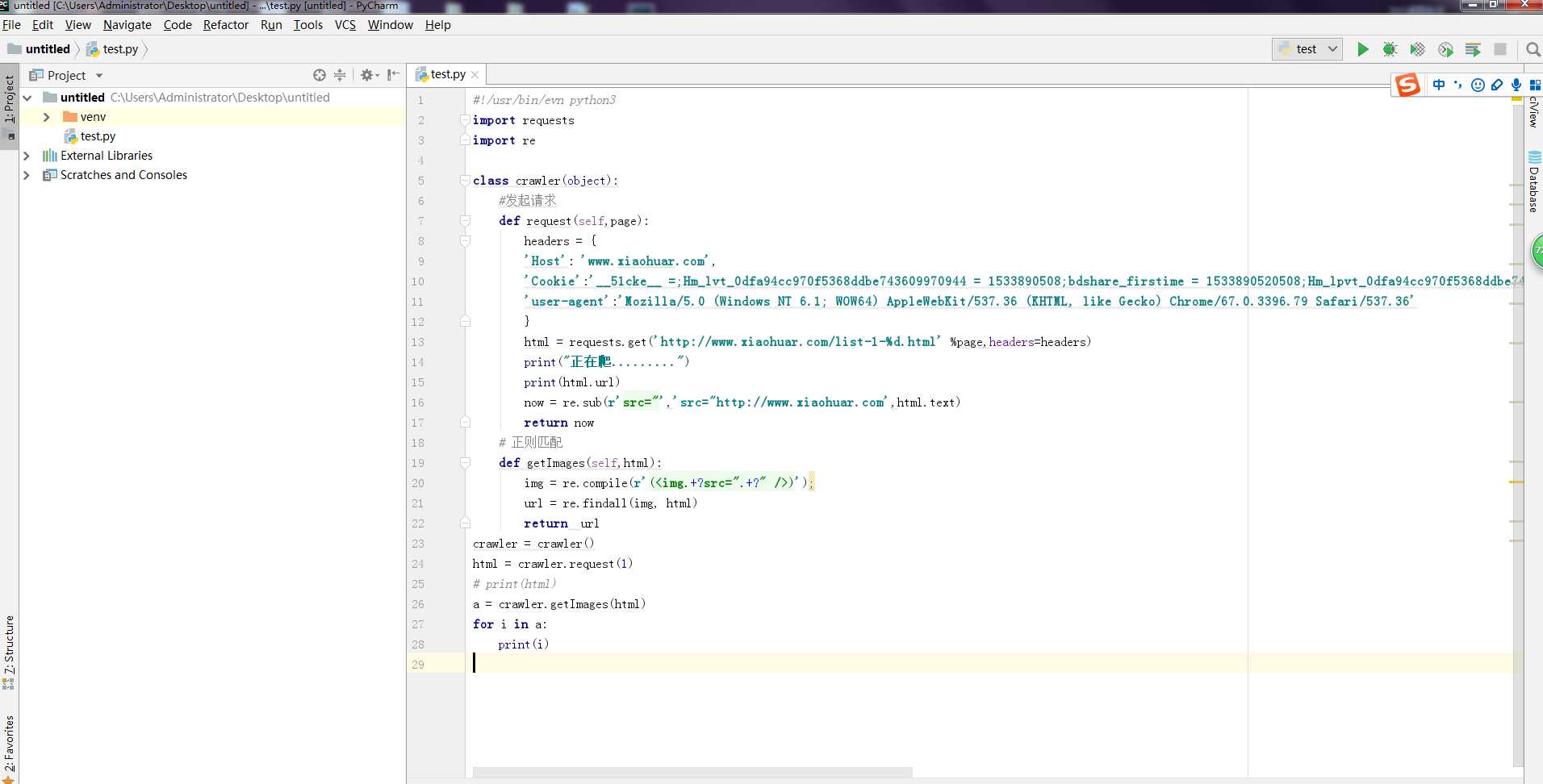
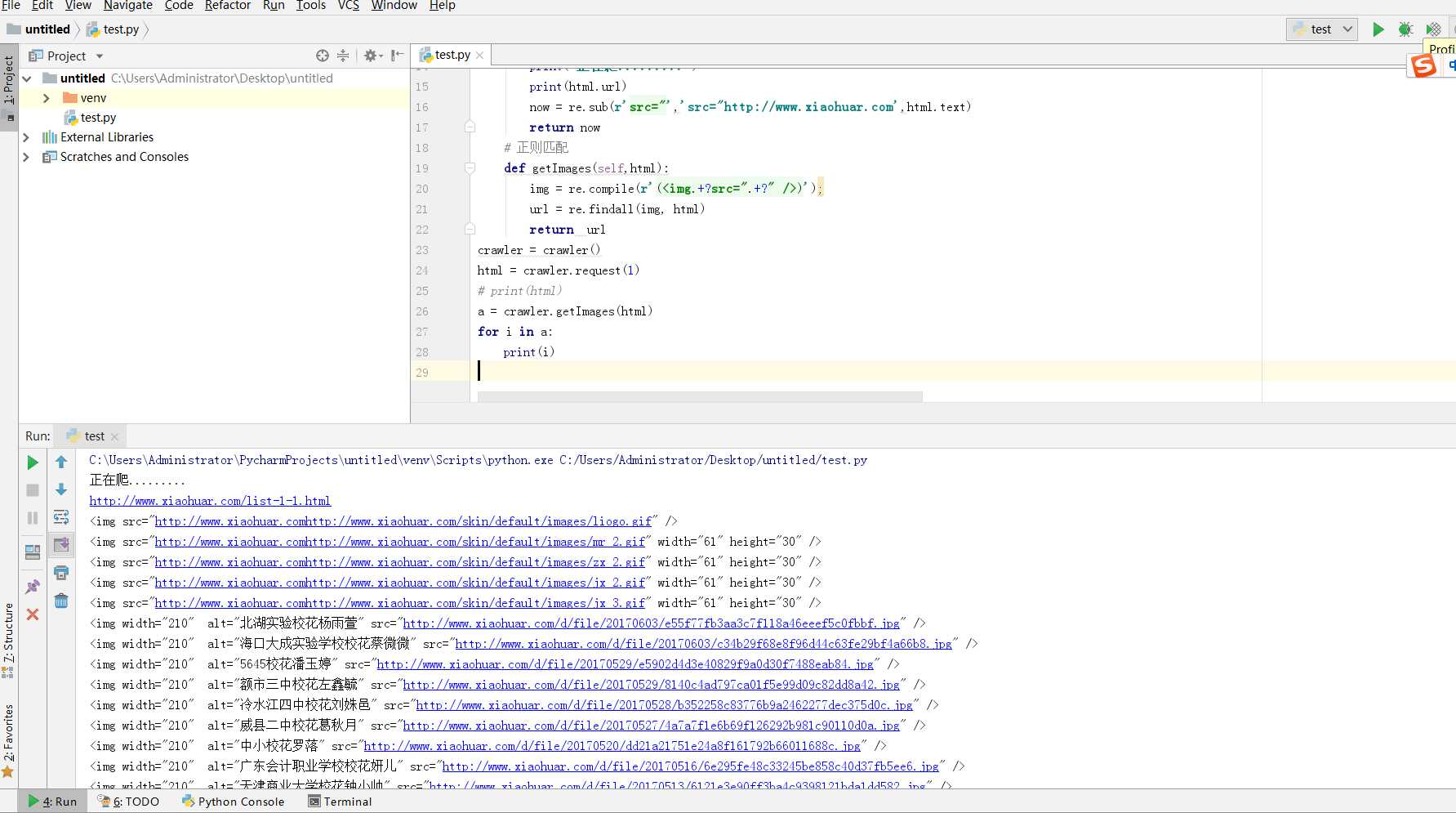
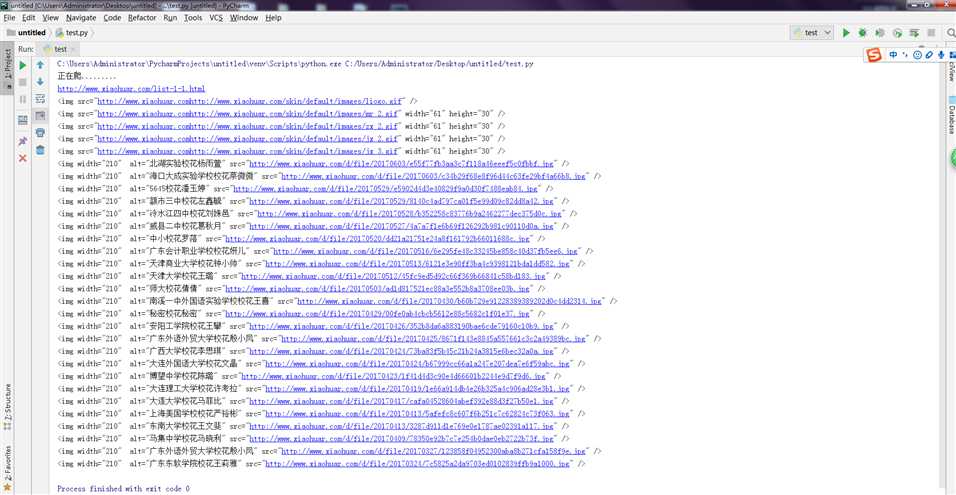

需要pip install requests
标签:src tin img pytho open image mozilla www hide
原文地址:https://www.cnblogs.com/ashton/p/9456583.html
